 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Guidance for Controllable Latent Audio Diffusion
Mar 04, 2026Generative audio requires fine-grained controllable outputs, yet most existing methods require model retraining on specific controls or inference-time controls (\textit{e.g.}, guidance) that can also be computationally demanding. By examining the bottlenecks of existing guidance-based controls, in particular their high cost-per-step due to decoder backpropagation, we introduce a guidance-based approach through selective TFG and Latent-Control Heads (LatCHs), which enables controlling latent audio diffusion models with low computational overhead. LatCHs operate directly in latent space, avoiding the expensive decoder step, and requiring minimal training resources (7M parameters and $\approx$ 4 hours of training). Experiments with Stable Audio Open demonstrate effective control over intensity, pitch, and beats (and a combination of those) while maintaining generation quality. Our method balances precision and audio fidelity with far lower computational costs than standard end-to-end guidance. Demo examples can be found at https://zacharynovack.github.io/latch/latch.html.
Foley Control: Aligning a Frozen Latent Text-to-Audio Model to Video
Oct 24, 2025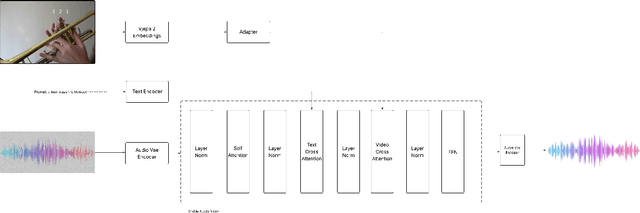
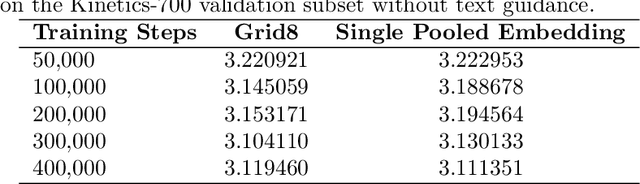
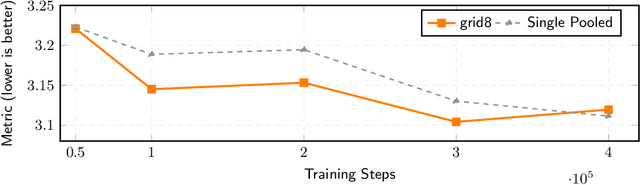

Foley Control is a lightweight approach to video-guided Foley that keeps pretrained single-modality models frozen and learns only a small cross-attention bridge between them. We connect V-JEPA2 video embeddings to a frozen Stable Audio Open DiT text-to-audio (T2A) model by inserting compact video cross-attention after the model's existing text cross-attention, so prompts set global semantics while video refines timing and local dynamics. The frozen backbones retain strong marginals (video; audio given text) and the bridge learns the audio-video dependency needed for synchronization -- without retraining the audio prior. To cut memory and stabilize training, we pool video tokens before conditioning. On curated video-audio benchmarks, Foley Control delivers competitive temporal and semantic alignment with far fewer trainable parameters than recent multi-modal systems, while preserving prompt-driven controllability and production-friendly modularity (swap/upgrade encoders or the T2A backbone without end-to-end retraining). Although we focus on Video-to-Foley, the same bridge design can potentially extend to other audio modalities (e.g., speech).
Fast Text-to-Audio Generation with Adversarial Post-Training
May 14, 2025Text-to-audio systems, while increasingly performant, are slow at inference time, thus making their latency unpractical for many creative applications. We present Adversarial Relativistic-Contrastive (ARC) post-training, the first adversarial acceleration algorithm for diffusion/flow models not based on distillation. While past adversarial post-training methods have struggled to compare against their expensive distillation counterparts, ARC post-training is a simple procedure that (1) extends a recent relativistic adversarial formulation to diffusion/flow post-training and (2) combines it with a novel contrastive discriminator objective to encourage better prompt adherence. We pair ARC post-training with a number optimizations to Stable Audio Open and build a model capable of generating $\approx$12s of 44.1kHz stereo audio in $\approx$75ms on an H100, and $\approx$7s on a mobile edge-device, the fastest text-to-audio model to our knowledge.