 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEAN: Generative Latent Bank for Image Super-Resolution and Beyond
Jul 29, 2022
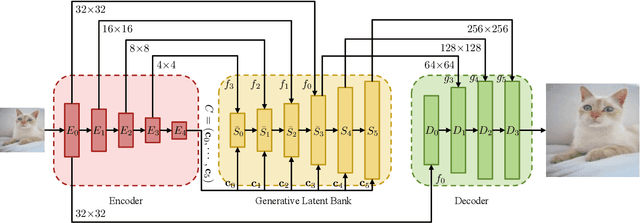
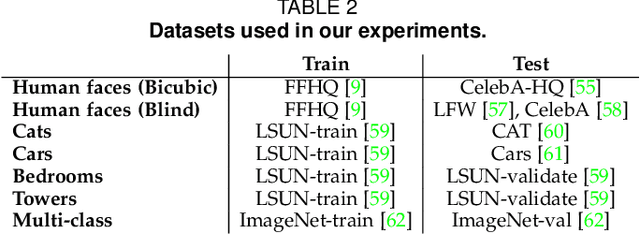
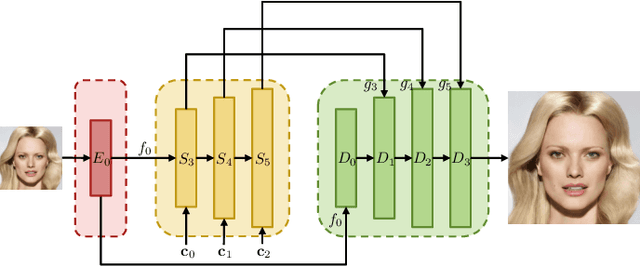
We show that pre-trained Generative Adversarial Networks (GANs) such as StyleGAN and BigGAN can be used as a latent bank to improve the performance of image super-resolution. While most existing perceptual-oriented approaches attempt to generate realistic outputs through learning with adversarial loss, our method, Generative LatEnt bANk (GLEAN), goes beyond existing practices by directly leveraging rich and diverse priors encapsulated in a pre-trained GAN. But unlike prevalent GAN inversion methods that require expensive image-specific optimization at runtime, our approach only needs a single forward pass for restoration. GLEAN can be easily incorporated in a simple encoder-bank-decoder architecture with multi-resolution skip connections. Employing priors from different generative models allows GLEAN to be applied to diverse categories (\eg~human faces, cats, buildings, and cars). We further present a lightweight version of GLEAN, named LightGLEAN, which retains only the critical components in GLEAN. Notably, LightGLEAN consists of only 21% of parameters and 35% of FLOPs while achieving comparable image quality. We extend our method to different tasks including image colorization and blind image restoration, and extensive experiments show that our proposed models perform favorably in comparison to existing methods. Codes and models are available at https://github.com/open-mmlab/mmediting.
ReconfigISP: Reconfigurable Camera Image Processing Pipeline
Sep 10, 2021

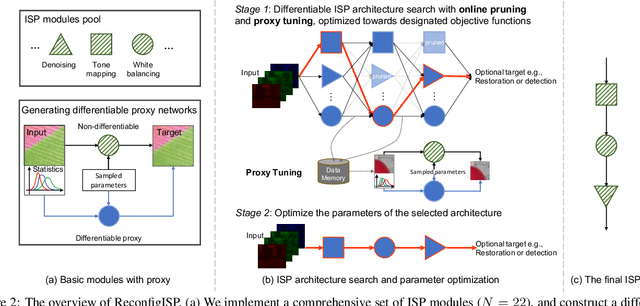
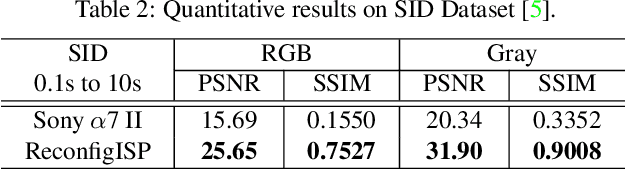
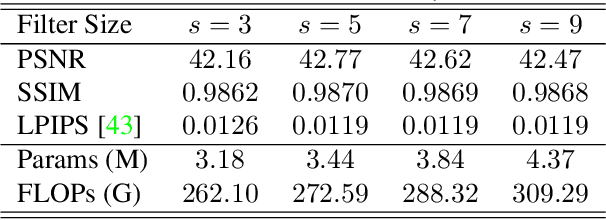
Image Signal Processor (ISP) is a crucial component in digital cameras that transforms sensor signals into images for us to perceive and understand. Existing ISP designs always adopt a fixed architecture, e.g., several sequential modules connected in a rigid order. Such a fixed ISP architecture may be suboptimal for real-world applications, where camera sensors, scenes and tasks are diverse. In this study, we propose a novel Reconfigurable ISP (ReconfigISP) whose architecture and parameters can be automatically tailored to specific data and tasks. In particular, we implement several ISP modules, and enable backpropagation for each module by training a differentiable proxy, hence allowing us to leverage the popular differentiable neural architecture search and effectively search for the optimal ISP architecture. A proxy tuning mechanism is adopted to maintain the accuracy of proxy networks in all cases. Extensive experiments conducted on image restoration and object detection, with different sensors, light conditions and efficiency constraints, validate the effectiveness of ReconfigISP. Only hundreds of parameters need tuning for every task.
Deep Camera Obscura: An Image Restoration Pipeline for Lensless Pinhole Photography
Aug 12, 2021The lensless pinhole camera is perhaps the earliest and simplest form of an imaging system using only a pinhole-sized aperture in place of a lens. They can capture an infinite depth-of-field and offer greater freedom from optical distortion over their lens-based counterparts. However, the inherent limitations of a pinhole system result in lower sharpness from blur caused by optical diffraction and higher noise levels due to low light throughput of the small aperture, requiring very long exposure times to capture well-exposed images. In this paper, we explore an image restoration pipeline using deep learning and domain-knowledge of the pinhole system to enhance the pinhole image quality through a joint denoise and deblur approach. Our approach allows for more practical exposure times for hand-held photography and provides higher image quality, making it more suitable for daily photography compared to other lensless cameras while keeping size and cost low. This opens up the potential of pinhole cameras to be used in smaller devices, such as smartphones.
Lighting the Darkness in the Deep Learning Era
Apr 21, 2021
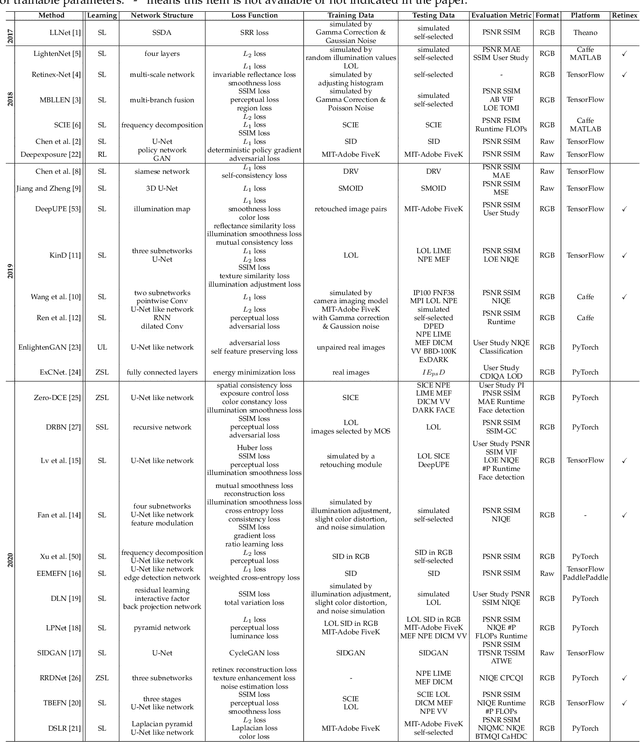

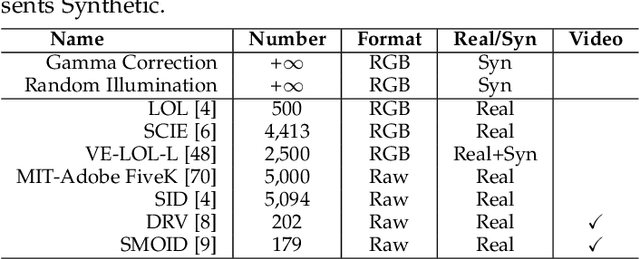
Low-light image enhancement (LLIE) aims at improving the perception or interpretability of an image captured in an environment with poor illumination. Recent advances in this area are dominated by deep learning-based solutions, where many learning strategies, network structures, loss functions, training data, etc. have been employed. In this paper, we provide a comprehensive survey to cover various aspects ranging from algorithm taxonomy to unsolved open issues. To examine the generalization of existing methods, we propose a large-scale low-light image and video dataset, in which the images and videos are taken by different mobile phones' cameras under diverse illumination conditions. Besides, for the first time, we provide a unified online platform that covers many popular LLIE methods, of which the results can be produced through a user-friendly web interface. In addition to qualitative and quantitative evaluation of existing methods on publicly available and our proposed datasets, we also validate their performance in face detection in the dark. This survey together with the proposed dataset and online platform could serve as a reference source for future study and promote the development of this research field. The proposed platform and the collected methods, datasets, and evaluation metrics are publicly available and will be regularly updated at https://github.com/Li-Chongyi/Lighting-the-Darkness-in-the-Deep-Learning-Era-Open. We will release our low-light image and video dataset.
Removing Diffraction Image Artifacts in Under-Display Camera via Dynamic Skip Connection Network
Apr 19, 2021


Recent development of Under-Display Camera (UDC) systems provides a true bezel-less and notch-free viewing experience on smartphones (and TV, laptops, tablets), while allowing images to be captured from the selfie camera embedded underneath. In a typical UDC system, the microstructure of the semi-transparent organic light-emitting diode (OLED) pixel array attenuates and diffracts the incident light on the camera, resulting in significant image quality degradation. Oftentimes, noise, flare, haze, and blur can be observed in UDC images. In this work, we aim to analyze and tackle the aforementioned degradation problems. We define a physics-based image formation model to better understand the degradation. In addition, we utilize one of the world's first commodity UDC smartphone prototypes to measure the real-world Point Spread Function (PSF) of the UDC system, and provide a model-based data synthesis pipeline to generate realistically degraded images. We specially design a new domain knowledge-enabled Dynamic Skip Connection Network (DISCNet) to restore the UDC images. We demonstrate the effectiveness of our method through extensive experiments on both synthetic and real UDC data. Our physics-based image formation model and proposed DISCNet can provide foundations for further exploration in UDC image restoration, and even for general diffraction artifact removal in a broader sense.
HDR Video Reconstruction with Tri-Exposure Quad-Bayer Sensors
Mar 19, 2021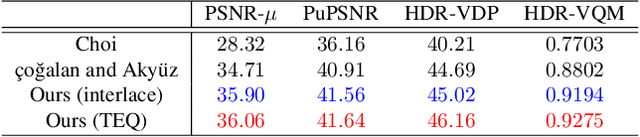
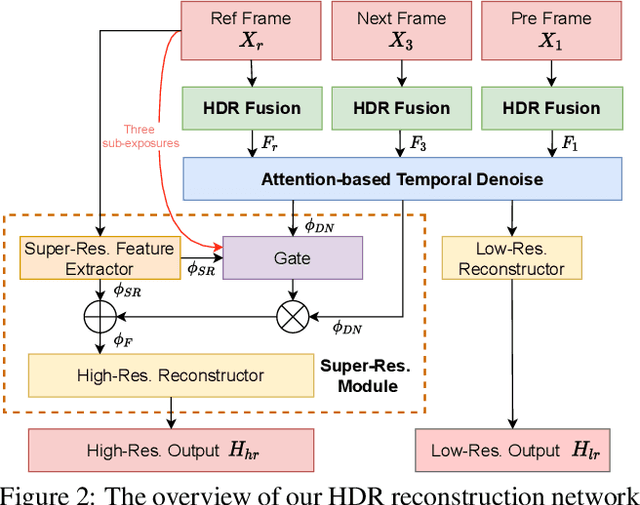
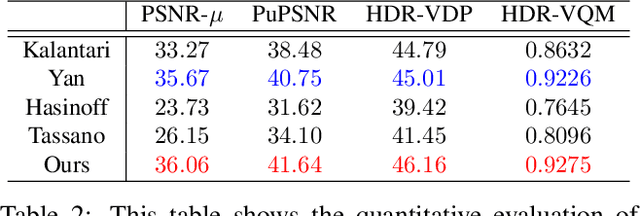
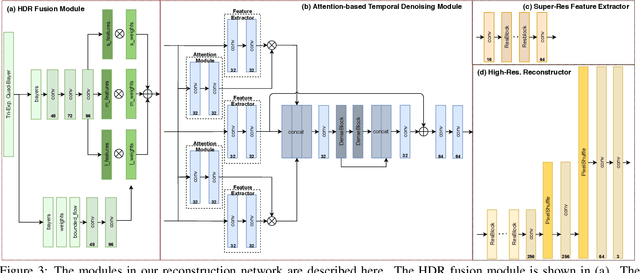
We propose a novel high dynamic range (HDR) video reconstruction method with new tri-exposure quad-bayer sensors. Thanks to the larger number of exposure sets and their spatially uniform deployment over a frame, they are more robust to noise and spatial artifacts than previous spatially varying exposure (SVE) HDR video methods. Nonetheless, the motion blur from longer exposures, the noise from short exposures, and inherent spatial artifacts of the SVE methods remain huge obstacles. Additionally, temporal coherence must be taken into account for the stability of video reconstruction. To tackle these challenges, we introduce a novel network architecture that divides-and-conquers these problems. In order to better adapt the network to the large dynamic range, we also propose LDR-reconstruction loss that takes equal contributions from both the highlighted and the shaded pixels of HDR frames. Through a series of comparisons and ablation studies, we show that the tri-exposure quad-bayer with our solution is more optimal to capture than previous reconstruction methods, particularly for the scenes with larger dynamic range and objects with motion.
iToF2dToF: A Robust and Flexible Representation for Data-Driven Time-of-Flight Imaging
Mar 12, 2021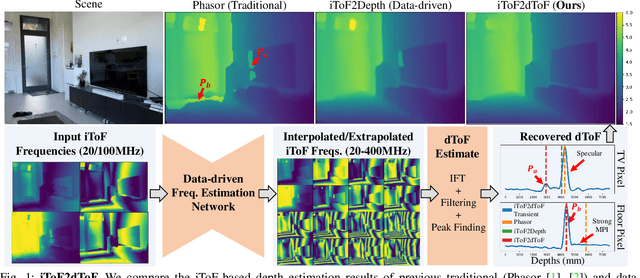
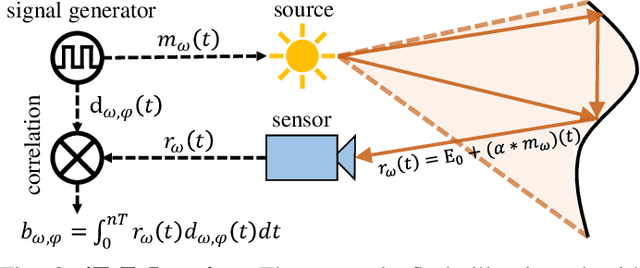
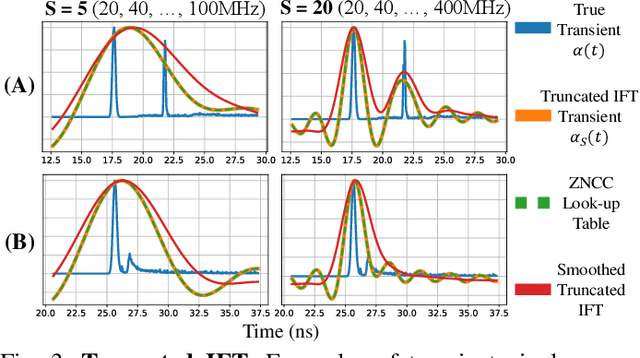
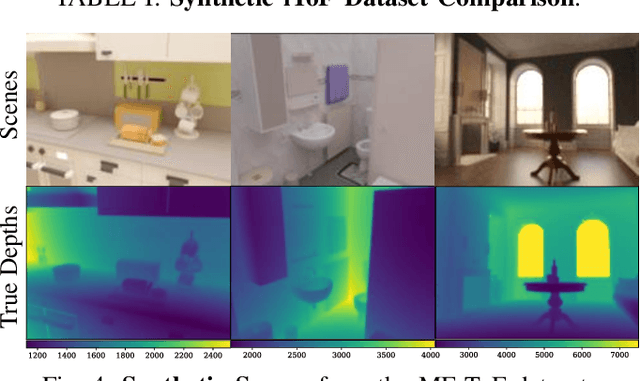
Indirect Time-of-Flight (iToF) cameras are a promising depth sensing technology. However, they are prone to errors caused by multi-path interference (MPI) and low signal-to-noise ratio (SNR). Traditional methods, after denoising, mitigate MPI by estimating a transient image that encodes depths. Recently, data-driven methods that jointly denoise and mitigate MPI have become state-of-the-art without using the intermediate transient representation. In this paper, we propose to revisit the transient representation. Using data-driven priors, we interpolate/extrapolate iToF frequencies and use them to estimate the transient image. Given direct ToF (dToF) sensors capture transient images, we name our method iToF2dToF. The transient representation is flexible. It can be integrated with different rule-based depth sensing algorithms that are robust to low SNR and can deal with ambiguous scenarios that arise in practice (e.g., specular MPI, optical cross-talk). We demonstrate the benefits of iToF2dToF over previous methods in real depth sensing scenarios.
GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution
Dec 01, 2020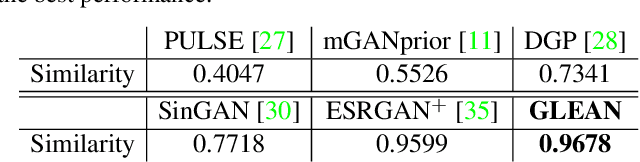
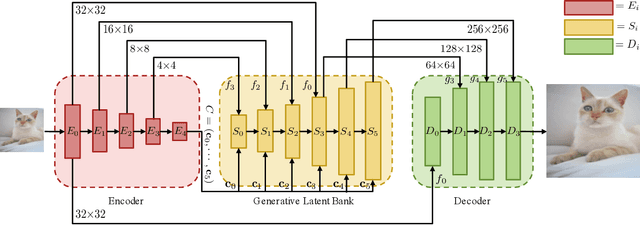


We show that pre-trained Generative Adversarial Networks (GANs), e.g., StyleGAN, can be used as a latent bank to improve the restoration quality of large-factor image super-resolution (SR). While most existing SR approaches attempt to generate realistic textures through learning with adversarial loss, our method, Generative LatEnt bANk (GLEAN), goes beyond existing practices by directly leveraging rich and diverse priors encapsulated in a pre-trained GAN. But unlike prevalent GAN inversion methods that require expensive image-specific optimization at runtime, our approach only needs a single forward pass to generate the upscaled image. GLEAN can be easily incorporated in a simple encoder-bank-decoder architecture with multi-resolution skip connections. Switching the bank allows the method to deal with images from diverse categories, e.g., cat, building, human face, and car. Images upscaled by GLEAN show clear improvements in terms of fidelity and texture faithfulness in comparison to existing methods.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
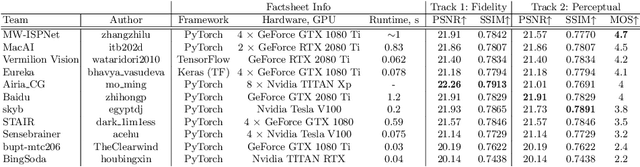
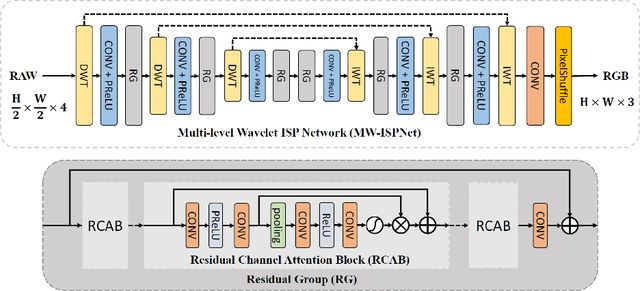
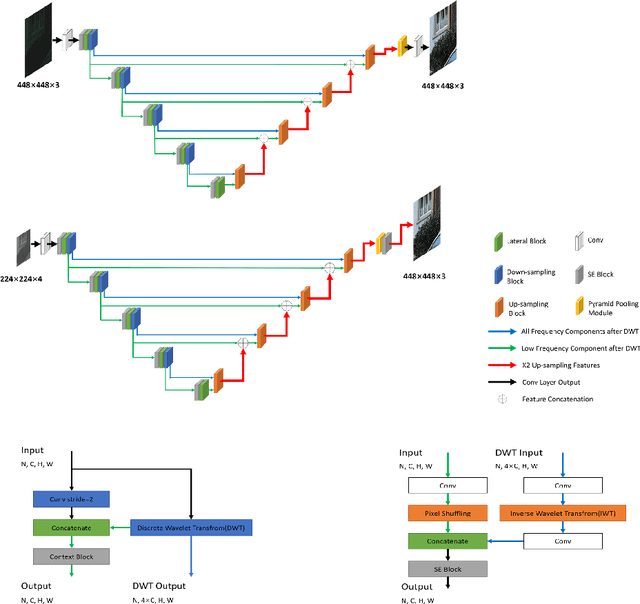
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.
JPAD-SE: High-Level Semantics for Joint Perception-Accuracy-Distortion Enhancement in Image Compression
May 29, 2020
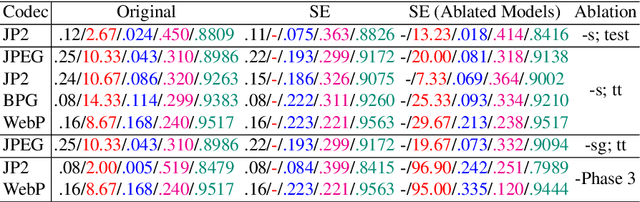

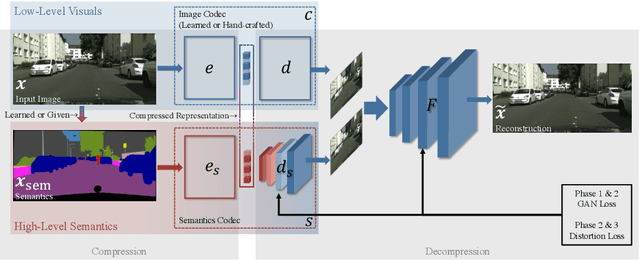
While humans can effortlessly transform complex visual scenes into simple words and the other way around by leveraging their high-level understanding of the content, conventional or the more recent learned image compression codecs do not seem to utilize the semantic meanings of visual content to its full potential. Moreover, they focus mostly on rate-distortion and tend to underperform in perception quality especially in low bitrate regime, and often disregard the performance of downstream computer vision algorithms, which is a fast-growing consumer group of compressed images in addition to human viewers. In this paper, we (1) present a generic framework that can enable any image codec to leverage high-level semantics, and (2) study the joint optimization of perception quality, accuracy of downstream computer vision task, and distortion. Our idea is that given any codec, we utilize high-level semantics to augment the low-level visual features extracted by it and produce essentially a new, semantic-aware codec. And we argue that semantic enhancement implicitly optimizes rate-perception-accuracy-distortion (R-PAD) performance. To validate our claim, we perform extensive empirical evaluations and provide both quantitative and qualitative results.