 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Paper and Code
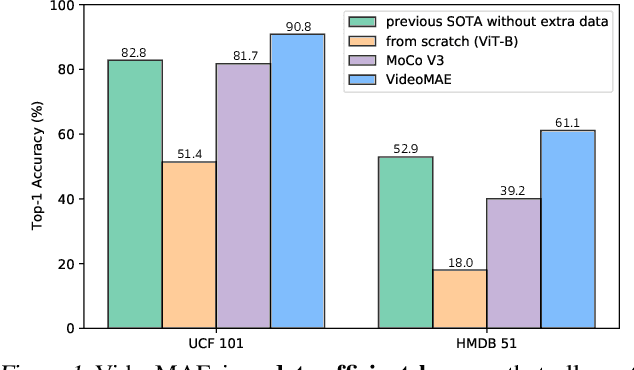
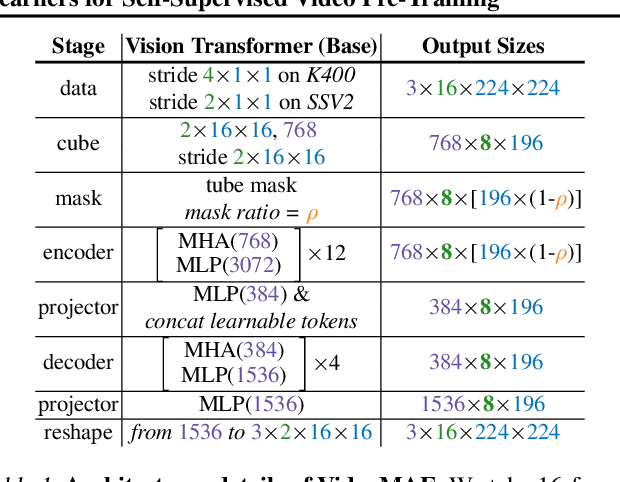
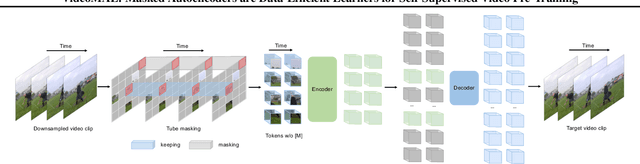
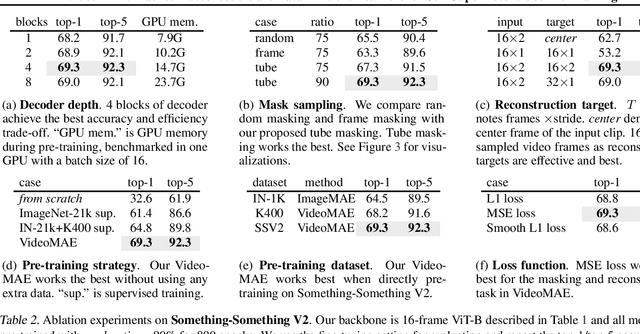
Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data. Code will be released at https://github.com/MCG-NJU/VideoMAE.