 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Adversarial Training with Adaptive Step Size
Jun 06, 2022
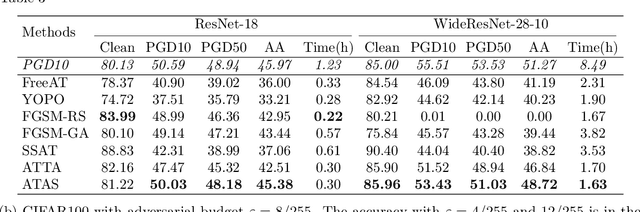
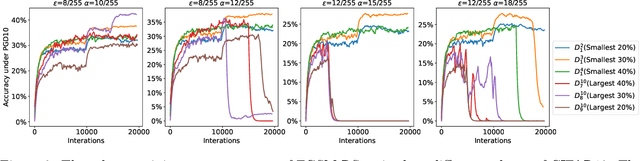
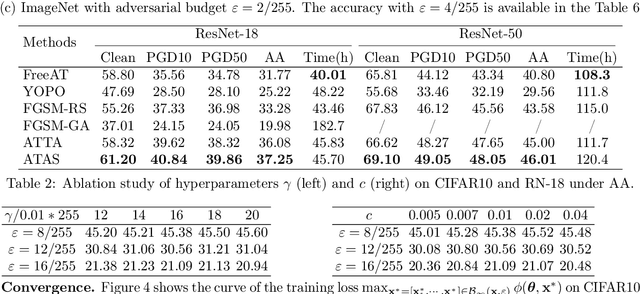
While adversarial training and its variants have shown to be the most effective algorithms to defend against adversarial attacks, their extremely slow training process makes it hard to scale to large datasets like ImageNet. The key idea of recent works to accelerate adversarial training is to substitute multi-step attacks (e.g., PGD) with single-step attacks (e.g., FGSM). However, these single-step methods suffer from catastrophic overfitting, where the accuracy against PGD attack suddenly drops to nearly 0% during training, destroying the robustness of the networks. In this work, we study the phenomenon from the perspective of training instances. We show that catastrophic overfitting is instance-dependent and fitting instances with larger gradient norm is more likely to cause catastrophic overfitting. Based on our findings, we propose a simple but effective method, Adversarial Training with Adaptive Step size (ATAS). ATAS learns an instancewise adaptive step size that is inversely proportional to its gradient norm. The theoretical analysis shows that ATAS converges faster than the commonly adopted non-adaptive counterparts. Empirically, ATAS consistently mitigates catastrophic overfitting and achieves higher robust accuracy on CIFAR10, CIFAR100 and ImageNet when evaluated on various adversarial budgets.
Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees
Jun 02, 2022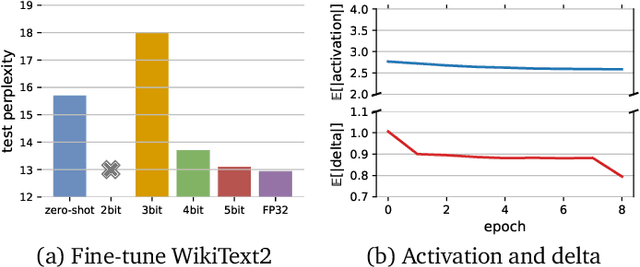
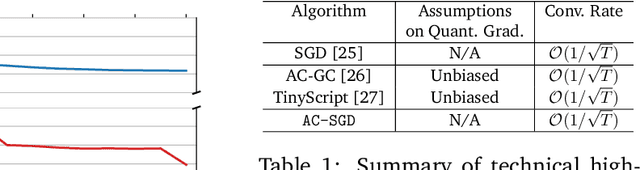
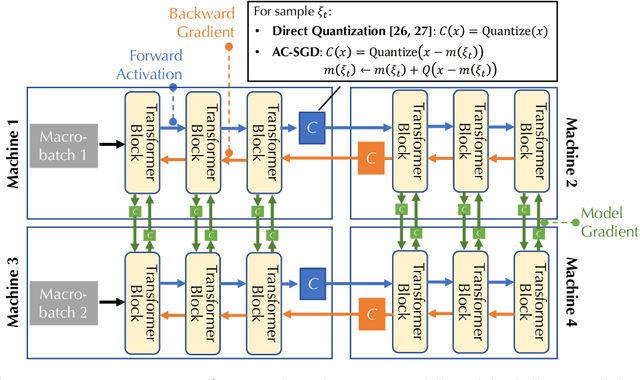

Communication compression is a crucial technique for modern distributed learning systems to alleviate their communication bottlenecks over slower networks. Despite recent intensive studies of gradient compression for data parallel-style training, compressing the activations for models trained with pipeline parallelism is still an open problem. In this paper, we propose AC-SGD, a novel activation compression algorithm for communication-efficient pipeline parallelism training over slow networks. Different from previous efforts in activation compression, instead of compressing activation values directly, AC-SGD compresses the changes of the activations. This allows us to show, to the best of our knowledge for the first time, that one can still achieve $O(1/\sqrt{T})$ convergence rate for non-convex objectives under activation compression, without making assumptions on gradient unbiasedness that do not hold for deep learning models with non-linear activation functions.We then show that AC-SGD can be optimized and implemented efficiently, without additional end-to-end runtime overhead.We evaluated AC-SGD to fine-tune language models with up to 1.5 billion parameters, compressing activations to 2-4 bits.AC-SGD provides up to 4.3X end-to-end speed-up in slower networks, without sacrificing model quality. Moreover, we also show that AC-SGD can be combined with state-of-the-art gradient compression algorithms to enable "end-to-end communication compression: All communications between machines, including model gradients, forward activations, and backward gradients are compressed into lower precision.This provides up to 4.9X end-to-end speed-up, without sacrificing model quality.
IDE-3D: Interactive Disentangled Editing for High-Resolution 3D-aware Portrait Synthesis
May 31, 2022
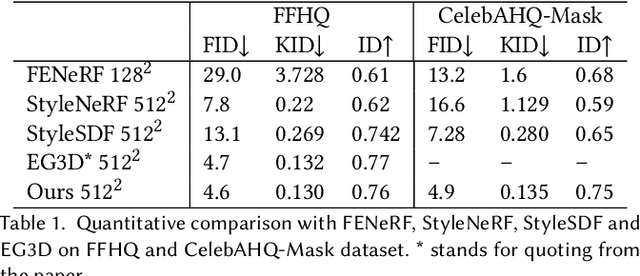
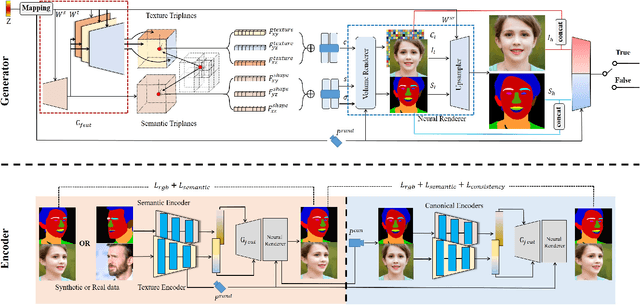

Existing 3D-aware facial generation methods face a dilemma in quality versus editability: they either generate editable results in low resolution or high-quality ones with no editing flexibility. In this work, we propose a new approach that brings the best of both worlds together. Our system consists of three major components: (1) a 3D-semantics-aware generative model that produces view-consistent, disentangled face images and semantic masks; (2) a hybrid GAN inversion approach that initialize the latent codes from the semantic and texture encoder, and further optimized them for faithful reconstruction; and (3) a canonical editor that enables efficient manipulation of semantic masks in canonical view and product high-quality editing results. Our approach is competent for many applications, e.g. free-view face drawing, editing, and style control. Both quantitative and qualitative results show that our method reaches the state-of-the-art in terms of photorealism, faithfulness, and efficiency.
AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
May 26, 2022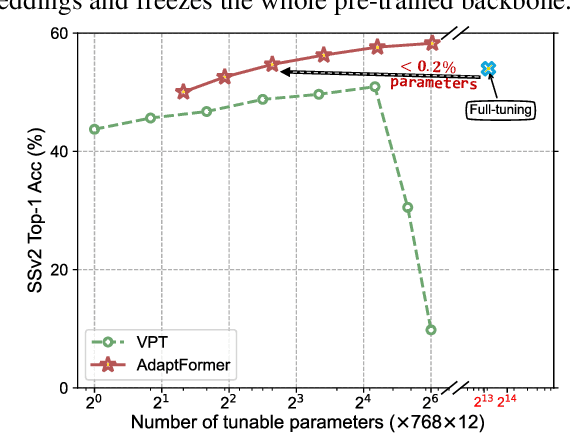
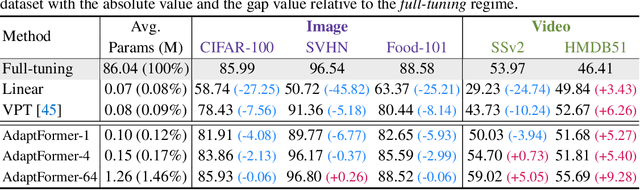


Although the pre-trained Vision Transformers (ViTs) achieved great success in computer vision, adapting a ViT to various image and video tasks is challenging because of its heavy computation and storage burdens, where each model needs to be independently and comprehensively fine-tuned to different tasks, limiting its transferability in different domains. To address this challenge, we propose an effective adaptation approach for Transformer, namely AdaptFormer, which can adapt the pre-trained ViTs into many different image and video tasks efficiently. It possesses several benefits more appealing than prior arts. Firstly, AdaptFormer introduces lightweight modules that only add less than 2% extra parameters to a ViT, while it is able to increase the ViT's transferability without updating its original pre-trained parameters, significantly outperforming the existing 100% fully fine-tuned models on action recognition benchmarks. Secondly, it can be plug-and-play in different Transformers and scalable to many visual tasks. Thirdly, extensive experiments on five image and video datasets show that AdaptFormer largely improves ViTs in the target domains. For example, when updating just 1.5% extra parameters, it achieves about 10% and 19% relative improvement compared to the fully fine-tuned models on Something-Something~v2 and HMDB51, respectively. Project page: http://www.shoufachen.com/adaptformer-page.
Improving the Latent Space of Image Style Transfer
May 24, 2022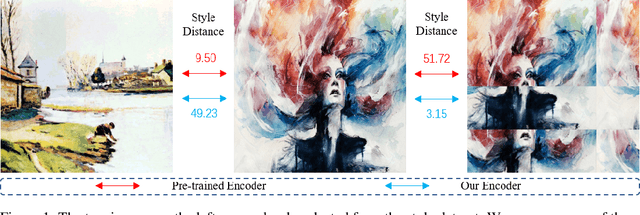
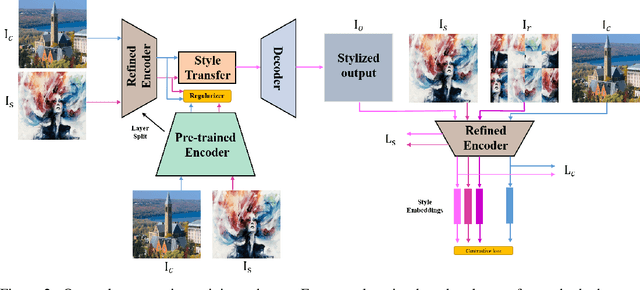
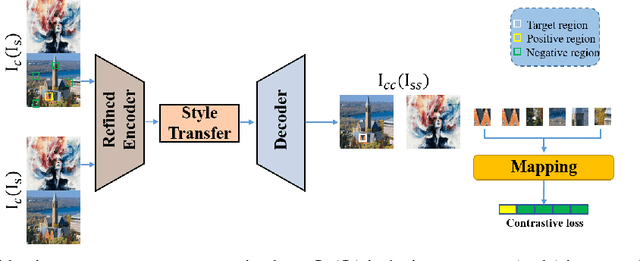

Existing neural style transfer researches have studied to match statistical information between the deep features of content and style images, which were extracted by a pre-trained VGG, and achieved significant improvement in synthesizing artistic images. However, in some cases, the feature statistics from the pre-trained encoder may not be consistent with the visual style we perceived. For example, the style distance between images of different styles is less than that of the same style. In such an inappropriate latent space, the objective function of the existing methods will be optimized in the wrong direction, resulting in bad stylization results. In addition, the lack of content details in the features extracted by the pre-trained encoder also leads to the content leak problem. In order to solve these issues in the latent space used by style transfer, we propose two contrastive training schemes to get a refined encoder that is more suitable for this task. The style contrastive loss pulls the stylized result closer to the same visual style image and pushes it away from the content image. The content contrastive loss enables the encoder to retain more available details. We can directly add our training scheme to some existing style transfer methods and significantly improve their results. Extensive experimental results demonstrate the effectiveness and superiority of our methods.
Hybrid RIS and DMA Assisted Multiuser MIMO Uplink Transmission With Electromagnetic Exposure Constraints
May 10, 2022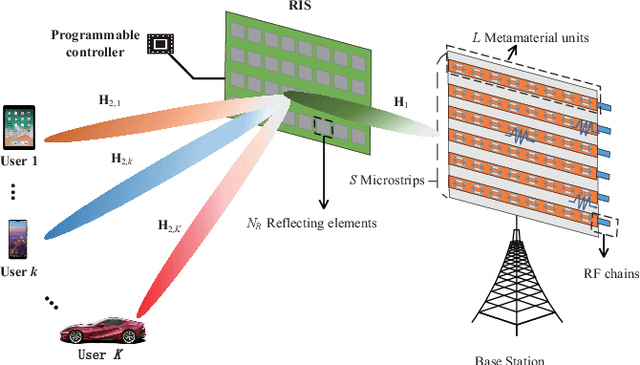
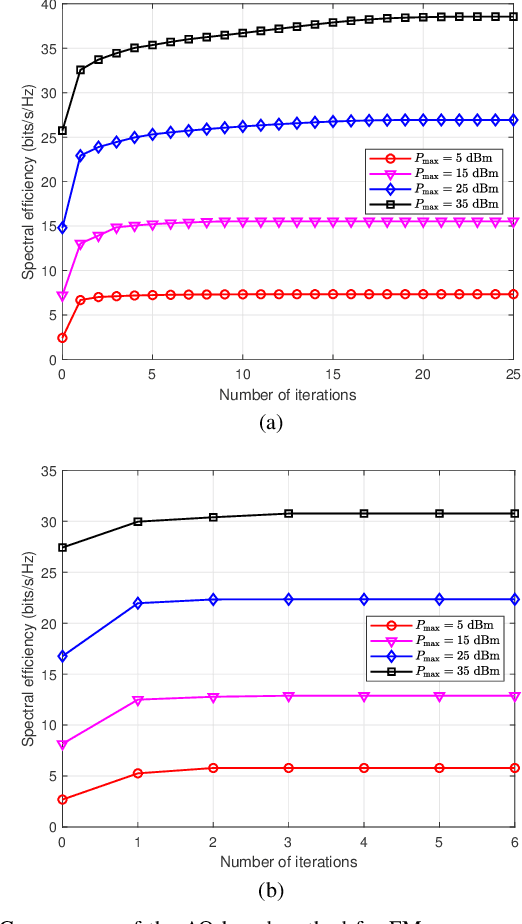
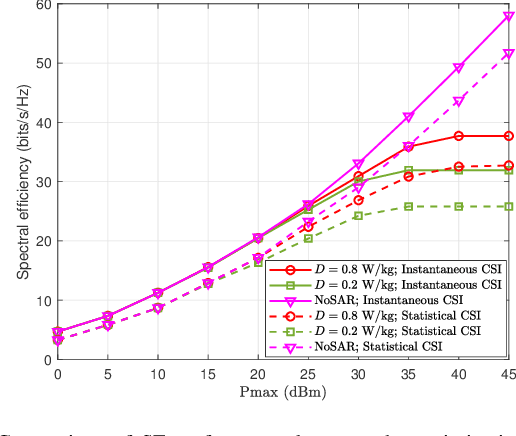
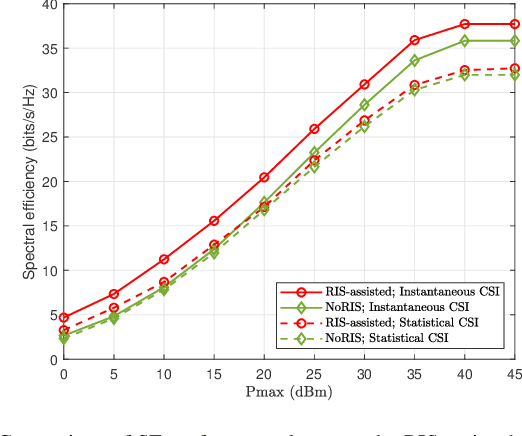
In the fifth-generation and beyond era, reconfigurable intelligent surface (RIS) and dynamic metasurface antennas (DMAs) are emerging metamaterials keeping up with the demand for high-quality wireless communication services, which promote the diversification of portable wireless terminals. However, along with the rapid expansion of wireless devices, the electromagnetic (EM) radiation increases unceasingly and inevitably affects public health, which requires a limited exposure level in the transmission design. To reduce the EM radiation and preserve the quality of communication service, we investigate the spectral efficiency (SE) maximization with EM constraints for uplink transmission in hybrid RIS and DMA assisted multiuser multiple-input multiple-output systems. Specifically, alternating optimization is adopted to optimize the transmit covariance, RIS phase shift, and DMA weight matrices. We first figure out the water-filling solutions of transmit covariance matrices with given RIS and DMA parameters. Then, the RIS phase shift matrix is optimized via the weighted minimum mean square error, block coordinate descent and minorization-maximization methods. Furthermore, we solve the unconstrainted DMA weight matrix optimization problem in closed form and then design the DMA weight matrix to approach this performance under DMA constraints. Numerical results confirm the effectiveness of the EM aware SE maximization transmission scheme over the conventional baselines.
VDTR: Video Deblurring with Transformer
Apr 17, 2022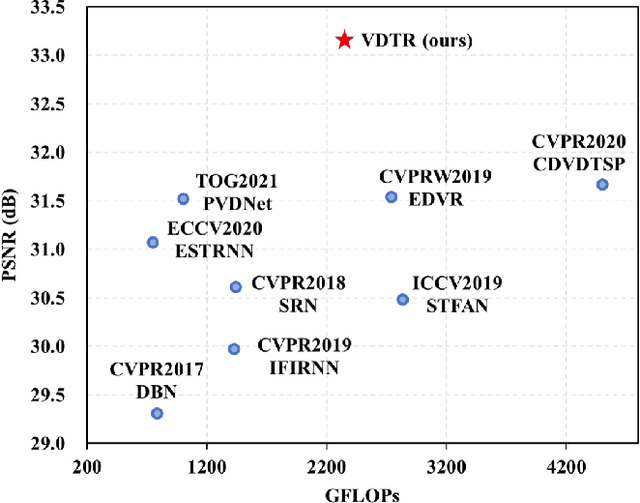


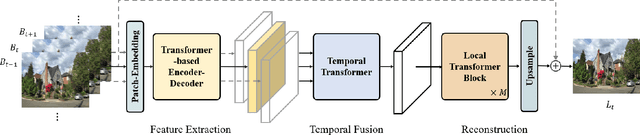
Video deblurring is still an unsolved problem due to the challenging spatio-temporal modeling process. While existing convolutional neural network-based methods show a limited capacity for effective spatial and temporal modeling for video deblurring. This paper presents VDTR, an effective Transformer-based model that makes the first attempt to adapt Transformer for video deblurring. VDTR exploits the superior long-range and relation modeling capabilities of Transformer for both spatial and temporal modeling. However, it is challenging to design an appropriate Transformer-based model for video deblurring due to the complicated non-uniform blurs, misalignment across multiple frames and the high computational costs for high-resolution spatial modeling. To address these problems, VDTR advocates performing attention within non-overlapping windows and exploiting the hierarchical structure for long-range dependencies modeling. For frame-level spatial modeling, we propose an encoder-decoder Transformer that utilizes multi-scale features for deblurring. For multi-frame temporal modeling, we adapt Transformer to fuse multiple spatial features efficiently. Compared with CNN-based methods, the proposed method achieves highly competitive results on both synthetic and real-world video deblurring benchmarks, including DVD, GOPRO, REDS and BSD. We hope such a Transformer-based architecture can serve as a powerful alternative baseline for video deblurring and other video restoration tasks. The source code will be available at \url{https://github.com/ljzycmd/VDTR}.
Self-supervised Learning of Adversarial Example: Towards Good Generalizations for Deepfake Detection
Apr 01, 2022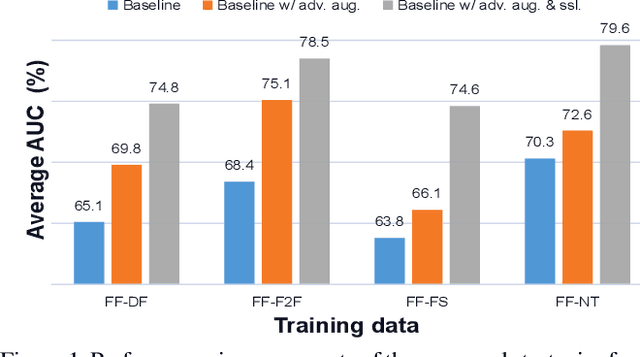
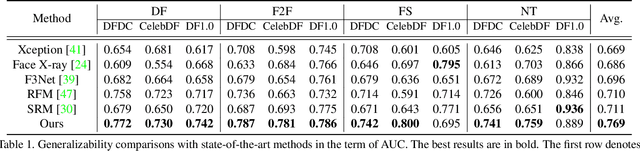

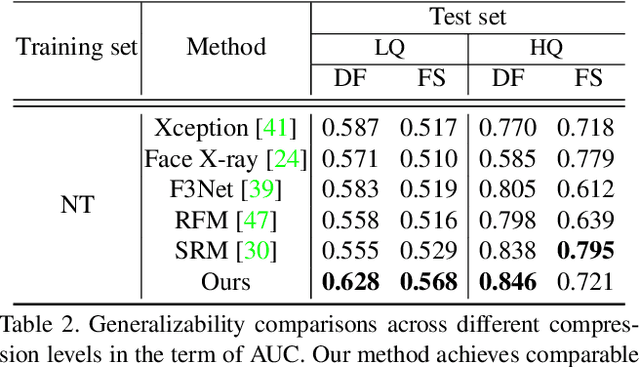
Recent studies in deepfake detection have yielded promising results when the training and testing face forgeries are from the same dataset. However, the problem remains challenging when one tries to generalize the detector to forgeries created by unseen methods in the training dataset. This work addresses the generalizable deepfake detection from a simple principle: a generalizable representation should be sensitive to diverse types of forgeries. Following this principle, we propose to enrich the "diversity" of forgeries by synthesizing augmented forgeries with a pool of forgery configurations and strengthen the "sensitivity" to the forgeries by enforcing the model to predict the forgery configurations. To effectively explore the large forgery augmentation space, we further propose to use the adversarial training strategy to dynamically synthesize the most challenging forgeries to the current model. Through extensive experiments, we show that the proposed strategies are surprisingly effective (see Figure 1), and they could achieve superior performance than the current state-of-the-art methods. Code is available at \url{https://github.com/liangchen527/SLADD}.
Multi-Robot Active Mapping via Neural Bipartite Graph Matching
Apr 01, 2022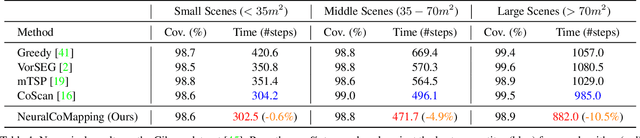
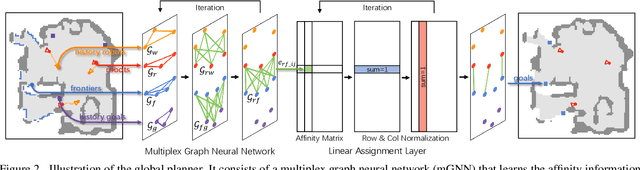
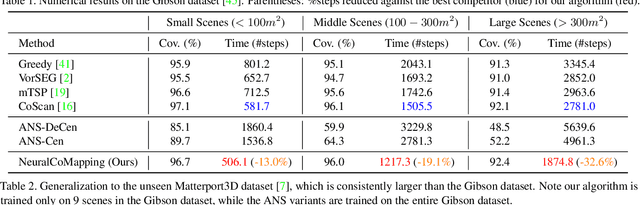
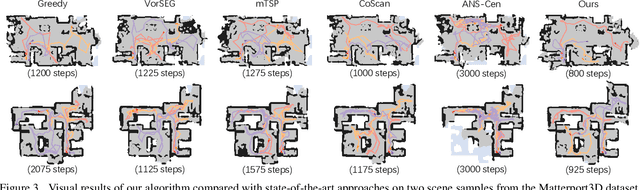
We study the problem of multi-robot active mapping, which aims for complete scene map construction in minimum time steps. The key to this problem lies in the goal position estimation to enable more efficient robot movements. Previous approaches either choose the frontier as the goal position via a myopic solution that hinders the time efficiency, or maximize the long-term value via reinforcement learning to directly regress the goal position, but does not guarantee the complete map construction. In this paper, we propose a novel algorithm, namely NeuralCoMapping, which takes advantage of both approaches. We reduce the problem to bipartite graph matching, which establishes the node correspondences between two graphs, denoting robots and frontiers. We introduce a multiplex graph neural network (mGNN) that learns the neural distance to fill the affinity matrix for more effective graph matching. We optimize the mGNN with a differentiable linear assignment layer by maximizing the long-term values that favor time efficiency and map completeness via reinforcement learning. We compare our algorithm with several state-of-the-art multi-robot active mapping approaches and adapted reinforcement-learning baselines. Experimental results demonstrate the superior performance and exceptional generalization ability of our algorithm on various indoor scenes and unseen number of robots, when only trained with 9 indoor scenes.
Deformable Video Transformer
Mar 31, 2022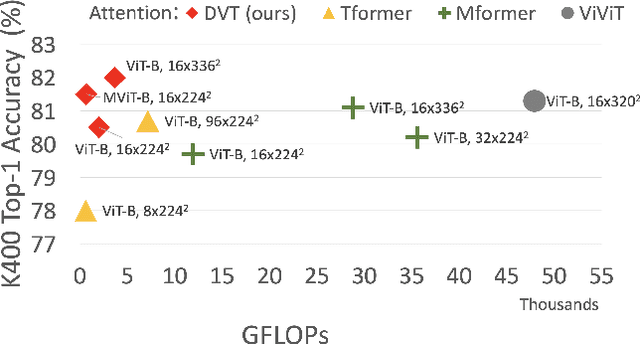

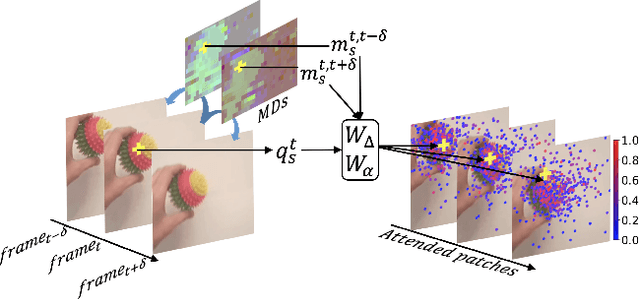
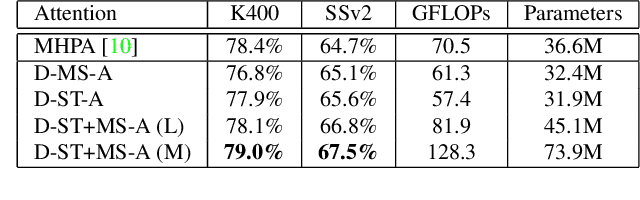
Video transformers have recently emerged as an effective alternative to convolutional networks for action classification. However, most prior video transformers adopt either global space-time attention or hand-defined strategies to compare patches within and across frames. These fixed attention schemes not only have high computational cost but, by comparing patches at predetermined locations, they neglect the motion dynamics in the video. In this paper, we introduce the Deformable Video Transformer (DVT), which dynamically predicts a small subset of video patches to attend for each query location based on motion information, thus allowing the model to decide where to look in the video based on correspondences across frames. Crucially, these motion-based correspondences are obtained at zero-cost from information stored in the compressed format of the video. Our deformable attention mechanism is optimised directly with respect to classification performance, thus eliminating the need for suboptimal hand-design of attention strategies. Experiments on four large-scale video benchmarks (Kinetics-400, Something-Something-V2, EPIC-KITCHENS and Diving-48) demonstrate that, compared to existing video transformers, our model achieves higher accuracy at the same or lower computational cost, and it attains state-of-the-art results on these four datasets.