 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuava: An Effective and Universal Harness for Embodied Manipulation
Jun 16, 2026Language models trained on large-scale vision-language data have demonstrated strong potential for embodied agents. Harnessing models through embodied tools use offers a promising alternative to end-to-end vision-language-action systems by combining high-level reasoning with external modules for perception, planning, and control. However, it remains unclear what makes an effective harness for embodied manipulation, and to what extent such a harness can unlock embodied capabilities in a wide range of reasoning models. In this work, we present Guava, a harness framework for embodied tool use developed through systematic exploration of the design space of agent workflows, action spaces, and observation spaces. Our study identifies three key ingredients for effective embodied agents: iterative perception-reasoning-action loops, semantic action abstractions, and multimodal observations. To understand whether these design principles are universal even to small models, we develop an end-to-end training pipeline that distills embodied manipulation capabilities into a 4B open-source model using fewer than 2K trajectories collected entirely in simulation. Experimental results in both simulation and real-world environments show performance comparable to frontier proprietary models while exhibiting strong generalization to unseen objects, novel instructions, and long-horizon tasks. Results suggest that a well-designed harness can serve as a scalable, model-agnostic interface for embodied manipulation, enabling strong emergent embodied capabilities in compact open-source models with minimal training data.
V-GRPO: Online Reinforcement Learning for Denoising Generative Models Is Easier than You Think
Apr 25, 2026Aligning denoising generative models with human preferences or verifiable rewards remains a key challenge. While policy-gradient online reinforcement learning (RL) offers a principled post-training framework, its direct application is hindered by the intractable likelihoods of these models. Prior work therefore either optimizes an induced Markov decision process (MDP) over sampling trajectories, which is stable but inefficient, or uses likelihood surrogates based on the diffusion evidence lower bound (ELBO), which have so far underperformed on visual generation. Our key insight is that the ELBO-based approach can, in fact, be made both stable and efficient. By reducing surrogate variance and controlling gradient steps, we show that this approach can beat MDP-based methods. To this end, we introduce Variational GRPO (V-GRPO), a method that integrates ELBO-based surrogates with the Group Relative Policy Optimization (GRPO) algorithm, alongside a set of simple yet essential techniques. Our method is easy to implement, aligns with pretraining objectives, and avoids the limitations of MDP-based methods. V-GRPO achieves state-of-the-art performance in text-to-image synthesis, while delivering a $2\times$ speedup over MixGRPO and a $3\times$ speedup over DiffusionNFT.
Adversarial Game-Theoretic Algorithm for Dexterous Grasp Synthesis
Nov 08, 2025For many complex tasks, multi-finger robot hands are poised to revolutionize how we interact with the world, but reliably grasping objects remains a significant challenge. We focus on the problem of synthesizing grasps for multi-finger robot hands that, given a target object's geometry and pose, computes a hand configuration. Existing approaches often struggle to produce reliable grasps that sufficiently constrain object motion, leading to instability under disturbances and failed grasps. A key reason is that during grasp generation, they typically focus on resisting a single wrench, while ignoring the object's potential for adversarial movements, such as escaping. We propose a new grasp-synthesis approach that explicitly captures and leverages the adversarial object motion in grasp generation by formulating the problem as a two-player game. One player controls the robot to generate feasible grasp configurations, while the other adversarially controls the object to seek motions that attempt to escape from the grasp. Simulation experiments on various robot platforms and target objects show that our approach achieves a success rate of 75.78%, up to 19.61% higher than the state-of-the-art baseline. The two-player game mechanism improves the grasping success rate by 27.40% over the method without the game formulation. Our approach requires only 0.28-1.04 seconds on average to generate a grasp configuration, depending on the robot platform, making it suitable for real-world deployment. In real-world experiments, our approach achieves an average success rate of 85.0% on ShadowHand and 87.5% on LeapHand, which confirms its feasibility and effectiveness in real robot setups.
Learning Compositional Behaviors from Demonstration and Language
May 28, 2025
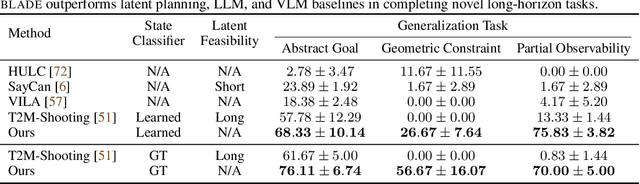
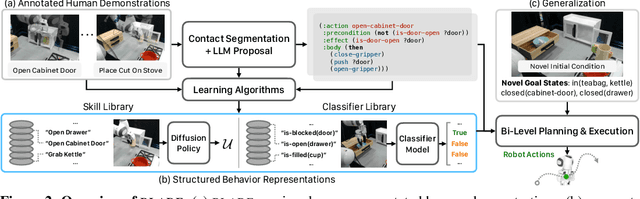

We introduce Behavior from Language and Demonstration (BLADE), a framework for long-horizon robotic manipulation by integrating imitation learning and model-based planning. BLADE leverages language-annotated demonstrations, extracts abstract action knowledge from large language models (LLMs), and constructs a library of structured, high-level action representations. These representations include preconditions and effects grounded in visual perception for each high-level action, along with corresponding controllers implemented as neural network-based policies. BLADE can recover such structured representations automatically, without manually labeled states or symbolic definitions. BLADE shows significant capabilities in generalizing to novel situations, including novel initial states, external state perturbations, and novel goals. We validate the effectiveness of our approach both in simulation and on real robots with a diverse set of objects with articulated parts, partial observability, and geometric constraints.
Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models
May 16, 2025



Accuracy remains a standard metric for evaluating AI systems, but it offers limited insight into how models arrive at their solutions. In this work, we introduce a benchmark based on brainteasers written in long narrative form to probe more deeply into the types of reasoning strategies that models use. Brainteasers are well-suited for this goal because they can be solved with multiple approaches, such as a few-step solution that uses a creative insight or a longer solution that uses more brute force. We investigate large language models (LLMs) across multiple layers of reasoning, focusing not only on correctness but also on the quality and creativity of their solutions. We investigate many aspects of the reasoning process: (1) semantic parsing of the brainteasers into precise mathematical competition style formats; (2) generating solutions from these mathematical forms; (3) self-correcting solutions based on gold solutions; (4) producing step-by-step sketches of solutions; and (5) making use of hints. We find that LLMs are in many cases able to find creative, insightful solutions to brainteasers, suggesting that they capture some of the capacities needed to solve novel problems in creative ways. Nonetheless, there also remain situations where they rely on brute force despite the availability of more efficient, creative solutions, highlighting a potential direction for improvement in the reasoning abilities of LLMs.
Neuro-Symbolic Concepts
May 09, 2025



This article presents a concept-centric paradigm for building agents that can learn continually and reason flexibly. The concept-centric agent utilizes a vocabulary of neuro-symbolic concepts. These concepts, such as object, relation, and action concepts, are grounded on sensory inputs and actuation outputs. They are also compositional, allowing for the creation of novel concepts through their structural combination. To facilitate learning and reasoning, the concepts are typed and represented using a combination of symbolic programs and neural network representations. Leveraging such neuro-symbolic concepts, the agent can efficiently learn and recombine them to solve various tasks across different domains, ranging from 2D images, videos, 3D scenes, and robotic manipulation tasks. This concept-centric framework offers several advantages, including data efficiency, compositional generalization, continual learning, and zero-shot transfer.
Generating Fine Details of Entity Interactions
Apr 11, 2025Images not only depict objects but also encapsulate rich interactions between them. However, generating faithful and high-fidelity images involving multiple entities interacting with each other, is a long-standing challenge. While pre-trained text-to-image models are trained on large-scale datasets to follow diverse text instructions, they struggle to generate accurate interactions, likely due to the scarcity of training data for uncommon object interactions. This paper introduces InterActing, an interaction-focused dataset with 1000 fine-grained prompts covering three key scenarios: (1) functional and action-based interactions, (2) compositional spatial relationships, and (3) multi-subject interactions. To address interaction generation challenges, we propose a decomposition-augmented refinement procedure. Our approach, DetailScribe, built on Stable Diffusion 3.5, leverages LLMs to decompose interactions into finer-grained concepts, uses a VLM to critique generated images, and applies targeted interventions within the diffusion process in refinement. Automatic and human evaluations show significantly improved image quality, demonstrating the potential of enhanced inference strategies. Our dataset and code are available at https://concepts-ai.com/p/detailscribe/ to facilitate future exploration of interaction-rich image generation.
One-Shot Manipulation Strategy Learning by Making Contact Analogies
Nov 14, 2024



We present a novel approach, MAGIC (manipulation analogies for generalizable intelligent contacts), for one-shot learning of manipulation strategies with fast and extensive generalization to novel objects. By leveraging a reference action trajectory, MAGIC effectively identifies similar contact points and sequences of actions on novel objects to replicate a demonstrated strategy, such as using different hooks to retrieve distant objects of different shapes and sizes. Our method is based on a two-stage contact-point matching process that combines global shape matching using pretrained neural features with local curvature analysis to ensure precise and physically plausible contact points. We experiment with three tasks including scooping, hanging, and hooking objects. MAGIC demonstrates superior performance over existing methods, achieving significant improvements in runtime speed and generalization to different object categories. Website: https://magic-2024.github.io/ .
Keypoint Abstraction using Large Models for Object-Relative Imitation Learning
Oct 30, 2024



Generalization to novel object configurations and instances across diverse tasks and environments is a critical challenge in robotics. Keypoint-based representations have been proven effective as a succinct representation for capturing essential object features, and for establishing a reference frame in action prediction, enabling data-efficient learning of robot skills. However, their manual design nature and reliance on additional human labels limit their scalability. In this paper, we propose KALM, a framework that leverages large pre-trained vision-language models (LMs) to automatically generate task-relevant and cross-instance consistent keypoints. KALM distills robust and consistent keypoints across views and objects by generating proposals using LMs and verifies them against a small set of robot demonstration data. Based on the generated keypoints, we can train keypoint-conditioned policy models that predict actions in keypoint-centric frames, enabling robots to generalize effectively across varying object poses, camera views, and object instances with similar functional shapes. Our method demonstrates strong performance in the real world, adapting to different tasks and environments from only a handful of demonstrations while requiring no additional labels. Website: https://kalm-il.github.io/
Learning Linear Attention in Polynomial Time
Oct 14, 2024Previous research has explored the computational expressivity of Transformer models in simulating Boolean circuits or Turing machines. However, the learnability of these simulators from observational data has remained an open question. Our study addresses this gap by providing the first polynomial-time learnability results (specifically strong, agnostic PAC learning) for single-layer Transformers with linear attention. We show that linear attention may be viewed as a linear predictor in a suitably defined RKHS. As a consequence, the problem of learning any linear transformer may be converted into the problem of learning an ordinary linear predictor in an expanded feature space, and any such predictor may be converted back into a multiheaded linear transformer. Moving to generalization, we show how to efficiently identify training datasets for which every empirical risk minimizer is equivalent (up to trivial symmetries) to the linear Transformer that generated the data, thereby guaranteeing the learned model will correctly generalize across all inputs. Finally, we provide examples of computations expressible via linear attention and therefore polynomial-time learnable, including associative memories, finite automata, and a class of Universal Turing Machine (UTMs) with polynomially bounded computation histories. We empirically validate our theoretical findings on three tasks: learning random linear attention networks, key--value associations, and learning to execute finite automata. Our findings bridge a critical gap between theoretical expressivity and learnability of Transformers, and show that flexible and general models of computation are efficiently learnable.