 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\texttt{NePhi}$: Neural Deformation Fields for Approximately Diffeomorphic Medical Image Registration
Sep 13, 2023



This work proposes $\texttt{NePhi}$, a neural deformation model which results in approximately diffeomorphic transformations. In contrast to the predominant voxel-based approaches, $\texttt{NePhi}$ represents deformations functionally which allows for memory-efficient training and inference. This is of particular importance for large volumetric registrations. Further, while medical image registration approaches representing transformation maps via multi-layer perceptrons have been proposed, $\texttt{NePhi}$ facilitates both pairwise optimization-based registration $\textit{as well as}$ learning-based registration via predicted or optimized global and local latent codes. Lastly, as deformation regularity is a highly desirable property for most medical image registration tasks, $\texttt{NePhi}$ makes use of gradient inverse consistency regularization which empirically results in approximately diffeomorphic transformations. We show the performance of $\texttt{NePhi}$ on two 2D synthetic datasets as well as on real 3D lung registration. Our results show that $\texttt{NePhi}$ can achieve similar accuracies as voxel-based representations in a single-resolution registration setting while using less memory and allowing for faster instance-optimization.
My3DGen: Building Lightweight Personalized 3D Generative Model
Jul 12, 2023



Our paper presents My3DGen, a practical system for creating a personalized and lightweight 3D generative prior using as few as 10 images. My3DGen can reconstruct multi-view consistent images from an input test image, and generate novel appearances by interpolating between any two images of the same individual. While recent studies have demonstrated the effectiveness of personalized generative priors in producing high-quality 2D portrait reconstructions and syntheses, to the best of our knowledge, we are the first to develop a personalized 3D generative prior. Instead of fine-tuning a large pre-trained generative model with millions of parameters to achieve personalization, we propose a parameter-efficient approach. Our method involves utilizing a pre-trained model with fixed weights as a generic prior, while training a separate personalized prior through low-rank decomposition of the weights in each convolution and fully connected layer. However, parameter-efficient few-shot fine-tuning on its own often leads to overfitting. To address this, we introduce a regularization technique based on symmetry of human faces. This regularization enforces that novel view renderings of a training sample, rendered from symmetric poses, exhibit the same identity. By incorporating this symmetry prior, we enhance the quality of reconstruction and synthesis, particularly for non-frontal (profile) faces. Our final system combines low-rank fine-tuning with symmetry regularization and significantly surpasses the performance of pre-trained models, e.g. EG3D. It introduces only approximately 0.6 million additional parameters per identity compared to 31 million for full finetuning of the original model. As a result, our system achieves a 50-fold reduction in model size without sacrificing the quality of the generated 3D faces. Code will be available at our project page: https://luchaoqi.github.io/my3dgen.
Measured Albedo in the Wild: Filling the Gap in Intrinsics Evaluation
Jun 29, 2023



Intrinsic image decomposition and inverse rendering are long-standing problems in computer vision. To evaluate albedo recovery, most algorithms report their quantitative performance with a mean Weighted Human Disagreement Rate (WHDR) metric on the IIW dataset. However, WHDR focuses only on relative albedo values and often fails to capture overall quality of the albedo. In order to comprehensively evaluate albedo, we collect a new dataset, Measured Albedo in the Wild (MAW), and propose three new metrics that complement WHDR: intensity, chromaticity and texture metrics. We show that existing algorithms often improve WHDR metric but perform poorly on other metrics. We then finetune different algorithms on our MAW dataset to significantly improve the quality of the reconstructed albedo both quantitatively and qualitatively. Since the proposed intensity, chromaticity, and texture metrics and the WHDR are all complementary we further introduce a relative performance measure that captures average performance. By analysing existing algorithms we show that there is significant room for improvement. Our dataset and evaluation metrics will enable researchers to develop algorithms that improve albedo reconstruction. Code and Data available at: https://measuredalbedo.github.io/
MVPSNet: Fast Generalizable Multi-view Photometric Stereo
May 18, 2023



We propose a fast and generalizable solution to Multi-view Photometric Stereo (MVPS), called MVPSNet. The key to our approach is a feature extraction network that effectively combines images from the same view captured under multiple lighting conditions to extract geometric features from shading cues for stereo matching. We demonstrate these features, termed `Light Aggregated Feature Maps' (LAFM), are effective for feature matching even in textureless regions, where traditional multi-view stereo methods fail. Our method produces similar reconstruction results to PS-NeRF, a state-of-the-art MVPS method that optimizes a neural network per-scene, while being 411$\times$ faster (105 seconds vs. 12 hours) in inference. Additionally, we introduce a new synthetic dataset for MVPS, sMVPS, which is shown to be effective to train a generalizable MVPS method.
Bringing Telepresence to Every Desk
Apr 03, 2023



In this paper, we work to bring telepresence to every desktop. Unlike commercial systems, personal 3D video conferencing systems must render high-quality videos while remaining financially and computationally viable for the average consumer. To this end, we introduce a capturing and rendering system that only requires 4 consumer-grade RGBD cameras and synthesizes high-quality free-viewpoint videos of users as well as their environments. Experimental results show that our system renders high-quality free-viewpoint videos without using object templates or heavy pre-processing. While not real-time, our system is fast and does not require per-video optimizations. Moreover, our system is robust to complex hand gestures and clothing, and it can generalize to new users. This work provides a strong basis for further optimization, and it will help bring telepresence to every desk in the near future. The code and dataset will be made available on our website https://mcmvmc.github.io/PersonalTelepresence/.
Motion Matters: Neural Motion Transfer for Better Camera Physiological Sensing
Apr 02, 2023



Machine learning models for camera-based physiological measurement can have weak generalization due to a lack of representative training data. Body motion is one of the most significant sources of noise when attempting to recover the subtle cardiac pulse from a video. We explore motion transfer as a form of data augmentation to introduce motion variation while preserving physiological changes. We adapt a neural video synthesis approach to augment videos for the task of remote photoplethysmography (PPG) and study the effects of motion augmentation with respect to 1) the magnitude and 2) the type of motion. After training on motion-augmented versions of publicly available datasets, the presented inter-dataset results on five benchmark datasets show improvements of up to 75% over existing state-of-the-art results. Our findings illustrate the utility of motion transfer as a data augmentation technique for improving the generalization of models for camera-based physiological sensing. We release our code and pre-trained models for using motion transfer as a data augmentation technique on our project page: https://motion-matters.github.io/
A Surface-normal Based Neural Framework for Colonoscopy Reconstruction
Mar 13, 2023



Reconstructing a 3D surface from colonoscopy video is challenging due to illumination and reflectivity variation in the video frame that can cause defective shape predictions. Aiming to overcome this challenge, we utilize the characteristics of surface normal vectors and develop a two-step neural framework that significantly improves the colonoscopy reconstruction quality. The normal-based depth initialization network trained with self-supervised normal consistency loss provides depth map initialization to the normal-depth refinement module, which utilizes the relationship between illumination and surface normals to refine the frame-wise normal and depth predictions recursively. Our framework's depth accuracy performance on phantom colonoscopy data demonstrates the value of exploiting the surface normals in colonoscopy reconstruction, especially on en face views. Due to its low depth error, the prediction result from our framework will require limited post-processing to be clinically applicable for real-time colonoscopy reconstruction.
Universal Guidance for Diffusion Models
Feb 14, 2023



Typical diffusion models are trained to accept a particular form of conditioning, most commonly text, and cannot be conditioned on other modalities without retraining. In this work, we propose a universal guidance algorithm that enables diffusion models to be controlled by arbitrary guidance modalities without the need to retrain any use-specific components. We show that our algorithm successfully generates quality images with guidance functions including segmentation, face recognition, object detection, and classifier signals. Code is available at https://github.com/arpitbansal297/Universal-Guided-Diffusion.
Towards Unified Keyframe Propagation Models
May 19, 2022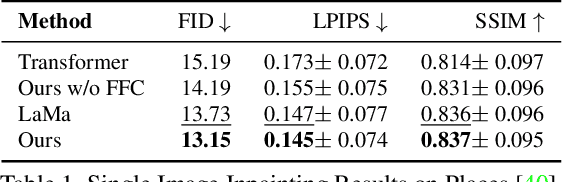
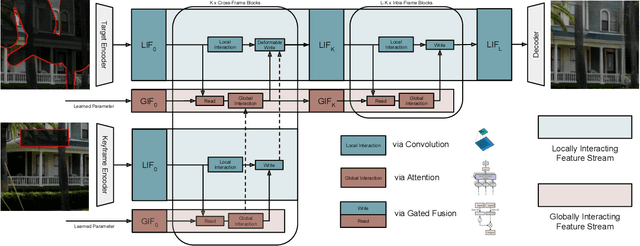
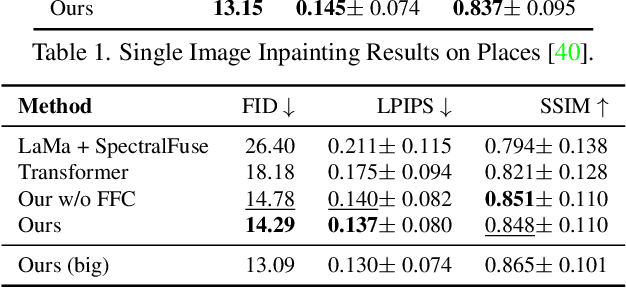

Many video editing tasks such as rotoscoping or object removal require the propagation of context across frames. While transformers and other attention-based approaches that aggregate features globally have demonstrated great success at propagating object masks from keyframes to the whole video, they struggle to propagate high-frequency details such as textures faithfully. We hypothesize that this is due to an inherent bias of global attention towards low-frequency features. To overcome this limitation, we present a two-stream approach, where high-frequency features interact locally and low-frequency features interact globally. The global interaction stream remains robust in difficult situations such as large camera motions, where explicit alignment fails. The local interaction stream propagates high-frequency details through deformable feature aggregation and, informed by the global interaction stream, learns to detect and correct errors of the deformation field. We evaluate our two-stream approach for inpainting tasks, where experiments show that it improves both the propagation of features within a single frame as required for image inpainting, as well as their propagation from keyframes to target frames. Applied to video inpainting, our approach leads to 44% and 26% improvements in FID and LPIPS scores. Code at https://github.com/runwayml/guided-inpainting
Fast Light-Weight Near-Field Photometric Stereo
Mar 30, 2022
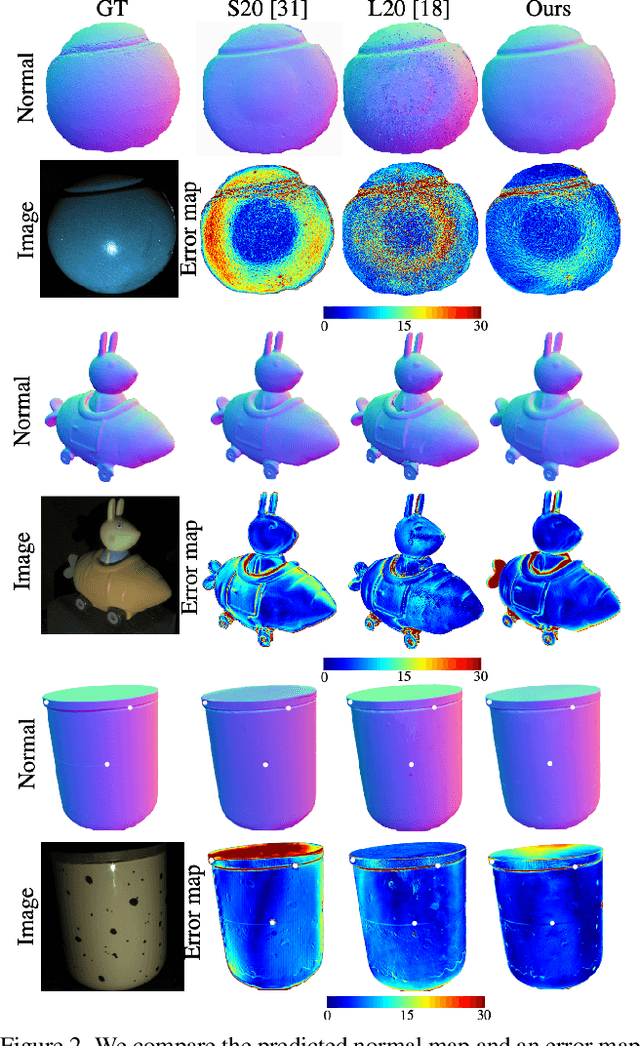
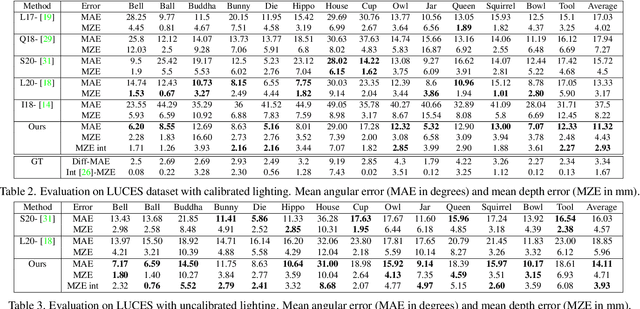
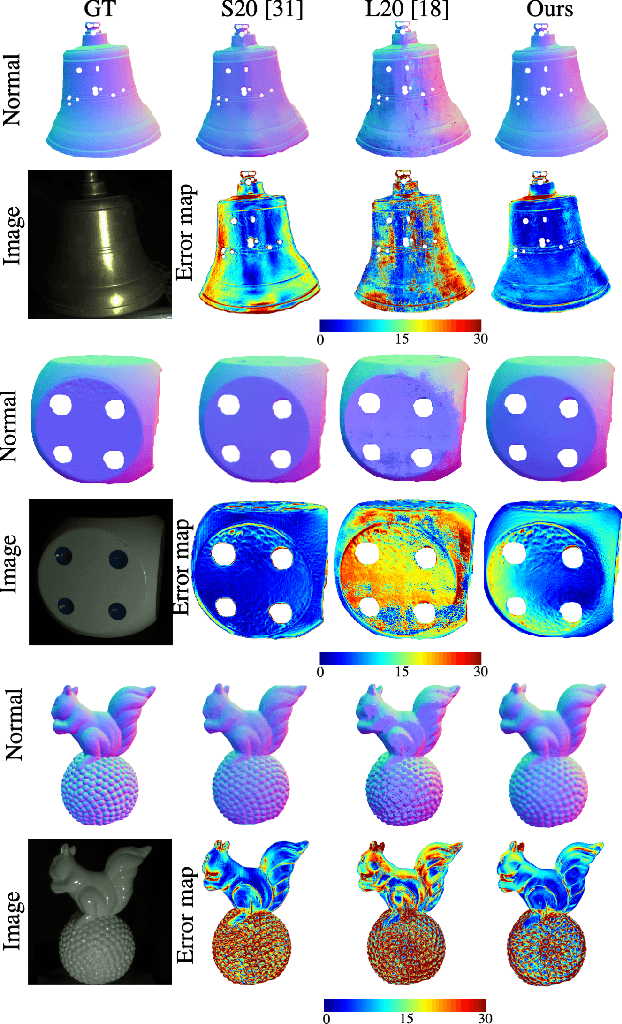
We introduce the first end-to-end learning-based solution to near-field Photometric Stereo (PS), where the light sources are close to the object of interest. This setup is especially useful for reconstructing large immobile objects. Our method is fast, producing a mesh from 52 512$\times$384 resolution images in about 1 second on a commodity GPU, thus potentially unlocking several AR/VR applications. Existing approaches rely on optimization coupled with a far-field PS network operating on pixels or small patches. Using optimization makes these approaches slow and memory intensive (requiring 17GB GPU and 27GB of CPU memory) while using only pixels or patches makes them highly susceptible to noise and calibration errors. To address these issues, we develop a recursive multi-resolution scheme to estimate surface normal and depth maps of the whole image at each step. The predicted depth map at each scale is then used to estimate `per-pixel lighting' for the next scale. This design makes our approach almost 45$\times$ faster and 2$^{\circ}$ more accurate (11.3$^{\circ}$ vs. 13.3$^{\circ}$ Mean Angular Error) than the state-of-the-art near-field PS reconstruction technique, which uses iterative optimization.