 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAND: Boosting LLM Agents with Self-Taught Action Deliberation
Jul 10, 2025Large Language Model (LLM) agents are commonly tuned with supervised finetuning on ReAct-style expert trajectories or preference optimization over pairwise rollouts. Most of these methods focus on imitating specific expert behaviors or promoting chosen reasoning thoughts and actions over rejected ones. However, without reasoning and comparing over alternatives actions, LLM agents finetuned with these methods may over-commit towards seemingly plausible but suboptimal actions due to limited action space exploration. To address this, in this paper we propose Self-taught ActioN Deliberation (SAND) framework, enabling LLM agents to explicitly deliberate over candidate actions before committing to one. To tackle the challenges of when and what to deliberate given large action space and step-level action evaluation, we incorporate self-consistency action sampling and execution-guided action critique to help synthesize step-wise action deliberation thoughts using the base model of the LLM agent. In an iterative manner, the deliberation trajectories are then used to finetune the LLM agent itself. Evaluating on two representative interactive agent tasks, SAND achieves an average 20% improvement over initial supervised finetuning and also outperforms state-of-the-art agent tuning approaches.
Video-Guided Text-to-Music Generation Using Public Domain Movie Collections
Jun 14, 2025Despite recent advancements in music generation systems, their application in film production remains limited, as they struggle to capture the nuances of real-world filmmaking, where filmmakers consider multiple factors-such as visual content, dialogue, and emotional tone-when selecting or composing music for a scene. This limitation primarily stems from the absence of comprehensive datasets that integrate these elements. To address this gap, we introduce Open Screen Sound Library (OSSL), a dataset consisting of movie clips from public domain films, totaling approximately 36.5 hours, paired with high-quality soundtracks and human-annotated mood information. To demonstrate the effectiveness of our dataset in improving the performance of pre-trained models on film music generation tasks, we introduce a new video adapter that enhances an autoregressive transformer-based text-to-music model by adding video-based conditioning. Our experimental results demonstrate that our proposed approach effectively enhances MusicGen-Medium in terms of both objective measures of distributional and paired fidelity, and subjective compatibility in mood and genre. The dataset and code are available at https://havenpersona.github.io/ossl-v1.
Generating Long Semantic IDs in Parallel for Recommendation
Jun 06, 2025Semantic ID-based recommendation models tokenize each item into a small number of discrete tokens that preserve specific semantics, leading to better performance, scalability, and memory efficiency. While recent models adopt a generative approach, they often suffer from inefficient inference due to the reliance on resource-intensive beam search and multiple forward passes through the neural sequence model. As a result, the length of semantic IDs is typically restricted (e.g. to just 4 tokens), limiting their expressiveness. To address these challenges, we propose RPG, a lightweight framework for semantic ID-based recommendation. The key idea is to produce unordered, long semantic IDs, allowing the model to predict all tokens in parallel. We train the model to predict each token independently using a multi-token prediction loss, directly integrating semantics into the learning objective. During inference, we construct a graph connecting similar semantic IDs and guide decoding to avoid generating invalid IDs. Experiments show that scaling up semantic ID length to 64 enables RPG to outperform generative baselines by an average of 12.6% on the NDCG@10, while also improving inference efficiency. Code is available at: https://github.com/facebookresearch/RPG_KDD2025.
REGen: Multimodal Retrieval-Embedded Generation for Long-to-Short Video Editing
May 24, 2025Short videos are an effective tool for promoting contents and improving knowledge accessibility. While existing extractive video summarization methods struggle to produce a coherent narrative, existing abstractive methods cannot `quote' from the input videos, i.e., inserting short video clips in their outputs. In this work, we explore novel video editing models for generating shorts that feature a coherent narrative with embedded video insertions extracted from a long input video. We propose a novel retrieval-embedded generation framework that allows a large language model to quote multimodal resources while maintaining a coherent narrative. Our proposed REGen system first generates the output story script with quote placeholders using a finetuned large language model, and then uses a novel retrieval model to replace the quote placeholders by selecting a video clip that best supports the narrative from a pool of candidate quotable video clips. We examine the proposed method on the task of documentary teaser generation, where short interview insertions are commonly used to support the narrative of a documentary. Our objective evaluations show that the proposed method can effectively insert short video clips while maintaining a coherent narrative. In a subjective survey, we show that our proposed method outperforms existing abstractive and extractive approaches in terms of coherence, alignment, and realism in teaser generation.
GSPRec: Temporal-Aware Graph Spectral Filtering for Recommendation
May 15, 2025Graph-based recommendation systems are effective at modeling collaborative patterns but often suffer from two limitations: overreliance on low-pass filtering, which suppresses user-specific signals, and omission of sequential dynamics in graph construction. We introduce GSPRec, a graph spectral model that integrates temporal transitions through sequentially-informed graph construction and applies frequency-aware filtering in the spectral domain. GSPRec encodes item transitions via multi-hop diffusion to enable the use of symmetric Laplacians for spectral processing. To capture user preferences, we design a dual-filtering mechanism: a Gaussian bandpass filter to extract mid-frequency, user-level patterns, and a low-pass filter to retain global trends. Extensive experiments on four public datasets show that GSPRec consistently outperforms baselines, with an average improvement of 6.77% in NDCG@10. Ablation studies show the complementary benefits of both sequential graph augmentation and bandpass filtering.
Fast Text-to-Audio Generation with Adversarial Post-Training
May 14, 2025Text-to-audio systems, while increasingly performant, are slow at inference time, thus making their latency unpractical for many creative applications. We present Adversarial Relativistic-Contrastive (ARC) post-training, the first adversarial acceleration algorithm for diffusion/flow models not based on distillation. While past adversarial post-training methods have struggled to compare against their expensive distillation counterparts, ARC post-training is a simple procedure that (1) extends a recent relativistic adversarial formulation to diffusion/flow post-training and (2) combines it with a novel contrastive discriminator objective to encourage better prompt adherence. We pair ARC post-training with a number optimizations to Stable Audio Open and build a model capable of generating $\approx$12s of 44.1kHz stereo audio in $\approx$75ms on an H100, and $\approx$7s on a mobile edge-device, the fastest text-to-audio model to our knowledge.
CachePrune: Neural-Based Attribution Defense Against Indirect Prompt Injection Attacks
Apr 29, 2025Large Language Models (LLMs) are identified as being susceptible to indirect prompt injection attack, where the model undesirably deviates from user-provided instructions by executing tasks injected in the prompt context. This vulnerability stems from LLMs' inability to distinguish between data and instructions within a prompt. In this paper, we propose CachePrune that defends against this attack by identifying and pruning task-triggering neurons from the KV cache of the input prompt context. By pruning such neurons, we encourage the LLM to treat the text spans of input prompt context as only pure data, instead of any indicator of instruction following. These neurons are identified via feature attribution with a loss function induced from an upperbound of the Direct Preference Optimization (DPO) objective. We show that such a loss function enables effective feature attribution with only a few samples. We further improve on the quality of feature attribution, by exploiting an observed triggering effect in instruction following. Our approach does not impose any formatting on the original prompt or introduce extra test-time LLM calls. Experiments show that CachePrune significantly reduces attack success rates without compromising the response quality. Note: This paper aims to defend against indirect prompt injection attacks, with the goal of developing more secure and robust AI systems.
Symbolic Representation for Any-to-Any Generative Tasks
Apr 24, 2025

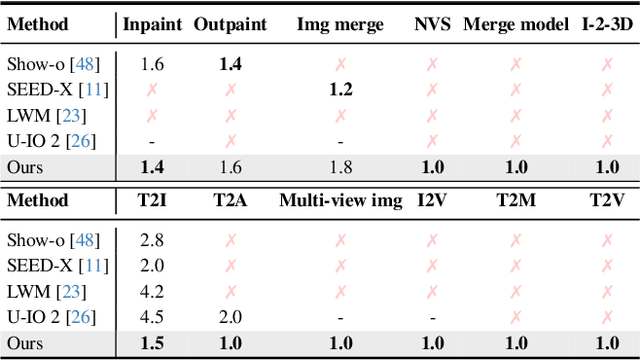

We propose a symbolic generative task description language and a corresponding inference engine capable of representing arbitrary multimodal tasks as structured symbolic flows. Unlike conventional generative models that rely on large-scale training and implicit neural representations to learn cross-modal mappings, often at high computational cost and with limited flexibility, our framework introduces an explicit symbolic representation comprising three core primitives: functions, parameters, and topological logic. Leveraging a pre-trained language model, our inference engine maps natural language instructions directly to symbolic workflows in a training-free manner. Our framework successfully performs over 12 diverse multimodal generative tasks, demonstrating strong performance and flexibility without the need for task-specific tuning. Experiments show that our method not only matches or outperforms existing state-of-the-art unified models in content quality, but also offers greater efficiency, editability, and interruptibility. We believe that symbolic task representations provide a cost-effective and extensible foundation for advancing the capabilities of generative AI.
From Reviews to Dialogues: Active Synthesis for Zero-Shot LLM-based Conversational Recommender System
Apr 21, 2025



Conversational recommender systems (CRS) typically require extensive domain-specific conversational datasets, yet high costs, privacy concerns, and data-collection challenges severely limit their availability. Although Large Language Models (LLMs) demonstrate strong zero-shot recommendation capabilities, practical applications often favor smaller, internally managed recommender models due to scalability, interpretability, and data privacy constraints, especially in sensitive or rapidly evolving domains. However, training these smaller models effectively still demands substantial domain-specific conversational data, which remains challenging to obtain. To address these limitations, we propose an active data augmentation framework that synthesizes conversational training data by leveraging black-box LLMs guided by active learning techniques. Specifically, our method utilizes publicly available non-conversational domain data, including item metadata, user reviews, and collaborative signals, as seed inputs. By employing active learning strategies to select the most informative seed samples, our approach efficiently guides LLMs to generate synthetic, semantically coherent conversational interactions tailored explicitly to the target domain. Extensive experiments validate that conversational data generated by our proposed framework significantly improves the performance of LLM-based CRS models, effectively addressing the challenges of building CRS in no- or low-resource scenarios.
In-context Ranking Preference Optimization
Apr 21, 2025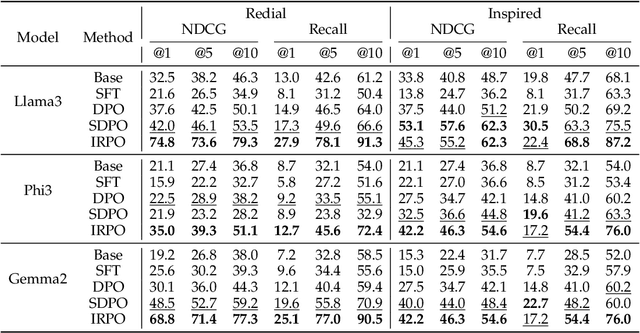
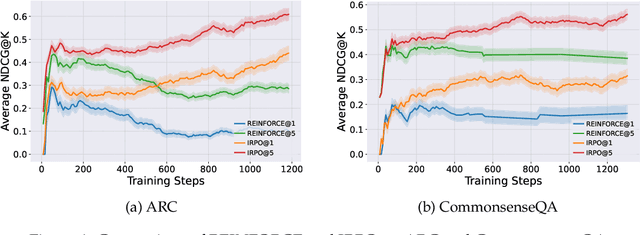
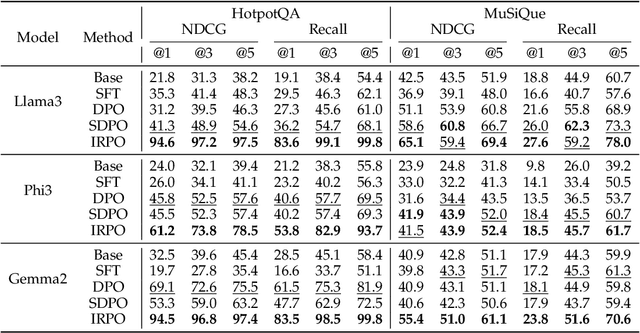
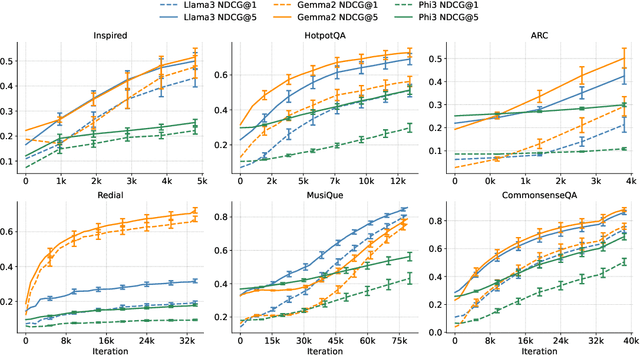
Recent developments in Direct Preference Optimization (DPO) allow large language models (LLMs) to function as implicit ranking models by maximizing the margin between preferred and non-preferred responses. In practice, user feedback on such lists typically involves identifying a few relevant items in context rather than providing detailed pairwise comparisons for every possible item pair. Moreover, many complex information retrieval tasks, such as conversational agents and summarization systems, critically depend on ranking the highest-quality outputs at the top, emphasizing the need to support natural and flexible forms of user feedback. To address the challenge of limited and sparse pairwise feedback in the in-context setting, we propose an In-context Ranking Preference Optimization (IRPO) framework that directly optimizes LLMs based on ranking lists constructed during inference. To further capture flexible forms of feedback, IRPO extends the DPO objective by incorporating both the relevance of items and their positions in the list. Modeling these aspects jointly is non-trivial, as ranking metrics are inherently discrete and non-differentiable, making direct optimization difficult. To overcome this, IRPO introduces a differentiable objective based on positional aggregation of pairwise item preferences, enabling effective gradient-based optimization of discrete ranking metrics. We further provide theoretical insights showing that IRPO (i) automatically emphasizes items with greater disagreement between the model and the reference ranking, and (ii) links its gradient to an importance sampling estimator, yielding an unbiased estimator with reduced variance. Empirical results show IRPO outperforms standard DPO approaches in ranking performance, highlighting its effectiveness in aligning LLMs with direct in-context ranking preferences.