 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposer Vector: Style-steering Symbolic Music Generation in a Latent Space
Apr 03, 2026Symbolic music generation has made significant progress, yet achieving fine-grained and flexible control over composer style remains challenging. Existing training-based methods for composer style conditioning depend on large labeled datasets. Besides, these methods typically support only single-composer generation at a time, limiting their applicability to more creative or blended scenarios. In this work, we propose Composer Vector, an inference-time steering method that operates directly in the model's latent space to control composer style without retraining. Through experiments on multiple symbolic music generation models, we show that Composer Vector effectively guides generations toward target composer styles, enabling smooth and interpretable control through a continuous steering coefficient. It also enables seamless fusion of multiple styles within a unified latent space framework. Overall, our work demonstrates that simple latent space steering provides a practical and general mechanism for controllable symbolic music generation, enabling more flexible and interactive creative workflows. Code and Demo are available here: https://github.com/JiangXunyi/Composer-Vector and https://jiangxunyi.github.io/composervector.github.io/
REGen: Multimodal Retrieval-Embedded Generation for Long-to-Short Video Editing
May 24, 2025Short videos are an effective tool for promoting contents and improving knowledge accessibility. While existing extractive video summarization methods struggle to produce a coherent narrative, existing abstractive methods cannot `quote' from the input videos, i.e., inserting short video clips in their outputs. In this work, we explore novel video editing models for generating shorts that feature a coherent narrative with embedded video insertions extracted from a long input video. We propose a novel retrieval-embedded generation framework that allows a large language model to quote multimodal resources while maintaining a coherent narrative. Our proposed REGen system first generates the output story script with quote placeholders using a finetuned large language model, and then uses a novel retrieval model to replace the quote placeholders by selecting a video clip that best supports the narrative from a pool of candidate quotable video clips. We examine the proposed method on the task of documentary teaser generation, where short interview insertions are commonly used to support the narrative of a documentary. Our objective evaluations show that the proposed method can effectively insert short video clips while maintaining a coherent narrative. In a subjective survey, we show that our proposed method outperforms existing abstractive and extractive approaches in terms of coherence, alignment, and realism in teaser generation.
Emotion-driven Piano Music Generation via Two-stage Disentanglement and Functional Representation
Jul 30, 2024Managing the emotional aspect remains a challenge in automatic music generation. Prior works aim to learn various emotions at once, leading to inadequate modeling. This paper explores the disentanglement of emotions in piano performance generation through a two-stage framework. The first stage focuses on valence modeling of lead sheet, and the second stage addresses arousal modeling by introducing performance-level attributes. To further capture features that shape valence, an aspect less explored by previous approaches, we introduce a novel functional representation of symbolic music. This representation aims to capture the emotional impact of major-minor tonality, as well as the interactions among notes, chords, and key signatures. Objective and subjective experiments validate the effectiveness of our framework in both emotional valence and arousal modeling. We further leverage our framework in a novel application of emotional controls, showing a broad potential in emotion-driven music generation.
Emotion-Driven Melody Harmonization via Melodic Variation and Functional Representation
Jul 29, 2024Emotion-driven melody harmonization aims to generate diverse harmonies for a single melody to convey desired emotions. Previous research found it hard to alter the perceived emotional valence of lead sheets only by harmonizing the same melody with different chords, which may be attributed to the constraints imposed by the melody itself and the limitation of existing music representation. In this paper, we propose a novel functional representation for symbolic music. This new method takes musical keys into account, recognizing their significant role in shaping music's emotional character through major-minor tonality. It also allows for melodic variation with respect to keys and addresses the problem of data scarcity for better emotion modeling. A Transformer is employed to harmonize key-adaptable melodies, allowing for keys determined in rule-based or model-based manner. Experimental results confirm the effectiveness of our new representation in generating key-aware harmonies, with objective and subjective evaluations affirming the potential of our approach to convey specific valence for versatile melody.
Generative Entity Typing with Curriculum Learning
Oct 06, 2022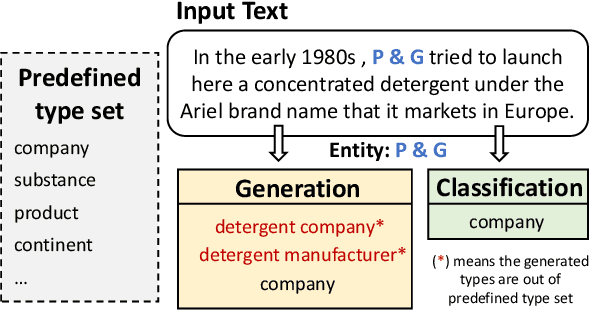
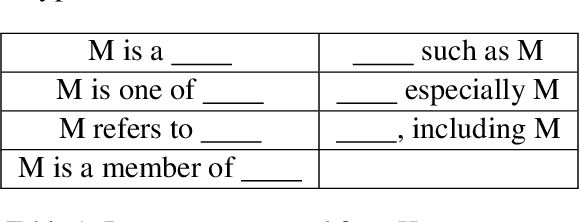
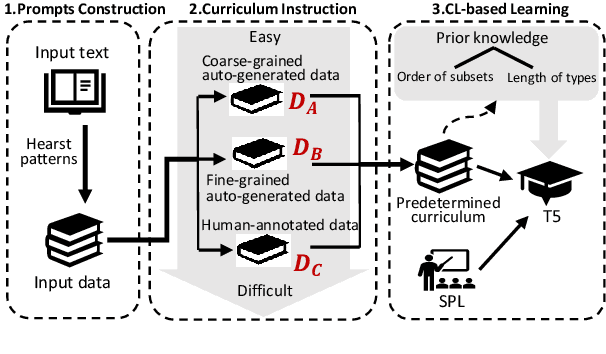

Entity typing aims to assign types to the entity mentions in given texts. The traditional classification-based entity typing paradigm has two unignorable drawbacks: 1) it fails to assign an entity to the types beyond the predefined type set, and 2) it can hardly handle few-shot and zero-shot situations where many long-tail types only have few or even no training instances. To overcome these drawbacks, we propose a novel generative entity typing (GET) paradigm: given a text with an entity mention, the multiple types for the role that the entity plays in the text are generated with a pre-trained language model (PLM). However, PLMs tend to generate coarse-grained types after fine-tuning upon the entity typing dataset. Besides, we only have heterogeneous training data consisting of a small portion of human-annotated data and a large portion of auto-generated but low-quality data. To tackle these problems, we employ curriculum learning (CL) to train our GET model upon the heterogeneous data, where the curriculum could be self-adjusted with the self-paced learning according to its comprehension of the type granularity and data heterogeneity. Our extensive experiments upon the datasets of different languages and downstream tasks justify the superiority of our GET model over the state-of-the-art entity typing models. The code has been released on https://github.com/siyuyuan/GET.
Large-scale Multi-granular Concept Extraction Based on Machine Reading Comprehension
Aug 30, 2022The concepts in knowledge graphs (KGs) enable machines to understand natural language, and thus play an indispensable role in many applications. However, existing KGs have the poor coverage of concepts, especially fine-grained concepts. In order to supply existing KGs with more fine-grained and new concepts, we propose a novel concept extraction framework, namely MRC-CE, to extract large-scale multi-granular concepts from the descriptive texts of entities. Specifically, MRC-CE is built with a machine reading comprehension model based on BERT, which can extract more fine-grained concepts with a pointer network. Furthermore, a random forest and rule-based pruning are also adopted to enhance MRC-CE's precision and recall simultaneously. Our experiments evaluated upon multilingual KGs, i.e., English Probase and Chinese CN-DBpedia, justify MRC-CE's superiority over the state-of-the-art extraction models in KG completion. Particularly, after running MRC-CE for each entity in CN-DBpedia, more than 7,053,900 new concepts (instanceOf relations) are supplied into the KG. The code and datasets have been released at https://github.com/fcihraeipnusnacwh/MRC-CE