 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervision-Guided Codebooks for Masked Prediction in Speech Pre-training
Jun 21, 2022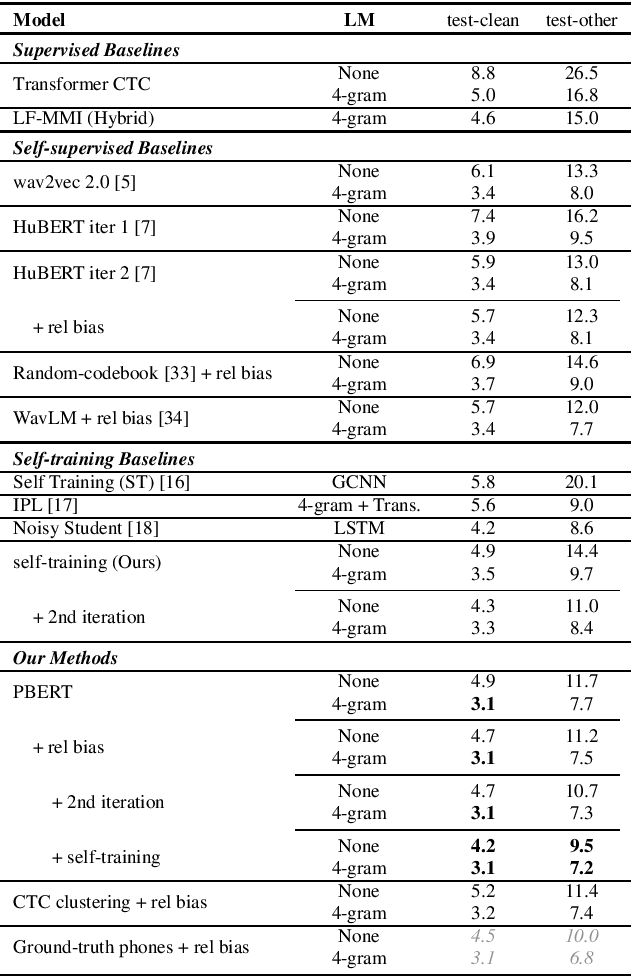
Recently, masked prediction pre-training has seen remarkable progress in self-supervised learning (SSL) for speech recognition. It usually requires a codebook obtained in an unsupervised way, making it less accurate and difficult to interpret. We propose two supervision-guided codebook generation approaches to improve automatic speech recognition (ASR) performance and also the pre-training efficiency, either through decoding with a hybrid ASR system to generate phoneme-level alignments (named PBERT), or performing clustering on the supervised speech features extracted from an end-to-end CTC model (named CTC clustering). Both the hybrid and CTC models are trained on the same small amount of labeled speech as used in fine-tuning. Experiments demonstrate significant superiority of our methods to various SSL and self-training baselines, with up to 17.0% relative WER reduction. Our pre-trained models also show good transferability in a non-ASR speech task.
The YiTrans End-to-End Speech Translation System for IWSLT 2022 Offline Shared Task
Jun 14, 2022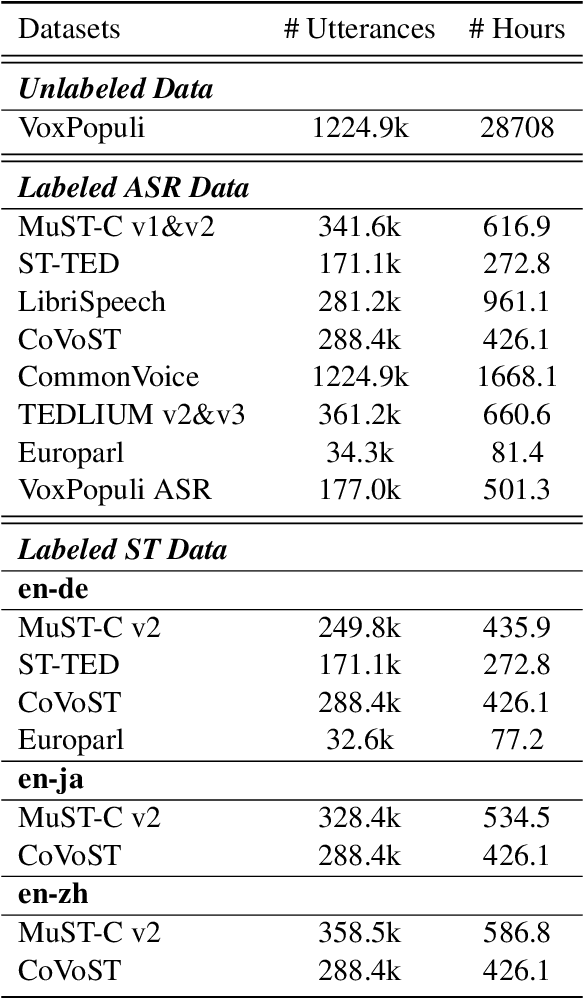
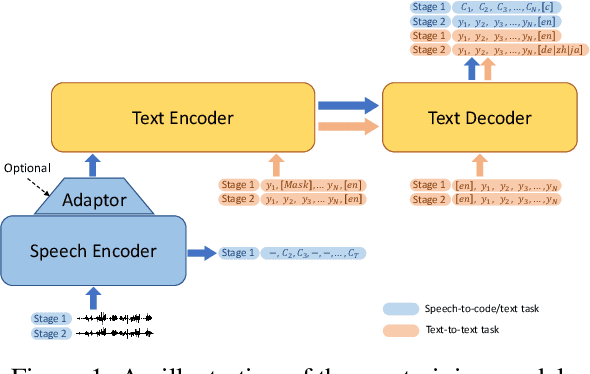
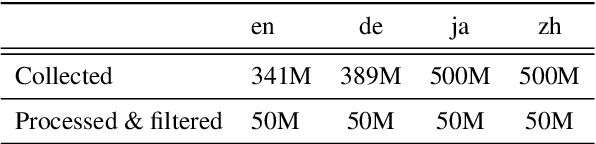
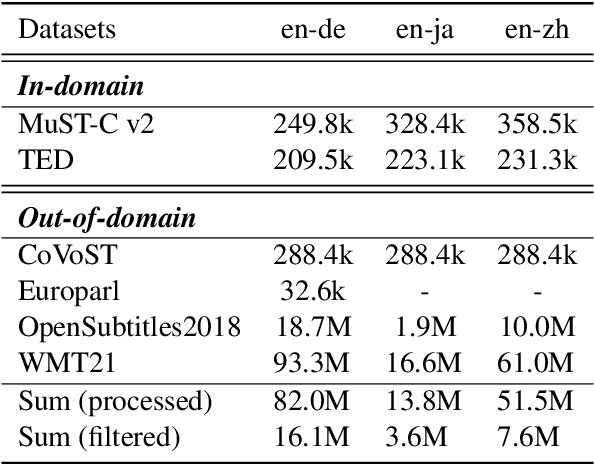
This paper describes the submission of our end-to-end YiTrans speech translation system for the IWSLT 2022 offline task, which translates from English audio to German, Chinese, and Japanese. The YiTrans system is built on large-scale pre-trained encoder-decoder models. More specifically, we first design a multi-stage pre-training strategy to build a multi-modality model with a large amount of labeled and unlabeled data. We then fine-tune the corresponding components of the model for the downstream speech translation tasks. Moreover, we make various efforts to improve performance, such as data filtering, data augmentation, speech segmentation, model ensemble, and so on. Experimental results show that our YiTrans system obtains a significant improvement than the strong baseline on three translation directions, and it achieves +5.2 BLEU improvements over last year's optimal end-to-end system on tst2021 English-German. Our final submissions rank first on English-German and English-Chinese end-to-end systems in terms of the automatic evaluation metric. We make our code and models publicly available.
Ultra Fast Speech Separation Model with Teacher Student Learning
Apr 27, 2022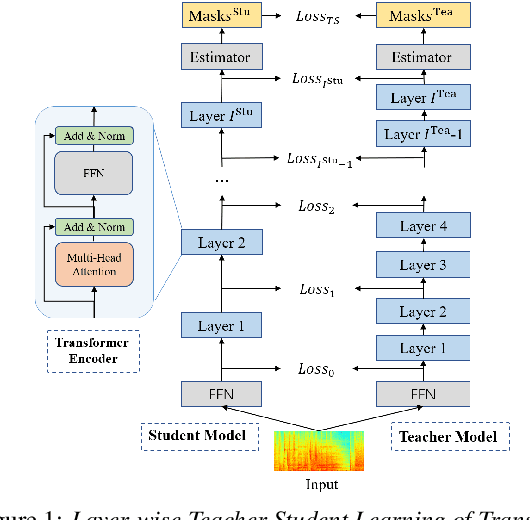
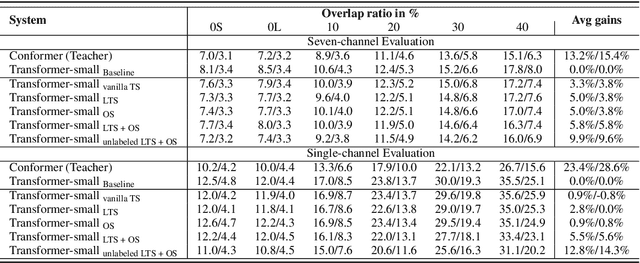
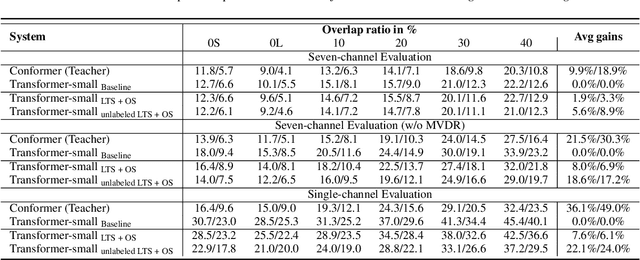
Transformer has been successfully applied to speech separation recently with its strong long-dependency modeling capacity using a self-attention mechanism. However, Transformer tends to have heavy run-time costs due to the deep encoder layers, which hinders its deployment on edge devices. A small Transformer model with fewer encoder layers is preferred for computational efficiency, but it is prone to performance degradation. In this paper, an ultra fast speech separation Transformer model is proposed to achieve both better performance and efficiency with teacher student learning (T-S learning). We introduce layer-wise T-S learning and objective shifting mechanisms to guide the small student model to learn intermediate representations from the large teacher model. Compared with the small Transformer model trained from scratch, the proposed T-S learning method reduces the word error rate (WER) by more than 5% for both multi-channel and single-channel speech separation on LibriCSS dataset. Utilizing more unlabeled speech data, our ultra fast speech separation models achieve more than 10% relative WER reduction.
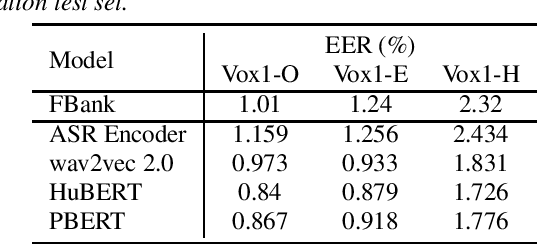
Why does Self-Supervised Learning for Speech Recognition Benefit Speaker Recognition?
Apr 27, 2022
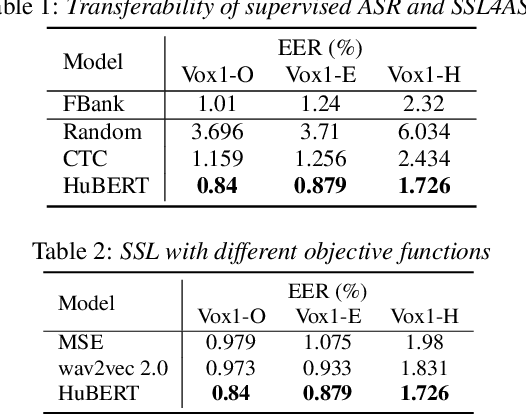
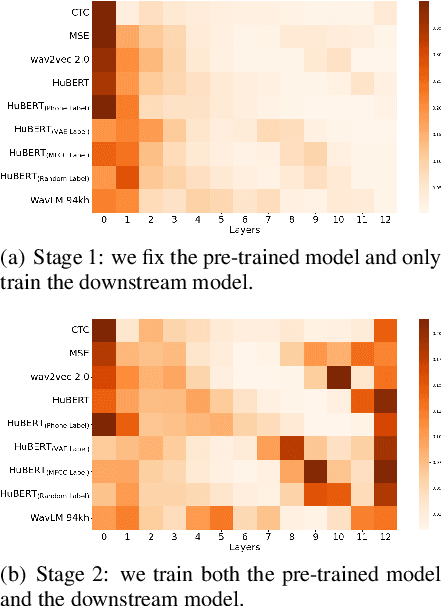
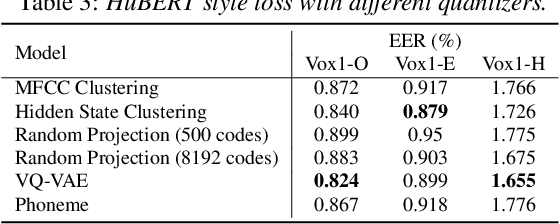
Recently, self-supervised learning (SSL) has demonstrated strong performance in speaker recognition, even if the pre-training objective is designed for speech recognition. In this paper, we study which factor leads to the success of self-supervised learning on speaker-related tasks, e.g. speaker verification (SV), through a series of carefully designed experiments. Our empirical results on the Voxceleb-1 dataset suggest that the benefit of SSL to SV task is from a combination of mask speech prediction loss, data scale, and model size, while the SSL quantizer has a minor impact. We further employ the integrated gradients attribution method and loss landscape visualization to understand the effectiveness of self-supervised learning for speaker recognition performance.
Large-Scale Streaming End-to-End Speech Translation with Neural Transducers
Apr 11, 2022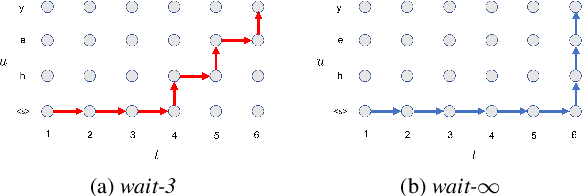
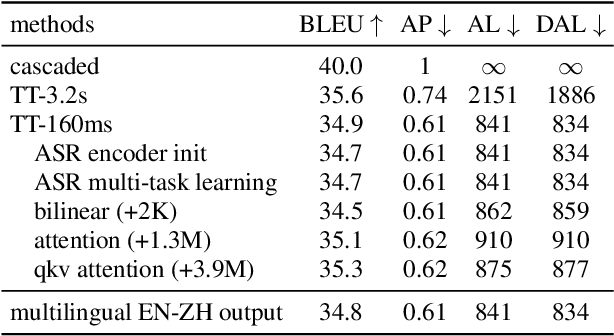
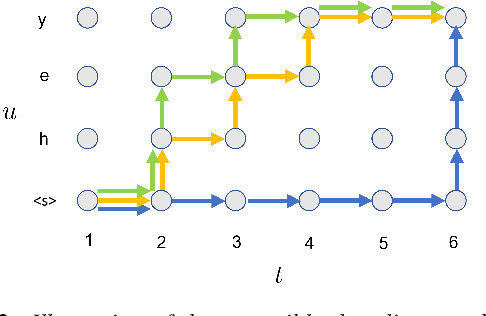
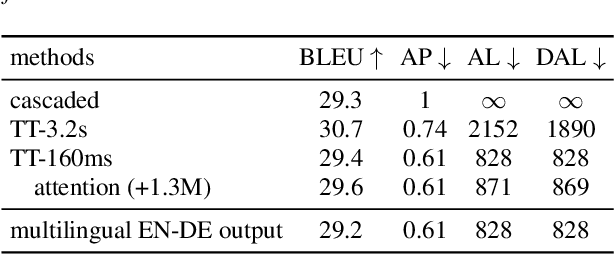
Neural transducers have been widely used in automatic speech recognition (ASR). In this paper, we introduce it to streaming end-to-end speech translation (ST), which aims to convert audio signals to texts in other languages directly. Compared with cascaded ST that performs ASR followed by text-based machine translation (MT), the proposed Transformer transducer (TT)-based ST model drastically reduces inference latency, exploits speech information, and avoids error propagation from ASR to MT. To improve the modeling capacity, we propose attention pooling for the joint network in TT. In addition, we extend TT-based ST to multilingual ST, which generates texts of multiple languages at the same time. Experimental results on a large-scale 50 thousand (K) hours pseudo-labeled training set show that TT-based ST not only significantly reduces inference time but also outperforms non-streaming cascaded ST for English-German translation.
Pre-Training Transformer Decoder for End-to-End ASR Model with Unpaired Speech Data
Mar 31, 2022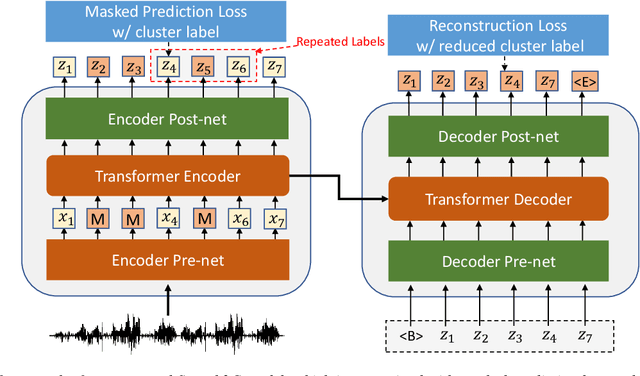
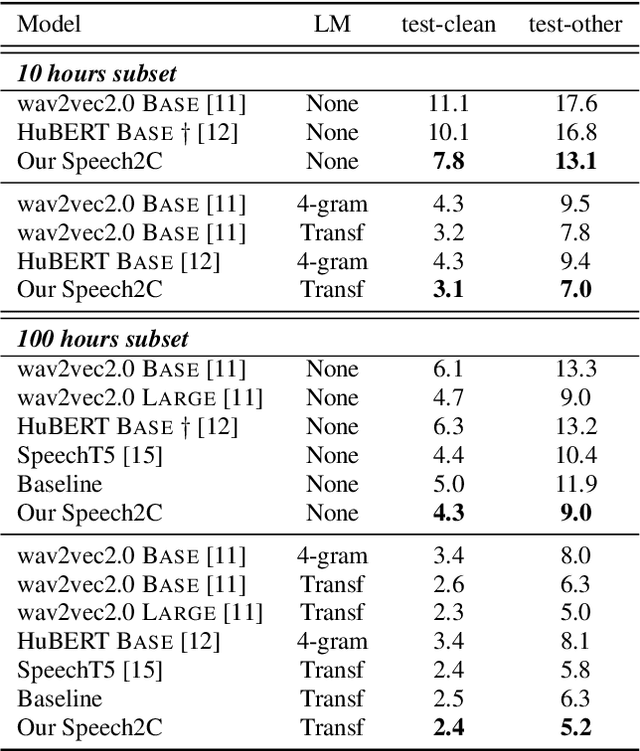

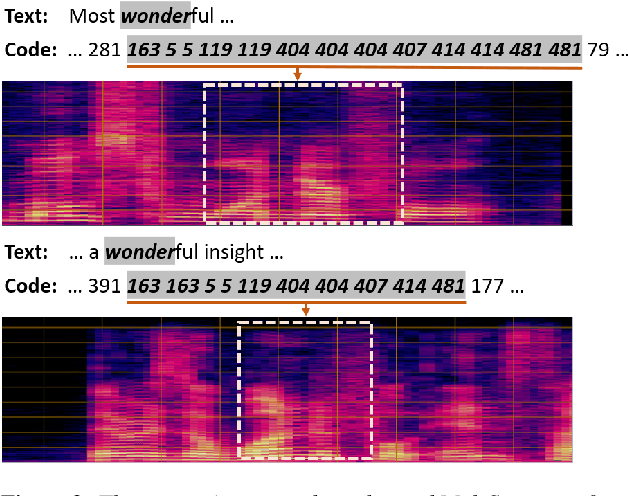
This paper studies a novel pre-training technique with unpaired speech data, Speech2C, for encoder-decoder based automatic speech recognition (ASR). Within a multi-task learning framework, we introduce two pre-training tasks for the encoder-decoder network using acoustic units, i.e., pseudo codes, derived from an offline clustering model. One is to predict the pseudo codes via masked language modeling in encoder output, like HuBERT model, while the other lets the decoder learn to reconstruct pseudo codes autoregressively instead of generating textual scripts. In this way, the decoder learns to reconstruct original speech information with codes before learning to generate correct text. Comprehensive experiments on the LibriSpeech corpus show that the proposed Speech2C can relatively reduce the word error rate (WER) by 19.2% over the method without decoder pre-training, and also outperforms significantly the state-of-the-art wav2vec 2.0 and HuBERT on fine-tuning subsets of 10h and 100h.
Streaming Speaker-Attributed ASR with Token-Level Speaker Embeddings
Mar 30, 2022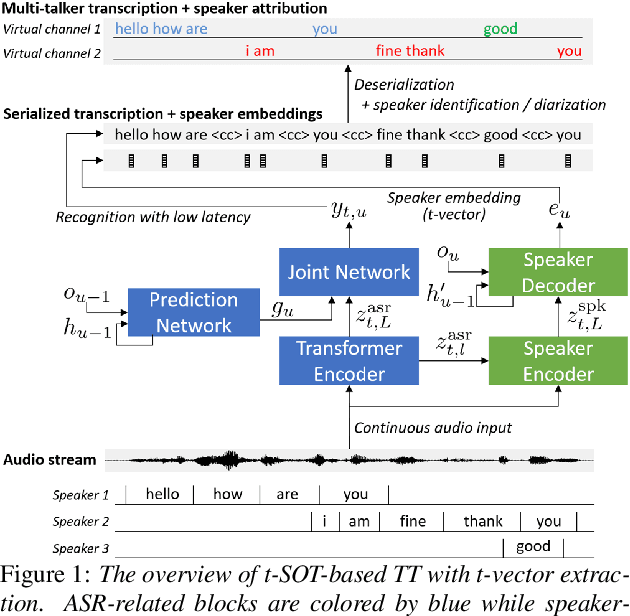
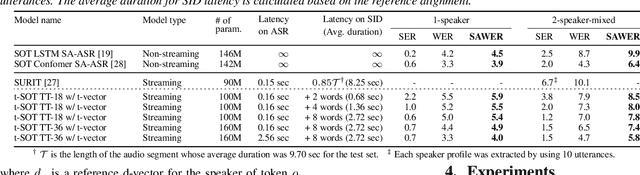
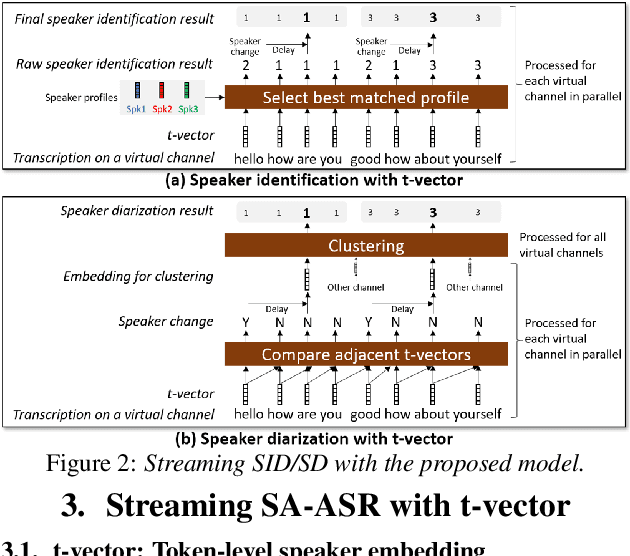
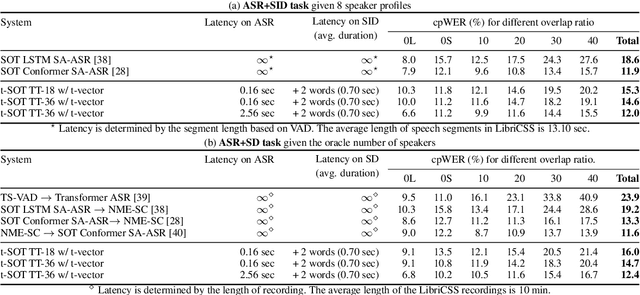
This paper presents a streaming speaker-attributed automatic speech recognition (SA-ASR) model that can recognize "who spoke what" with low latency even when multiple people are speaking simultaneously. Our model is based on token-level serialized output training (t-SOT) which was recently proposed to transcribe multi-talker speech in a streaming fashion. To further recognize speaker identities, we propose an encoder-decoder based speaker embedding extractor that can estimate a speaker representation for each recognized token not only from non-overlapping speech but also from overlapping speech. The proposed speaker embedding, named t-vector, is extracted synchronously with the t-SOT ASR model, enabling joint execution of speaker identification (SID) or speaker diarization (SD) with the multi-talker transcription with low latency. We evaluate the proposed model for a joint task of ASR and SID/SD by using LibriSpeechMix and LibriCSS corpora. The proposed model achieves substantially better accuracy than a prior streaming model and shows comparable or sometimes even superior results to the state-of-the-art offline SA-ASR model.
Towards Contextual Spelling Correction for Customization of End-to-end Speech Recognition Systems
Mar 02, 2022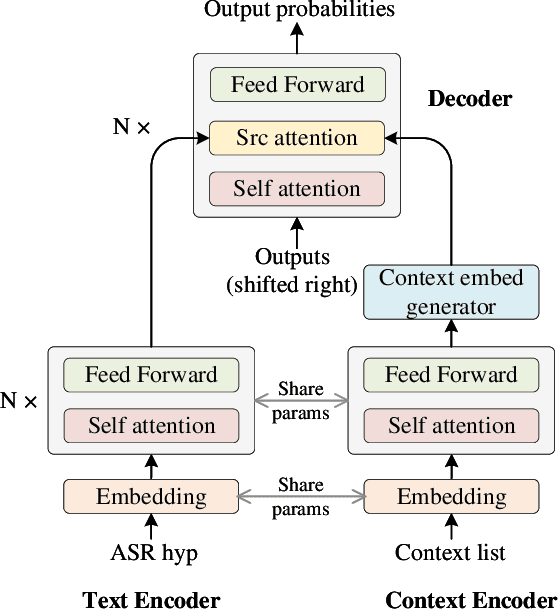
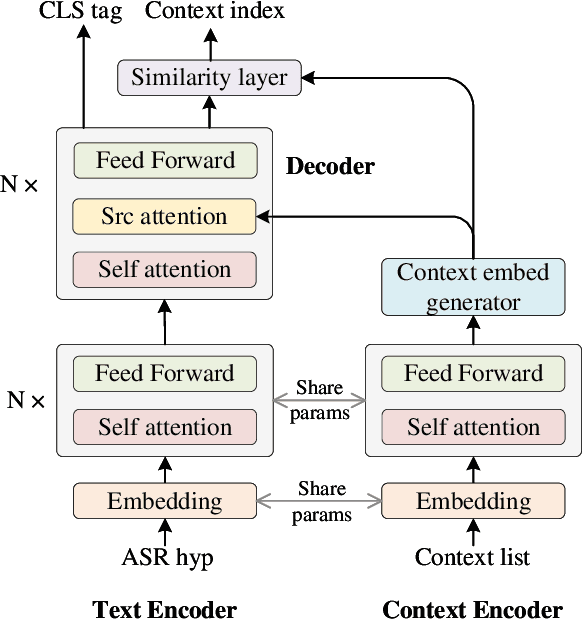
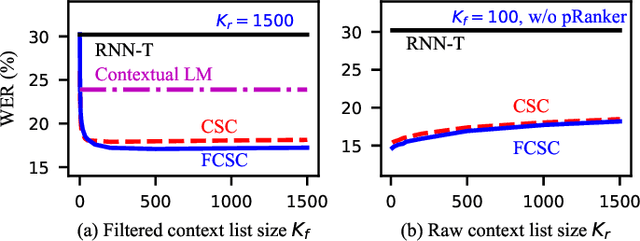
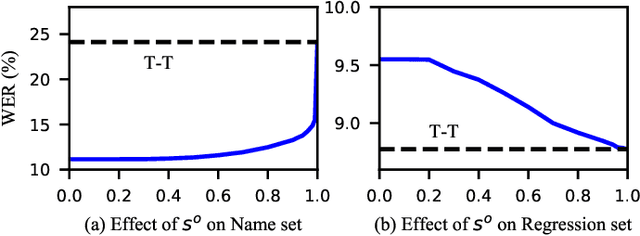
Contextual biasing is an important and challenging task for end-to-end automatic speech recognition (ASR) systems, which aims to achieve better recognition performance by biasing the ASR system to particular context phrases such as person names, music list, proper nouns, etc. Existing methods mainly include contextual LM biasing and adding bias encoder into end-to-end ASR models. In this work, we introduce a novel approach to do contextual biasing by adding a contextual spelling correction model on top of the end-to-end ASR system. We incorporate contextual information into a sequence-to-sequence spelling correction model with a shared context encoder. Our proposed model includes two different mechanisms: autoregressive (AR) and non-autoregressive (NAR). We propose filtering algorithms to handle large-size context lists, and performance balancing mechanisms to control the biasing degree of the model. We demonstrate the proposed model is a general biasing solution which is domain-insensitive and can be adopted in different scenarios. Experiments show that the proposed method achieves as much as 51% relative word error rate (WER) reduction over ASR system and outperforms traditional biasing methods. Compared to the AR solution, the proposed NAR model reduces model size by 43.2% and speeds up inference by 2.1 times.
Streaming Multi-Talker ASR with Token-Level Serialized Output Training
Feb 05, 2022
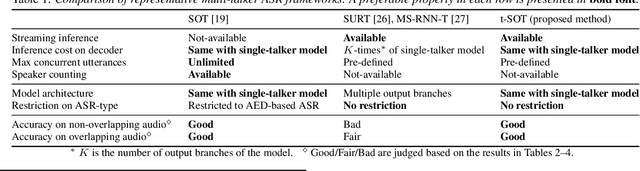
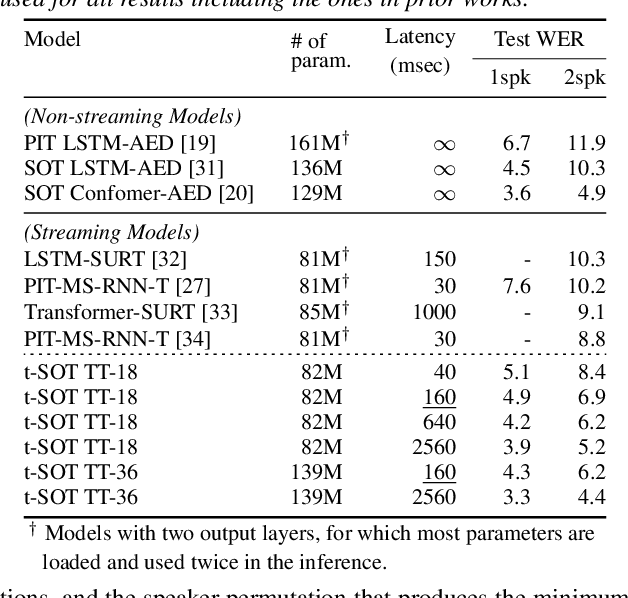
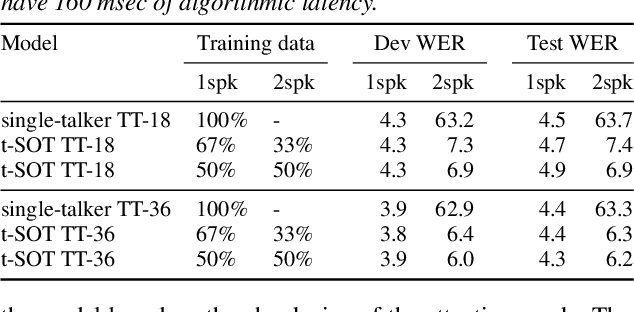
This paper proposes a token-level serialized output training (t-SOT), a novel framework for streaming multi-talker automatic speech recognition (ASR). Unlike existing streaming multi-talker ASR models using multiple output layers, the t-SOT model has only a single output layer that generates recognition tokens (e.g., words, subwords) of multiple speakers in chronological order based on their emission times. A special token that indicates the change of "virtual" output channels is introduced to keep track of the overlapping utterances. Compared to the prior streaming multi-talker ASR models, the t-SOT model has the advantages of less inference cost and a simpler model architecture. Moreover, in our experiments with LibriSpeechMix and LibriCSS datasets, the t-SOT-based transformer transducer model achieves the state-of-the-art word error rates by a significant margin to the prior results. For non-overlapping speech, the t-SOT model is on par with a single-talker ASR model in terms of both accuracy and computational cost, opening the door for deploying one model for both single- and multi-talker scenarios.
Endpoint Detection for Streaming End-to-End Multi-talker ASR
Jan 24, 2022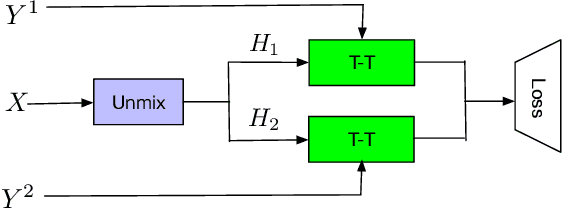
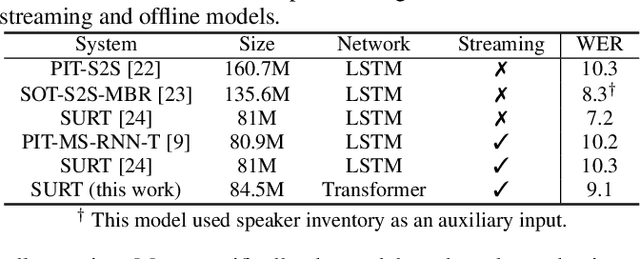
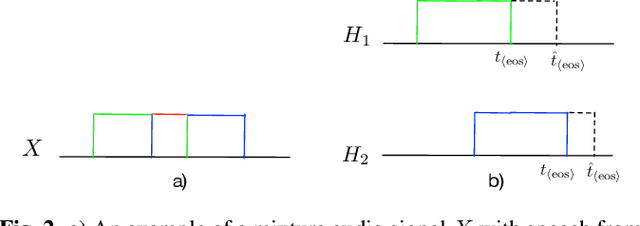
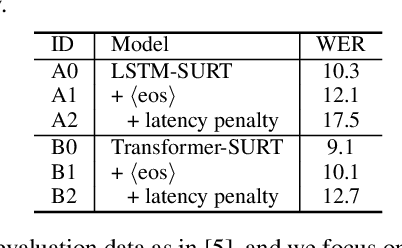
Streaming end-to-end multi-talker speech recognition aims at transcribing the overlapped speech from conversations or meetings with an all-neural model in a streaming fashion, which is fundamentally different from a modular-based approach that usually cascades the speech separation and the speech recognition models trained independently. Previously, we proposed the Streaming Unmixing and Recognition Transducer (SURT) model based on recurrent neural network transducer (RNN-T) for this problem and presented promising results. However, for real applications, the speech recognition system is also required to determine the timestamp when a speaker finishes speaking for prompt system response. This problem, known as endpoint (EP) detection, has not been studied previously for multi-talker end-to-end models. In this work, we address the EP detection problem in the SURT framework by introducing an end-of-sentence token as an output unit, following the practice of single-talker end-to-end models. Furthermore, we also present a latency penalty approach that can significantly cut down the EP detection latency. Our experimental results based on the 2-speaker LibrispeechMix dataset show that the SURT model can achieve promising EP detection without significantly degradation of the recognition accuracy.