 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUV Volumes for Real-time Rendering of Editable Free-view Human Performance
Mar 27, 2022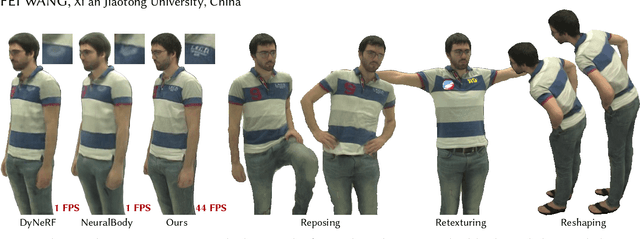
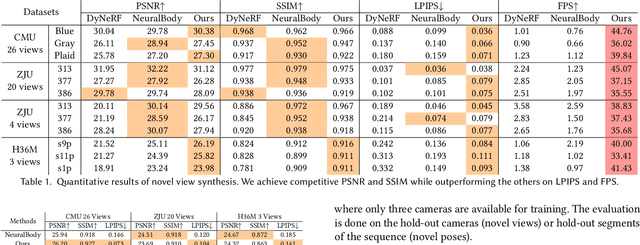
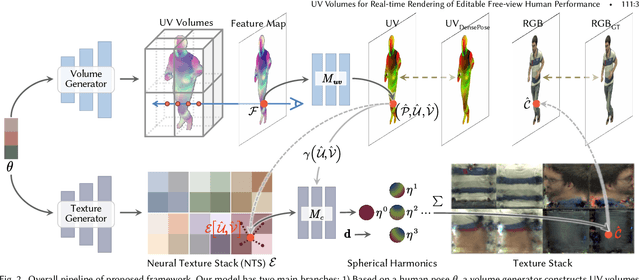

Neural volume rendering has been proven to be a promising method for efficient and photo-realistic rendering of a human performer in free-view, a critical task in many immersive VR/AR applications. However, existing approaches are severely limited by their high computational cost in the rendering process. To solve this problem, we propose the UV Volumes, an approach that can render an editable free-view video of a human performer in real-time. It is achieved by removing the high-frequency (i.e., non-smooth) human textures from the 3D volume and encoding them into a 2D neural texture stack (NTS). The smooth UV volume allows us to employ a much smaller and shallower structure for 3D CNN and MLP, to obtain the density and texture coordinates without losing image details. Meanwhile, the NTS only needs to be queried once for each pixel in the UV image to retrieve its RGB value. For editability, the 3D CNN and MLP decoder can easily fit the function that maps the input structured-and-posed latent codes to the relatively smooth densities and texture coordinates. It gives our model a better generalization ability to handle novel poses and shapes. Furthermore, the use of NST enables new applications, e.g., retexturing. Extensive experiments on CMU Panoptic, ZJU Mocap, and H36M datasets show that our model can render 900 * 500 images in 40 fps on average with comparable photorealism to state-of-the-art methods. The project and supplementary materials are available at https://fanegg.github.io/UV-Volumes.
Unsupervised Pre-training for Temporal Action Localization Tasks
Mar 25, 2022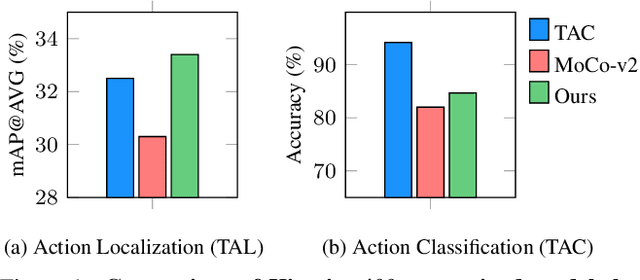
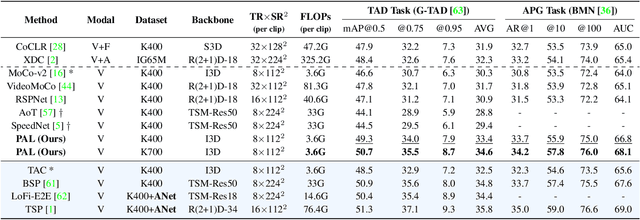
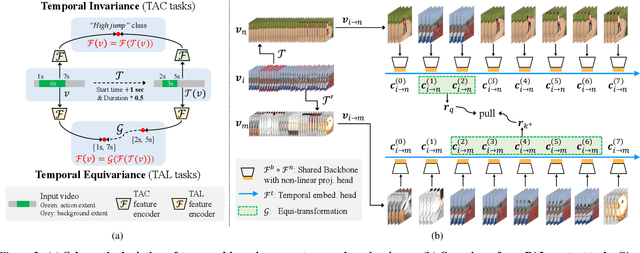
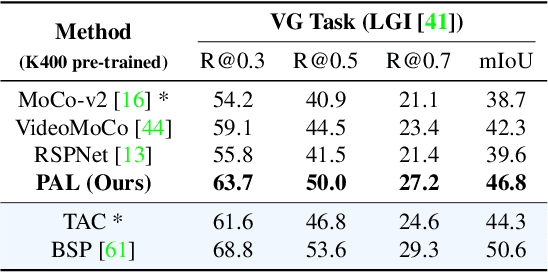
Unsupervised video representation learning has made remarkable achievements in recent years. However, most existing methods are designed and optimized for video classification. These pre-trained models can be sub-optimal for temporal localization tasks due to the inherent discrepancy between video-level classification and clip-level localization. To bridge this gap, we make the first attempt to propose a self-supervised pretext task, coined as Pseudo Action Localization (PAL) to Unsupervisedly Pre-train feature encoders for Temporal Action Localization tasks (UP-TAL). Specifically, we first randomly select temporal regions, each of which contains multiple clips, from one video as pseudo actions and then paste them onto different temporal positions of the other two videos. The pretext task is to align the features of pasted pseudo action regions from two synthetic videos and maximize the agreement between them. Compared to the existing unsupervised video representation learning approaches, our PAL adapts better to downstream TAL tasks by introducing a temporal equivariant contrastive learning paradigm in a temporally dense and scale-aware manner. Extensive experiments show that PAL can utilize large-scale unlabeled video data to significantly boost the performance of existing TAL methods. Our codes and models will be made publicly available at https://github.com/zhang-can/UP-TAL.
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Mar 23, 2022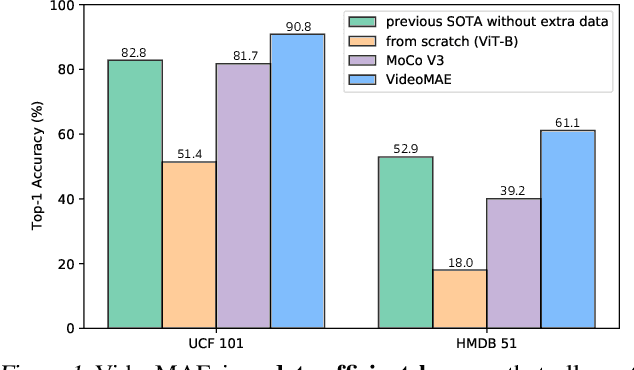
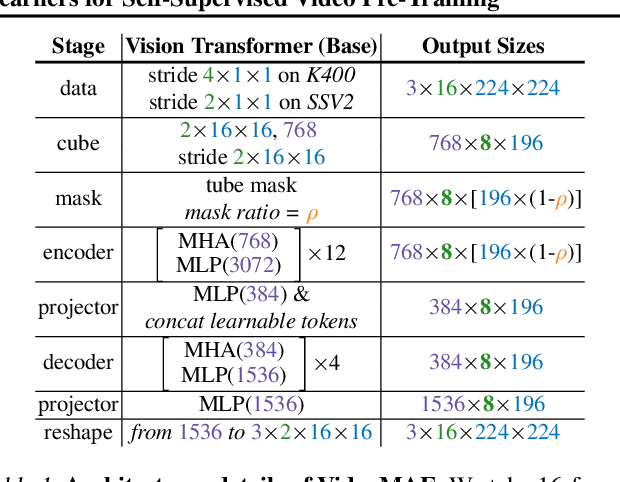
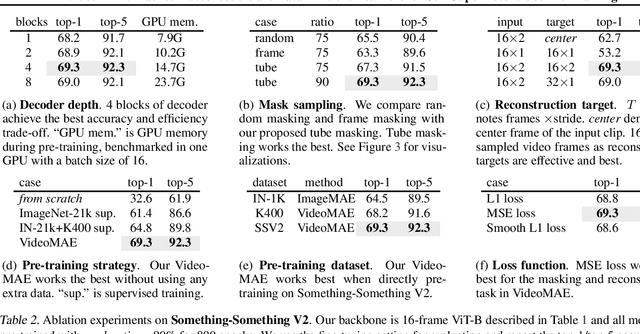
Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data. Code will be released at https://github.com/MCG-NJU/VideoMAE.
StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Mar 17, 2022
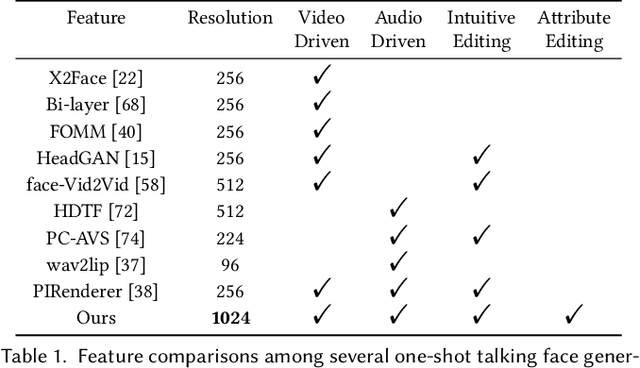

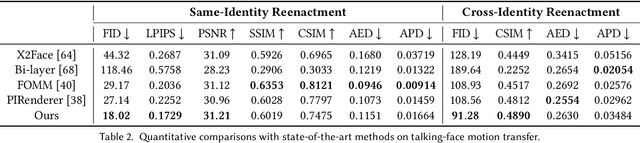
One-shot talking face generation aims at synthesizing a high-quality talking face video from an arbitrary portrait image, driven by a video or an audio segment. One challenging quality factor is the resolution of the output video: higher resolution conveys more details. In this work, we investigate the latent feature space of a pre-trained StyleGAN and discover some excellent spatial transformation properties. Upon the observation, we explore the possibility of using a pre-trained StyleGAN to break through the resolution limit of training datasets. We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing. Our framework elevates the resolution of the synthesized talking face to 1024*1024 for the first time, even though the training dataset has a lower resolution. We design a video-based motion generation module and an audio-based one, which can be plugged into the framework either individually or jointly to drive the video generation. The predicted motion is used to transform the latent features of StyleGAN for visual animation. To compensate for the transformation distortion, we propose a calibration network as well as a domain loss to refine the features. Moreover, our framework allows two types of facial editing, i.e., global editing via GAN inversion and intuitive editing based on 3D morphable models. Comprehensive experiments show superior video quality, flexible controllability, and editability over state-of-the-art methods.
LAS-AT: Adversarial Training with Learnable Attack Strategy
Mar 13, 2022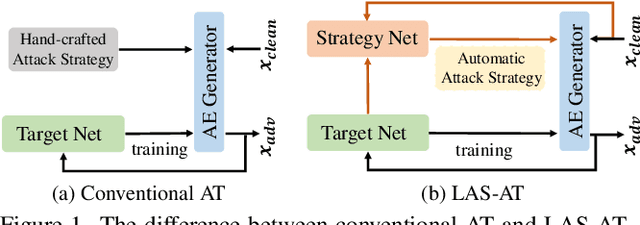

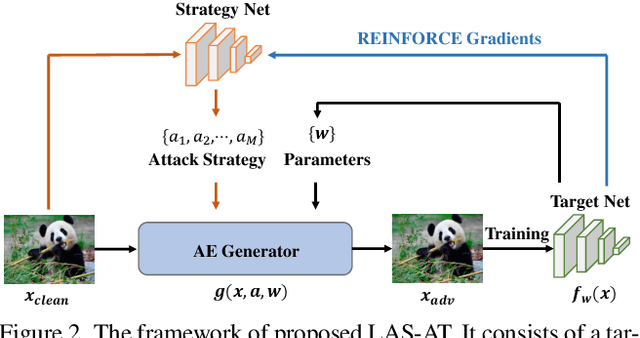
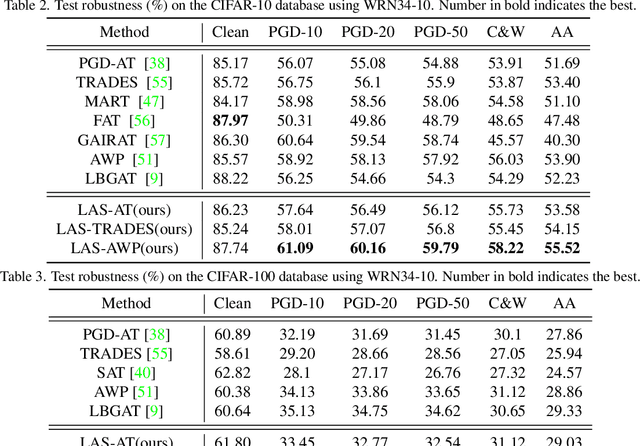
Adversarial training (AT) is always formulated as a minimax problem, of which the performance depends on the inner optimization that involves the generation of adversarial examples (AEs). Most previous methods adopt Projected Gradient Decent (PGD) with manually specifying attack parameters for AE generation. A combination of the attack parameters can be referred to as an attack strategy. Several works have revealed that using a fixed attack strategy to generate AEs during the whole training phase limits the model robustness and propose to exploit different attack strategies at different training stages to improve robustness. But those multi-stage hand-crafted attack strategies need much domain expertise, and the robustness improvement is limited. In this paper, we propose a novel framework for adversarial training by introducing the concept of "learnable attack strategy", dubbed LAS-AT, which learns to automatically produce attack strategies to improve the model robustness. Our framework is composed of a target network that uses AEs for training to improve robustness and a strategy network that produces attack strategies to control the AE generation. Experimental evaluations on three benchmark databases demonstrate the superiority of the proposed method. The code is released at https://github.com/jiaxiaojunQAQ/LAS-AT.
Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations
Feb 16, 2022

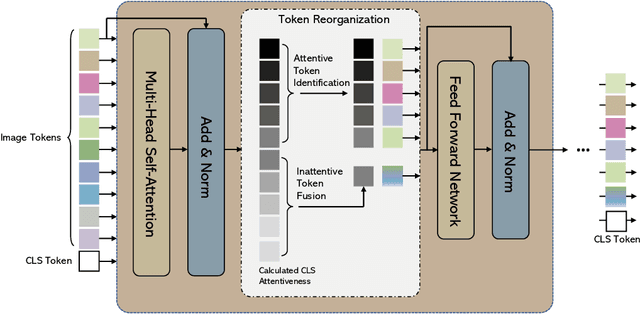
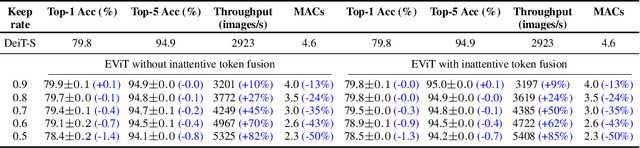
Vision Transformers (ViTs) take all the image patches as tokens and construct multi-head self-attention (MHSA) among them. Complete leverage of these image tokens brings redundant computations since not all the tokens are attentive in MHSA. Examples include that tokens containing semantically meaningless or distractive image backgrounds do not positively contribute to the ViT predictions. In this work, we propose to reorganize image tokens during the feed-forward process of ViT models, which is integrated into ViT during training. For each forward inference, we identify the attentive image tokens between MHSA and FFN (i.e., feed-forward network) modules, which is guided by the corresponding class token attention. Then, we reorganize image tokens by preserving attentive image tokens and fusing inattentive ones to expedite subsequent MHSA and FFN computations. To this end, our method EViT improves ViTs from two perspectives. First, under the same amount of input image tokens, our method reduces MHSA and FFN computation for efficient inference. For instance, the inference speed of DeiT-S is increased by 50% while its recognition accuracy is decreased by only 0.3% for ImageNet classification. Second, by maintaining the same computational cost, our method empowers ViTs to take more image tokens as input for recognition accuracy improvement, where the image tokens are from higher resolution images. An example is that we improve the recognition accuracy of DeiT-S by 1% for ImageNet classification at the same computational cost of a vanilla DeiT-S. Meanwhile, our method does not introduce more parameters to ViTs. Experiments on the standard benchmarks show the effectiveness of our method. The code is available at https://github.com/youweiliang/evit
Reinforcement Learning-Empowered Mobile Edge Computing for 6G Edge Intelligence
Feb 03, 2022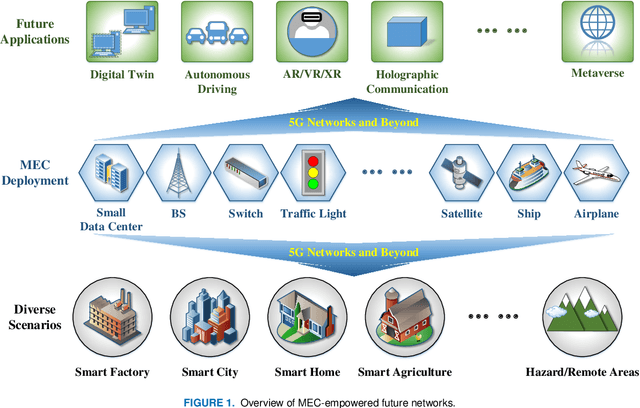
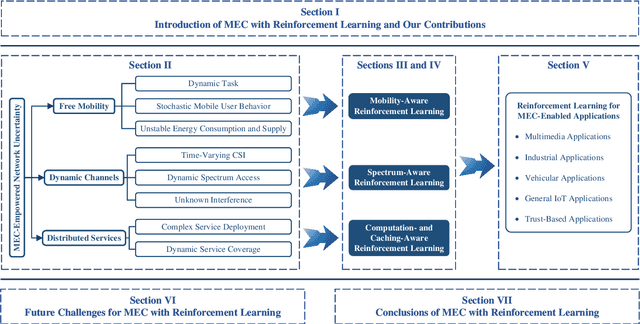
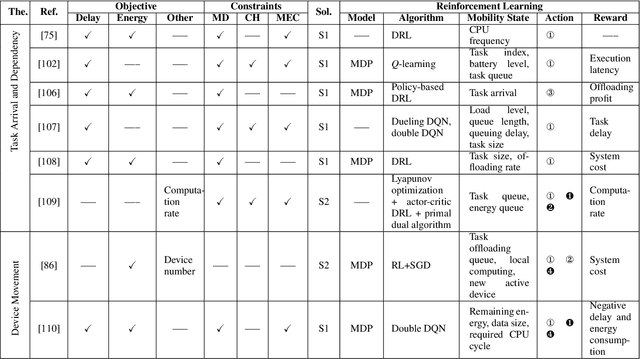
Mobile edge computing (MEC) is considered a novel paradigm for computation-intensive and delay-sensitive tasks in fifth generation (5G) networks and beyond. However, its uncertainty, referred to as dynamic and randomness, from the mobile device, wireless channel, and edge network sides, results in high-dimensional, nonconvex, nonlinear, and NP-hard optimization problems. Thanks to the evolved reinforcement learning (RL), upon iteratively interacting with the dynamic and random environment, its trained agent can intelligently obtain the optimal policy in MEC. Furthermore, its evolved versions, such as deep RL (DRL), can achieve higher convergence speed efficiency and learning accuracy based on the parametric approximation for the large-scale state-action space. This paper provides a comprehensive research review on RL-enabled MEC and offers insight for development in this area. More importantly, associated with free mobility, dynamic channels, and distributed services, the MEC challenges that can be solved by different kinds of RL algorithms are identified, followed by how they can be solved by RL solutions in diverse mobile applications. Finally, the open challenges are discussed to provide helpful guidance for future research in RL training and learning MEC.
PONet: Robust 3D Human Pose Estimation via Learning Orientations Only
Dec 21, 2021

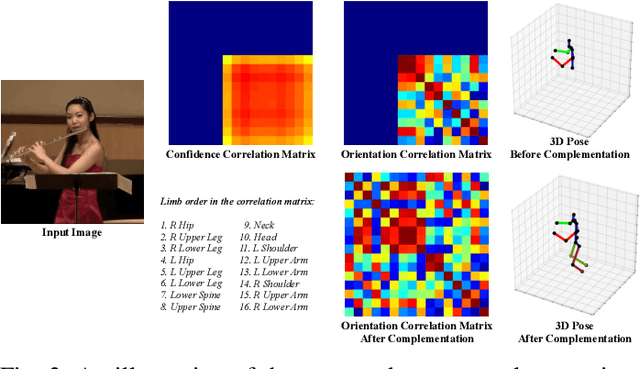
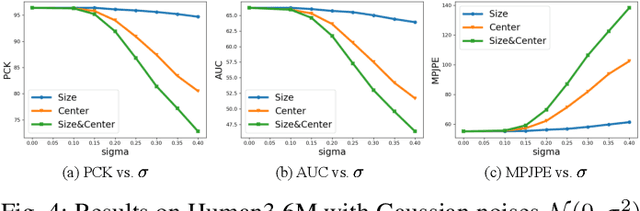
Conventional 3D human pose estimation relies on first detecting 2D body keypoints and then solving the 2D to 3D correspondence problem.Despite the promising results, this learning paradigm is highly dependent on the quality of the 2D keypoint detector, which is inevitably fragile to occlusions and out-of-image absences.In this paper,we propose a novel Pose Orientation Net (PONet) that is able to robustly estimate 3D pose by learning orientations only, hence bypassing the error-prone keypoint detector in the absence of image evidence. For images with partially invisible limbs, PONet estimates the 3D orientation of these limbs by taking advantage of the local image evidence to recover the 3D pose.Moreover, PONet is competent to infer full 3D poses even from images with completely invisible limbs, by exploiting the orientation correlation between visible limbs to complement the estimated poses,further improving the robustness of 3D pose estimation.We evaluate our method on multiple datasets, including Human3.6M, MPII, MPI-INF-3DHP, and 3DPW. Our method achieves results on par with state-of-the-art techniques in ideal settings, yet significantly eliminates the dependency on keypoint detectors and the corresponding computation burden. In highly challenging scenarios, such as truncation and erasing, our method performs very robustly and yields much superior results as compared to state of the art,demonstrating its potential for real-world applications.
DisCo: Effective Knowledge Distillation For Contrastive Learning of Sentence Embeddings
Dec 10, 2021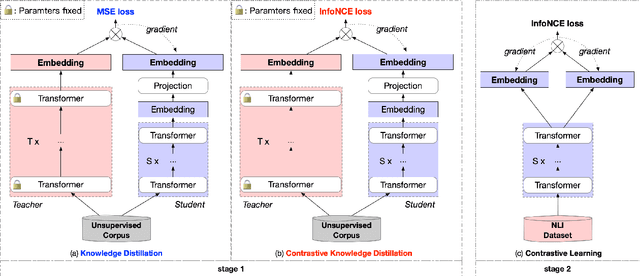
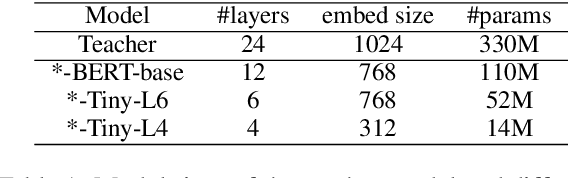
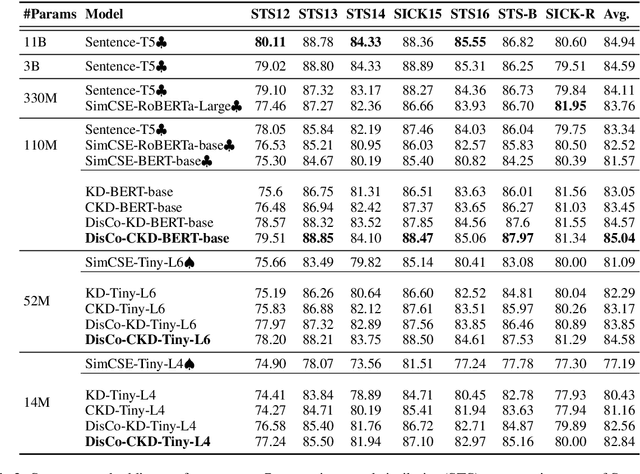
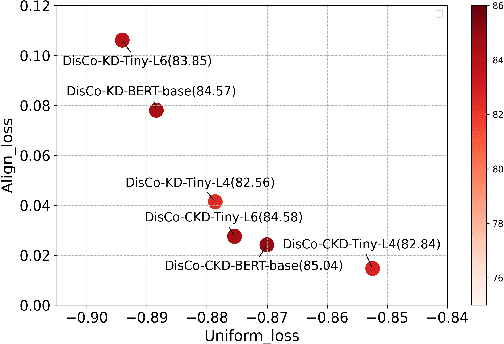
Contrastive learning has been proven suitable for learning sentence embeddings and can significantly improve the semantic textual similarity (STS) tasks. Recently, large contrastive learning models, e.g., Sentence-T5, tend to be proposed to learn more powerful sentence embeddings. Though effective, such large models are hard to serve online due to computational resources or time cost limits. To tackle that, knowledge distillation (KD) is commonly adopted, which can compress a large "teacher" model into a small "student" model but generally suffer from some performance loss. Here we propose an enhanced KD framework termed Distill-Contrast (DisCo). The proposed DisCo framework firstly utilizes KD to transfer the capability of a large sentence embedding model to a small student model on large unlabelled data, and then finetunes the student model with contrastive learning on labelled training data. For the KD process in DisCo, we further propose Contrastive Knowledge Distillation (CKD) to enhance the consistencies among teacher model training, KD, and student model finetuning, which can probably improve performance like prompt learning. Extensive experiments on 7 STS benchmarks show that student models trained with the proposed DisCo and CKD suffer from little or even no performance loss and consistently outperform the corresponding counterparts of the same parameter size. Amazingly, our 110M student model can even outperform the latest state-of-the-art (SOTA) model, i.e., Sentence-T5(11B), with only 1% parameters.
Hallucinated Neural Radiance Fields in the Wild
Dec 01, 2021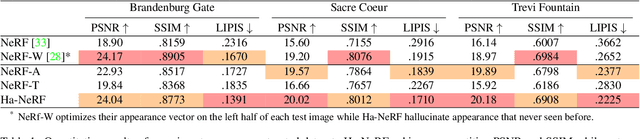
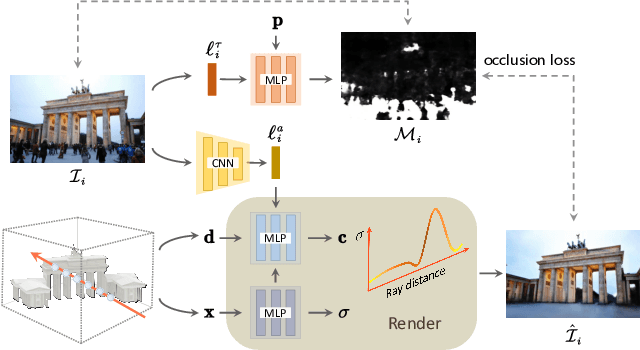
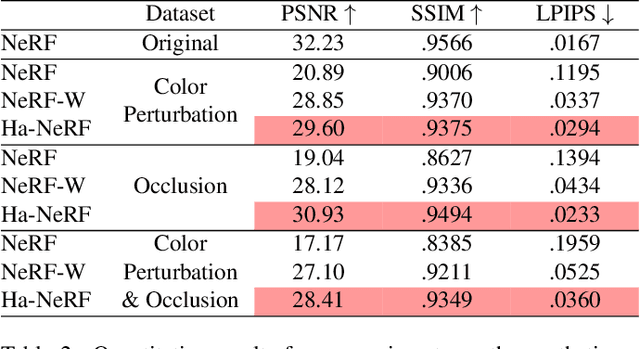
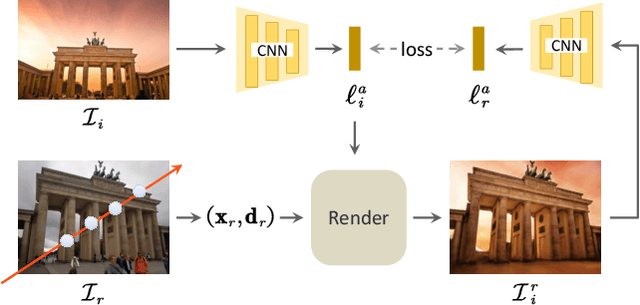
Neural Radiance Fields (NeRF) has recently gained popularity for its impressive novel view synthesis ability. This paper studies the problem of hallucinated NeRF: i.e. recovering a realistic NeRF at a different time of day from a group of tourism images. Existing solutions adopt NeRF with a controllable appearance embedding to render novel views under various conditions, but cannot render view-consistent images with an unseen appearance. To solve this problem, we present an end-to-end framework for constructing a hallucinated NeRF, dubbed as Ha-NeRF. Specifically, we propose an appearance hallucination module to handle time-varying appearances and transfer them to novel views. Considering the complex occlusions of tourism images, an anti-occlusion module is introduced to decompose the static subjects for visibility accurately. Experimental results on synthetic data and real tourism photo collections demonstrate that our method can not only hallucinate the desired appearances, but also render occlusion-free images from different views. The project and supplementary materials are available at https://rover-xingyu.github.io/Ha-NeRF/.