 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact Points Discovery for Soft-Body Manipulations with Differentiable Physics
May 05, 2022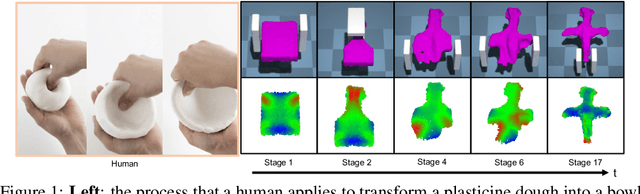
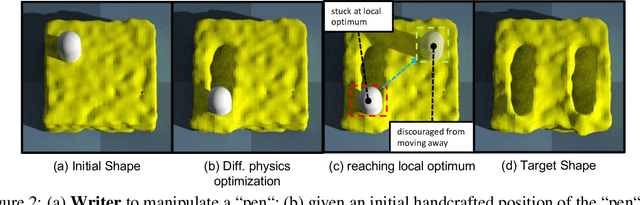
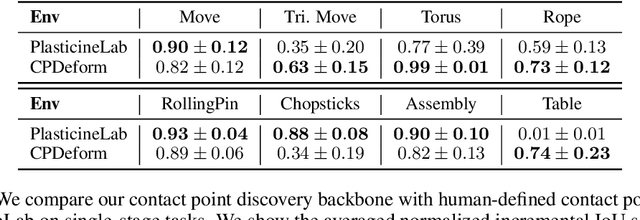
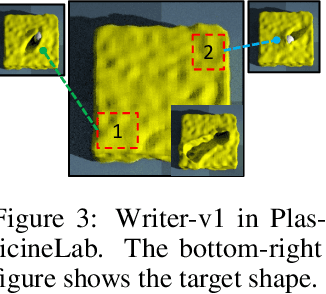
Differentiable physics has recently been shown as a powerful tool for solving soft-body manipulation tasks. However, the differentiable physics solver often gets stuck when the initial contact points of the end effectors are sub-optimal or when performing multi-stage tasks that require contact point switching, which often leads to local minima. To address this challenge, we propose a contact point discovery approach (CPDeform) that guides the stand-alone differentiable physics solver to deform various soft-body plasticines. The key idea of our approach is to integrate optimal transport-based contact points discovery into the differentiable physics solver to overcome the local minima from initial contact points or contact switching. On single-stage tasks, our method can automatically find suitable initial contact points based on transport priorities. On complex multi-stage tasks, we can iteratively switch the contact points of end-effectors based on transport priorities. To evaluate the effectiveness of our method, we introduce PlasticineLab-M that extends the existing differentiable physics benchmark PlasticineLab to seven new challenging multi-stage soft-body manipulation tasks. Extensive experimental results suggest that: 1) on multi-stage tasks that are infeasible for the vanilla differentiable physics solver, our approach discovers contact points that efficiently guide the solver to completion; 2) on tasks where the vanilla solver performs sub-optimally or near-optimally, our contact point discovery method performs better than or on par with the manipulation performance obtained with handcrafted contact points.
Fixing Malfunctional Objects With Learned Physical Simulation and Functional Prediction
May 05, 2022
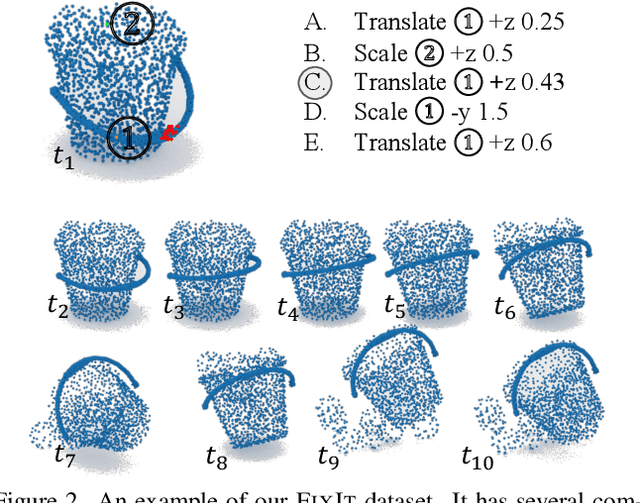
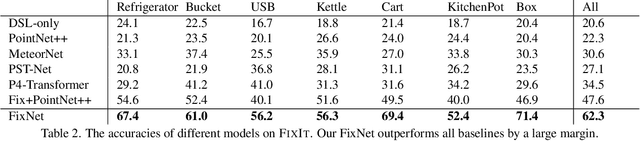
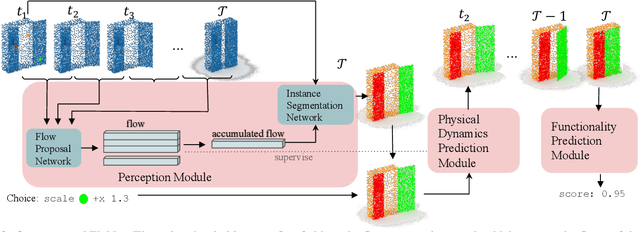
This paper studies the problem of fixing malfunctional 3D objects. While previous works focus on building passive perception models to learn the functionality from static 3D objects, we argue that functionality is reckoned with respect to the physical interactions between the object and the user. Given a malfunctional object, humans can perform mental simulations to reason about its functionality and figure out how to fix it. Inspired by this, we propose FixIt, a dataset that contains about 5k poorly-designed 3D physical objects paired with choices to fix them. To mimic humans' mental simulation process, we present FixNet, a novel framework that seamlessly incorporates perception and physical dynamics. Specifically, FixNet consists of a perception module to extract the structured representation from the 3D point cloud, a physical dynamics prediction module to simulate the results of interactions on 3D objects, and a functionality prediction module to evaluate the functionality and choose the correct fix. Experimental results show that our framework outperforms baseline models by a large margin, and can generalize well to objects with similar interaction types.
ComPhy: Compositional Physical Reasoning of Objects and Events from Videos
May 02, 2022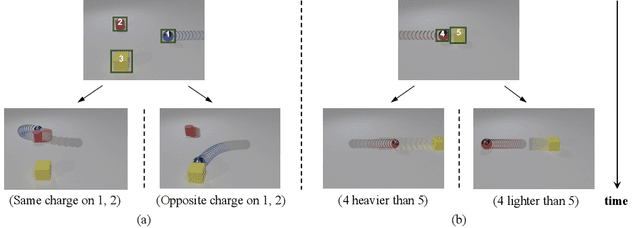


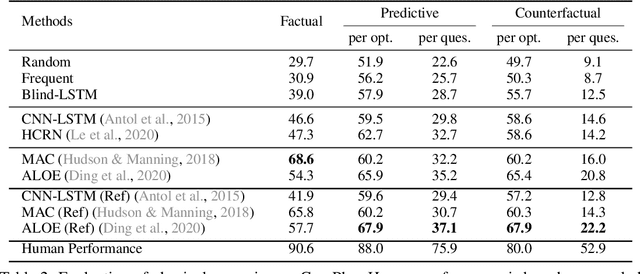
Objects' motions in nature are governed by complex interactions and their properties. While some properties, such as shape and material, can be identified via the object's visual appearances, others like mass and electric charge are not directly visible. The compositionality between the visible and hidden properties poses unique challenges for AI models to reason from the physical world, whereas humans can effortlessly infer them with limited observations. Existing studies on video reasoning mainly focus on visually observable elements such as object appearance, movement, and contact interaction. In this paper, we take an initial step to highlight the importance of inferring the hidden physical properties not directly observable from visual appearances, by introducing the Compositional Physical Reasoning (ComPhy) dataset. For a given set of objects, ComPhy includes few videos of them moving and interacting under different initial conditions. The model is evaluated based on its capability to unravel the compositional hidden properties, such as mass and charge, and use this knowledge to answer a set of questions posted on one of the videos. Evaluation results of several state-of-the-art video reasoning models on ComPhy show unsatisfactory performance as they fail to capture these hidden properties. We further propose an oracle neural-symbolic framework named Compositional Physics Learner (CPL), combining visual perception, physical property learning, dynamic prediction, and symbolic execution into a unified framework. CPL can effectively identify objects' physical properties from their interactions and predict their dynamics to answer questions.
Learning Neural Acoustic Fields
Apr 04, 2022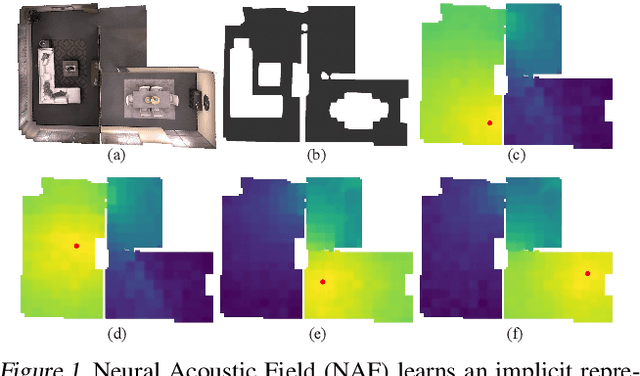
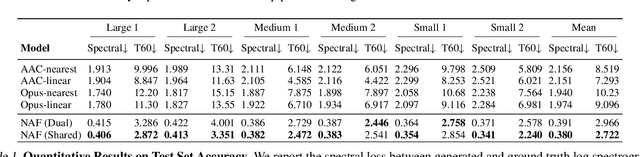
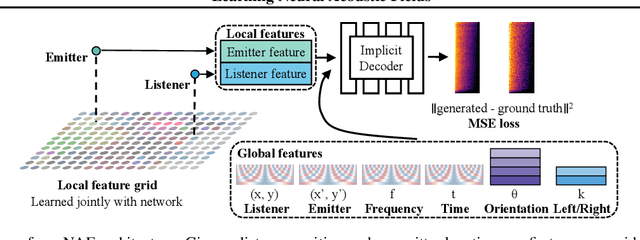
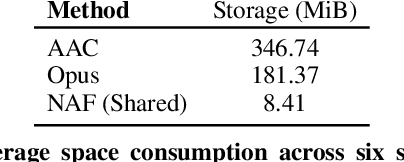
Our environment is filled with rich and dynamic acoustic information. When we walk into a cathedral, the reverberations as much as appearance inform us of the sanctuary's wide open space. Similarly, as an object moves around us, we expect the sound emitted to also exhibit this movement. While recent advances in learned implicit functions have led to increasingly higher quality representations of the visual world, there have not been commensurate advances in learning spatial auditory representations. To address this gap, we introduce Neural Acoustic Fields (NAFs), an implicit representation that captures how sounds propagate in a physical scene. By modeling acoustic propagation in a scene as a linear time-invariant system, NAFs learn to continuously map all emitter and listener location pairs to a neural impulse response function that can then be applied to arbitrary sounds. We demonstrate that the continuous nature of NAFs enables us to render spatial acoustics for a listener at an arbitrary location, and can predict sound propagation at novel locations. We further show that the representation learned by NAFs can help improve visual learning with sparse views. Finally, we show that a representation informative of scene structure emerges during the learning of NAFs.
DiffSkill: Skill Abstraction from Differentiable Physics for Deformable Object Manipulations with Tools
Mar 31, 2022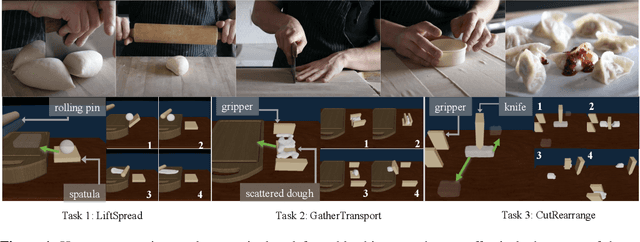
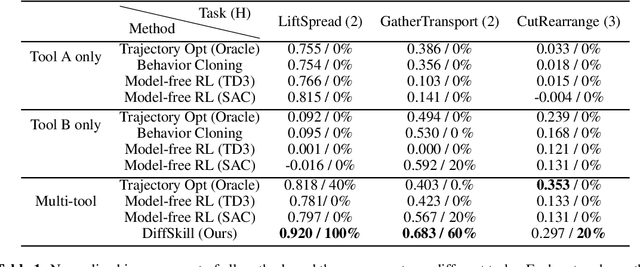
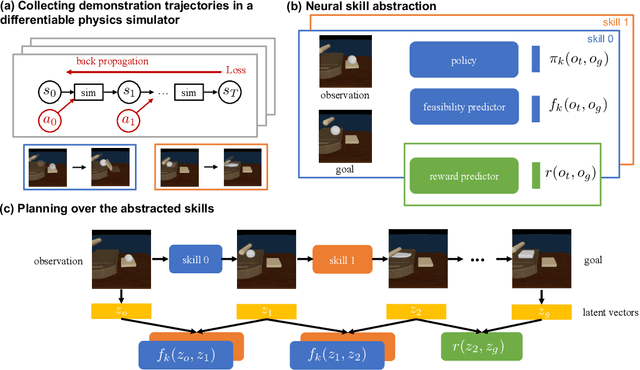
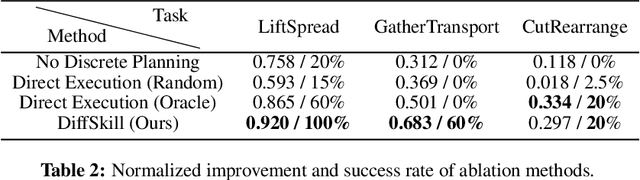
We consider the problem of sequential robotic manipulation of deformable objects using tools. Previous works have shown that differentiable physics simulators provide gradients to the environment state and help trajectory optimization to converge orders of magnitude faster than model-free reinforcement learning algorithms for deformable object manipulation. However, such gradient-based trajectory optimization typically requires access to the full simulator states and can only solve short-horizon, single-skill tasks due to local optima. In this work, we propose a novel framework, named DiffSkill, that uses a differentiable physics simulator for skill abstraction to solve long-horizon deformable object manipulation tasks from sensory observations. In particular, we first obtain short-horizon skills using individual tools from a gradient-based optimizer, using the full state information in a differentiable simulator; we then learn a neural skill abstractor from the demonstration trajectories which takes RGBD images as input. Finally, we plan over the skills by finding the intermediate goals and then solve long-horizon tasks. We show the advantages of our method in a new set of sequential deformable object manipulation tasks compared to previous reinforcement learning algorithms and compared to the trajectory optimizer.
FALCON: Fast Visual Concept Learning by Integrating Images, Linguistic descriptions, and Conceptual Relations
Mar 30, 2022
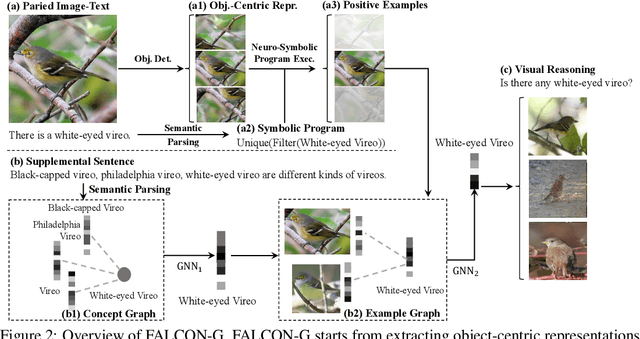
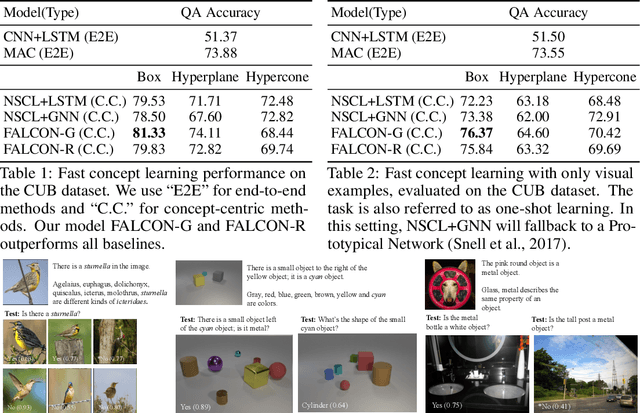
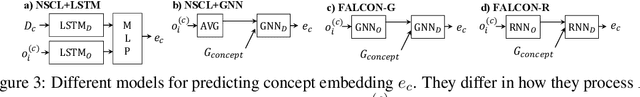
We present a meta-learning framework for learning new visual concepts quickly, from just one or a few examples, guided by multiple naturally occurring data streams: simultaneously looking at images, reading sentences that describe the objects in the scene, and interpreting supplemental sentences that relate the novel concept with other concepts. The learned concepts support downstream applications, such as answering questions by reasoning about unseen images. Our model, namely FALCON, represents individual visual concepts, such as colors and shapes, as axis-aligned boxes in a high-dimensional space (the "box embedding space"). Given an input image and its paired sentence, our model first resolves the referential expression in the sentence and associates the novel concept with particular objects in the scene. Next, our model interprets supplemental sentences to relate the novel concept with other known concepts, such as "X has property Y" or "X is a kind of Y". Finally, it infers an optimal box embedding for the novel concept that jointly 1) maximizes the likelihood of the observed instances in the image, and 2) satisfies the relationships between the novel concepts and the known ones. We demonstrate the effectiveness of our model on both synthetic and real-world datasets.
Linking Emergent and Natural Languages via Corpus Transfer
Mar 24, 2022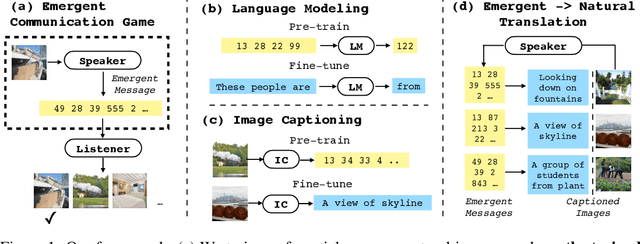
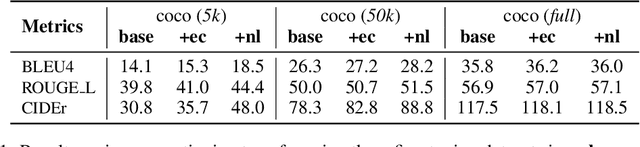
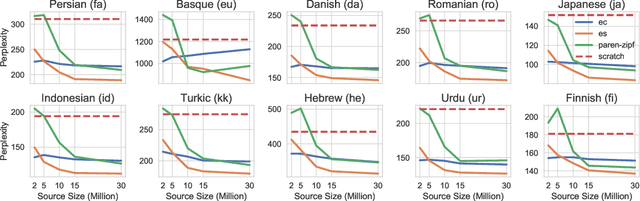
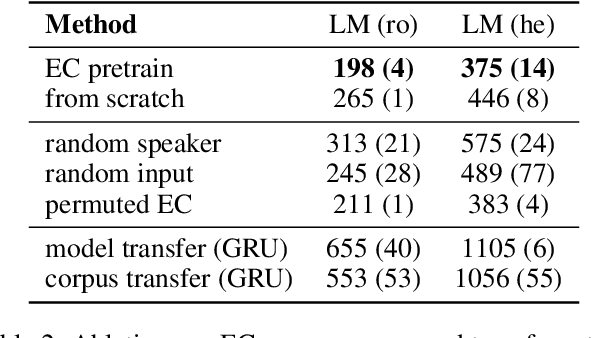
The study of language emergence aims to understand how human languages are shaped by perceptual grounding and communicative intent. Computational approaches to emergent communication (EC) predominantly consider referential games in limited domains and analyze the learned protocol within the game framework. As a result, it remains unclear how the emergent languages from these settings connect to natural languages or provide benefits in real-world language processing tasks, where statistical models trained on large text corpora dominate. In this work, we propose a novel way to establish such a link by corpus transfer, i.e. pretraining on a corpus of emergent language for downstream natural language tasks, which is in contrast to prior work that directly transfers speaker and listener parameters. Our approach showcases non-trivial transfer benefits for two different tasks -- language modeling and image captioning. For example, in a low-resource setup (modeling 2 million natural language tokens), pre-training on an emergent language corpus with just 2 million tokens reduces model perplexity by $24.6\%$ on average across ten natural languages. We also introduce a novel metric to predict the transferability of an emergent language by translating emergent messages to natural language captions grounded on the same images. We find that our translation-based metric highly correlates with the downstream performance on modeling natural languages (for instance $\rho=0.83$ on Hebrew), while topographic similarity, a popular metric in previous work, shows surprisingly low correlation ($\rho=0.003$), hinting that simple properties like attribute disentanglement from synthetic domains might not capture the full complexities of natural language. Our findings also indicate potential benefits of moving language emergence forward with natural language resources and models.
Grammar-Based Grounded Lexicon Learning
Feb 17, 2022
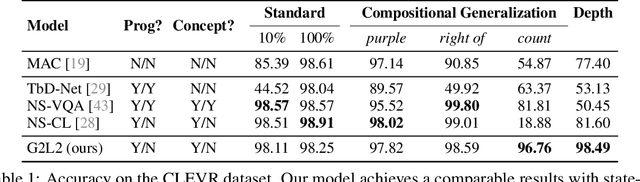
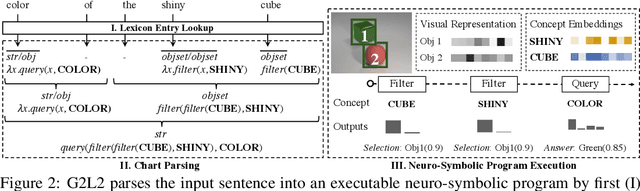
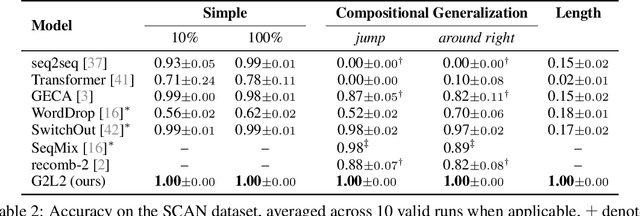
We present Grammar-Based Grounded Lexicon Learning (G2L2), a lexicalist approach toward learning a compositional and grounded meaning representation of language from grounded data, such as paired images and texts. At the core of G2L2 is a collection of lexicon entries, which map each word to a tuple of a syntactic type and a neuro-symbolic semantic program. For example, the word shiny has a syntactic type of adjective; its neuro-symbolic semantic program has the symbolic form {\lambda}x. filter(x, SHINY), where the concept SHINY is associated with a neural network embedding, which will be used to classify shiny objects. Given an input sentence, G2L2 first looks up the lexicon entries associated with each token. It then derives the meaning of the sentence as an executable neuro-symbolic program by composing lexical meanings based on syntax. The recovered meaning programs can be executed on grounded inputs. To facilitate learning in an exponentially-growing compositional space, we introduce a joint parsing and expected execution algorithm, which does local marginalization over derivations to reduce the training time. We evaluate G2L2 on two domains: visual reasoning and language-driven navigation. Results show that G2L2 can generalize from small amounts of data to novel compositions of words.
DURableVS: Data-efficient Unsupervised Recalibrating Visual Servoing via online learning in a structured generative model
Feb 08, 2022
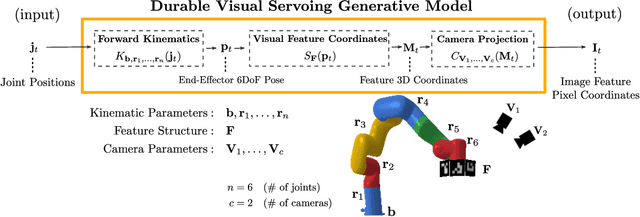
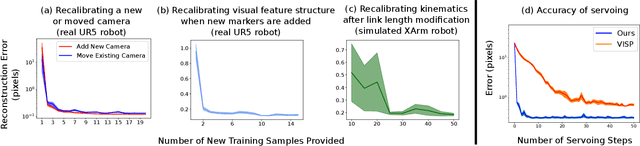

Visual servoing enables robotic systems to perform accurate closed-loop control, which is required in many applications. However, existing methods either require precise calibration of the robot kinematic model and cameras or use neural architectures that require large amounts of data to train. In this work, we present a method for unsupervised learning of visual servoing that does not require any prior calibration and is extremely data-efficient. Our key insight is that visual servoing does not depend on identifying the veridical kinematic and camera parameters, but instead only on an accurate generative model of image feature observations from the joint positions of the robot. We demonstrate that with our model architecture and learning algorithm, we can consistently learn accurate models from less than 50 training samples (which amounts to less than 1 min of unsupervised data collection), and that such data-efficient learning is not possible with standard neural architectures. Further, we show that by using the generative model in the loop and learning online, we can enable a robotic system to recover from calibration errors and to detect and quickly adapt to possibly unexpected changes in the robot-camera system (e.g. bumped camera, new objects).
PTR: A Benchmark for Part-based Conceptual, Relational, and Physical Reasoning
Dec 09, 2021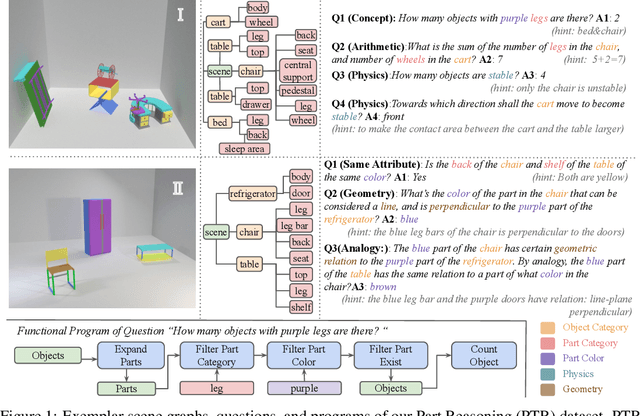
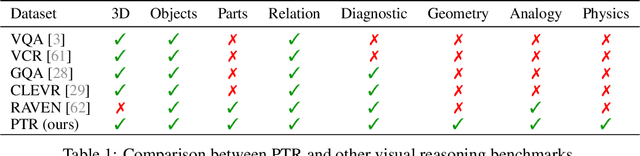
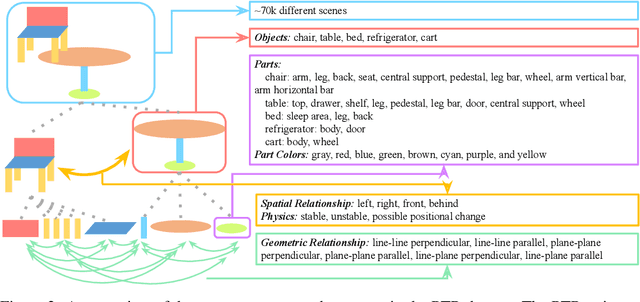
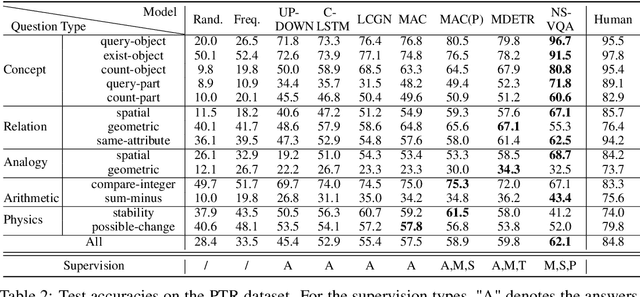
A critical aspect of human visual perception is the ability to parse visual scenes into individual objects and further into object parts, forming part-whole hierarchies. Such composite structures could induce a rich set of semantic concepts and relations, thus playing an important role in the interpretation and organization of visual signals as well as for the generalization of visual perception and reasoning. However, existing visual reasoning benchmarks mostly focus on objects rather than parts. Visual reasoning based on the full part-whole hierarchy is much more challenging than object-centric reasoning due to finer-grained concepts, richer geometry relations, and more complex physics. Therefore, to better serve for part-based conceptual, relational and physical reasoning, we introduce a new large-scale diagnostic visual reasoning dataset named PTR. PTR contains around 70k RGBD synthetic images with ground truth object and part level annotations regarding semantic instance segmentation, color attributes, spatial and geometric relationships, and certain physical properties such as stability. These images are paired with 700k machine-generated questions covering various types of reasoning types, making them a good testbed for visual reasoning models. We examine several state-of-the-art visual reasoning models on this dataset and observe that they still make many surprising mistakes in situations where humans can easily infer the correct answer. We believe this dataset will open up new opportunities for part-based reasoning.