 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving 2D Diffusion Models for 3D Medical Imaging with Inter-Slice Consistent Stochasticity
Feb 04, 20263D medical imaging is in high demand and essential for clinical diagnosis and scientific research. Currently, diffusion models (DMs) have become an effective tool for medical imaging reconstruction thanks to their ability to learn rich, high-quality data priors. However, learning the 3D data distribution with DMs in medical imaging is challenging, not only due to the difficulties in data collection but also because of the significant computational burden during model training. A common compromise is to train the DMs on 2D data priors and reconstruct stacked 2D slices to address 3D medical inverse problems. However, the intrinsic randomness of diffusion sampling causes severe inter-slice discontinuities of reconstructed 3D volumes. Existing methods often enforce continuity regularizations along the z-axis, which introduces sensitive hyper-parameters and may lead to over-smoothing results. In this work, we revisit the origin of stochasticity in diffusion sampling and introduce Inter-Slice Consistent Stochasticity (ISCS), a simple yet effective strategy that encourages interslice consistency during diffusion sampling. Our key idea is to control the consistency of stochastic noise components during diffusion sampling, thereby aligning their sampling trajectories without adding any new loss terms or optimization steps. Importantly, the proposed ISCS is plug-and-play and can be dropped into any 2D trained diffusion based 3D reconstruction pipeline without additional computational cost. Experiments on several medical imaging problems show that our method can effectively improve the performance of medical 3D imaging problems based on 2D diffusion models. Our findings suggest that controlling inter-slice stochasticity is a principled and practically attractive route toward high-fidelity 3D medical imaging with 2D diffusion priors. The code is available at: https://github.com/duchenhe/ISCS
InterAgent: Physics-based Multi-agent Command Execution via Diffusion on Interaction Graphs
Dec 12, 2025Humanoid agents are expected to emulate the complex coordination inherent in human social behaviors. However, existing methods are largely confined to single-agent scenarios, overlooking the physically plausible interplay essential for multi-agent interactions. To bridge this gap, we propose InterAgent, the first end-to-end framework for text-driven physics-based multi-agent humanoid control. At its core, we introduce an autoregressive diffusion transformer equipped with multi-stream blocks, which decouples proprioception, exteroception, and action to mitigate cross-modal interference while enabling synergistic coordination. We further propose a novel interaction graph exteroception representation that explicitly captures fine-grained joint-to-joint spatial dependencies to facilitate network learning. Additionally, within it we devise a sparse edge-based attention mechanism that dynamically prunes redundant connections and emphasizes critical inter-agent spatial relations, thereby enhancing the robustness of interaction modeling. Extensive experiments demonstrate that InterAgent consistently outperforms multiple strong baselines, achieving state-of-the-art performance. It enables producing coherent, physically plausible, and semantically faithful multi-agent behaviors from only text prompts. Our code and data will be released to facilitate future research.
XDen-1K: A Density Field Dataset of Real-World Objects
Dec 11, 2025A deep understanding of the physical world is a central goal for embodied AI and realistic simulation. While current models excel at capturing an object's surface geometry and appearance, they largely neglect its internal physical properties. This omission is critical, as properties like volumetric density are fundamental for predicting an object's center of mass, stability, and interaction dynamics in applications ranging from robotic manipulation to physical simulation. The primary bottleneck has been the absence of large-scale, real-world data. To bridge this gap, we introduce XDen-1K, the first large-scale, multi-modal dataset designed for real-world physical property estimation, with a particular focus on volumetric density. The core of this dataset consists of 1,000 real-world objects across 148 categories, for which we provide comprehensive multi-modal data, including a high-resolution 3D geometric model with part-level annotations and a corresponding set of real-world biplanar X-ray scans. Building upon this data, we introduce a novel optimization framework that recovers a high-fidelity volumetric density field of each object from its sparse X-ray views. To demonstrate its practical value, we add X-ray images as a conditioning signal to an existing segmentation network and perform volumetric segmentation. Furthermore, we conduct experiments on downstream robotics tasks. The results show that leveraging the dataset can effectively improve the accuracy of center-of-mass estimation and the success rate of robotic manipulation. We believe XDen-1K will serve as a foundational resource and a challenging new benchmark, catalyzing future research in physically grounded visual inference and embodied AI.
An Energy-Efficient Edge Coprocessor for Neural Rendering with Explicit Data Reuse Strategies
Oct 09, 2025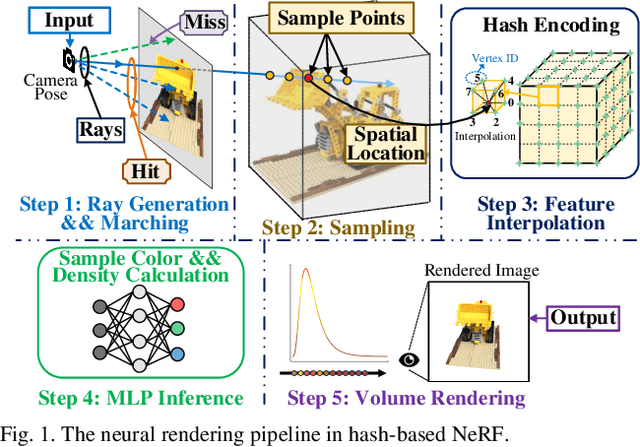
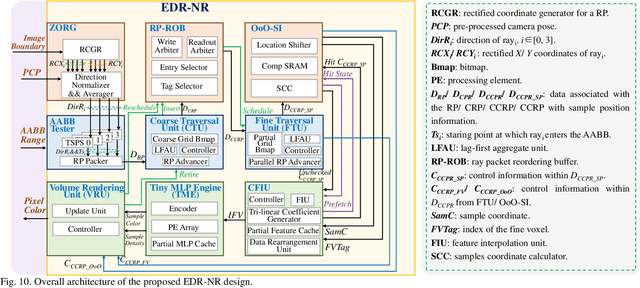
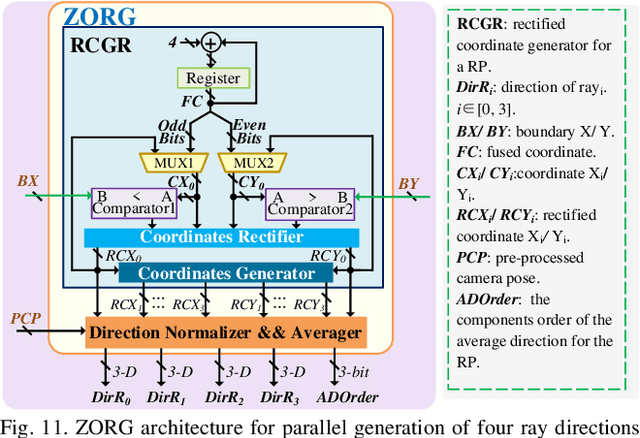
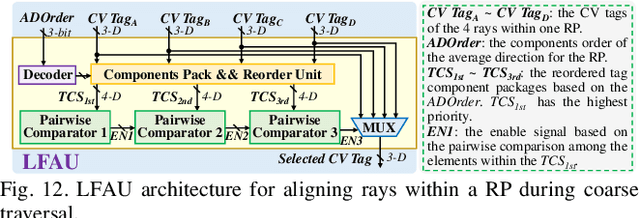
Neural radiance fields (NeRF) have transformed 3D reconstruction and rendering, facilitating photorealistic image synthesis from sparse viewpoints. This work introduces an explicit data reuse neural rendering (EDR-NR) architecture, which reduces frequent external memory accesses (EMAs) and cache misses by exploiting the spatial locality from three phases, including rays, ray packets (RPs), and samples. The EDR-NR architecture features a four-stage scheduler that clusters rays on the basis of Z-order, prioritize lagging rays when ray divergence happens, reorders RPs based on spatial proximity, and issues samples out-of-orderly (OoO) according to the availability of on-chip feature data. In addition, a four-tier hierarchical RP marching (HRM) technique is integrated with an axis-aligned bounding box (AABB) to facilitate spatial skipping (SS), reducing redundant computations and improving throughput. Moreover, a balanced allocation strategy for feature storage is proposed to mitigate SRAM bank conflicts. Fabricated using a 40 nm process with a die area of 10.5 mmX, the EDR-NR chip demonstrates a 2.41X enhancement in normalized energy efficiency, a 1.21X improvement in normalized area efficiency, a 1.20X increase in normalized throughput, and a 53.42% reduction in on-chip SRAM consumption compared to state-of-the-art accelerators.
Causal Mechanism Estimation in Multi-Sensor Systems Across Multiple Domains
Jul 23, 2025



To gain deeper insights into a complex sensor system through the lens of causality, we present common and individual causal mechanism estimation (CICME), a novel three-step approach to inferring causal mechanisms from heterogeneous data collected across multiple domains. By leveraging the principle of Causal Transfer Learning (CTL), CICME is able to reliably detect domain-invariant causal mechanisms when provided with sufficient samples. The identified common causal mechanisms are further used to guide the estimation of the remaining causal mechanisms in each domain individually. The performance of CICME is evaluated on linear Gaussian models under scenarios inspired from a manufacturing process. Building upon existing continuous optimization-based causal discovery methods, we show that CICME leverages the benefits of applying causal discovery on the pooled data and repeatedly on data from individual domains, and it even outperforms both baseline methods under certain scenarios.
MARMOT: Masked Autoencoder for Modeling Transient Imaging
Jun 10, 2025
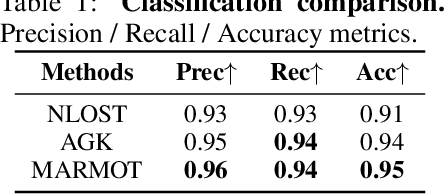


Pretrained models have demonstrated impressive success in many modalities such as language and vision. Recent works facilitate the pretraining paradigm in imaging research. Transients are a novel modality, which are captured for an object as photon counts versus arrival times using a precisely time-resolved sensor. In particular for non-line-of-sight (NLOS) scenarios, transients of hidden objects are measured beyond the sensor's direct line of sight. Using NLOS transients, the majority of previous works optimize volume density or surfaces to reconstruct the hidden objects and do not transfer priors learned from datasets. In this work, we present a masked autoencoder for modeling transient imaging, or MARMOT, to facilitate NLOS applications. Our MARMOT is a self-supervised model pretrianed on massive and diverse NLOS transient datasets. Using a Transformer-based encoder-decoder, MARMOT learns features from partially masked transients via a scanning pattern mask (SPM), where the unmasked subset is functionally equivalent to arbitrary sampling, and predicts full measurements. Pretrained on TransVerse-a synthesized transient dataset of 500K 3D models-MARMOT adapts to downstream imaging tasks using direct feature transfer or decoder finetuning. Comprehensive experiments are carried out in comparisons with state-of-the-art methods. Quantitative and qualitative results demonstrate the efficiency of our MARMOT.
CryoFastAR: Fast Cryo-EM Ab Initio Reconstruction Made Easy
Jun 06, 2025Pose estimation from unordered images is fundamental for 3D reconstruction, robotics, and scientific imaging. Recent geometric foundation models, such as DUSt3R, enable end-to-end dense 3D reconstruction but remain underexplored in scientific imaging fields like cryo-electron microscopy (cryo-EM) for near-atomic protein reconstruction. In cryo-EM, pose estimation and 3D reconstruction from unordered particle images still depend on time-consuming iterative optimization, primarily due to challenges such as low signal-to-noise ratios (SNR) and distortions from the contrast transfer function (CTF). We introduce CryoFastAR, the first geometric foundation model that can directly predict poses from Cryo-EM noisy images for Fast ab initio Reconstruction. By integrating multi-view features and training on large-scale simulated cryo-EM data with realistic noise and CTF modulations, CryoFastAR enhances pose estimation accuracy and generalization. To enhance training stability, we propose a progressive training strategy that first allows the model to extract essential features under simpler conditions before gradually increasing difficulty to improve robustness. Experiments show that CryoFastAR achieves comparable quality while significantly accelerating inference over traditional iterative approaches on both synthetic and real datasets.
CityGo: Lightweight Urban Modeling and Rendering with Proxy Buildings and Residual Gaussians
May 28, 2025



Accurate and efficient modeling of large-scale urban scenes is critical for applications such as AR navigation, UAV based inspection, and smart city digital twins. While aerial imagery offers broad coverage and complements limitations of ground-based data, reconstructing city-scale environments from such views remains challenging due to occlusions, incomplete geometry, and high memory demands. Recent advances like 3D Gaussian Splatting (3DGS) improve scalability and visual quality but remain limited by dense primitive usage, long training times, and poor suit ability for edge devices. We propose CityGo, a hybrid framework that combines textured proxy geometry with residual and surrounding 3D Gaussians for lightweight, photorealistic rendering of urban scenes from aerial perspectives. Our approach first extracts compact building proxy meshes from MVS point clouds, then uses zero order SH Gaussians to generate occlusion-free textures via image-based rendering and back-projection. To capture high-frequency details, we introduce residual Gaussians placed based on proxy-photo discrepancies and guided by depth priors. Broader urban context is represented by surrounding Gaussians, with importance-aware downsampling applied to non-critical regions to reduce redundancy. A tailored optimization strategy jointly refines proxy textures and Gaussian parameters, enabling real-time rendering of complex urban scenes on mobile GPUs with significantly reduced training and memory requirements. Extensive experiments on real-world aerial datasets demonstrate that our hybrid representation significantly reduces training time, achieving on average 1.4x speedup, while delivering comparable visual fidelity to pure 3D Gaussian Splatting approaches. Furthermore, CityGo enables real-time rendering of large-scale urban scenes on mobile consumer GPUs, with substantially reduced memory usage and energy consumption.
One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid Locomotion
May 24, 2025



Humanoid locomotion faces a critical scalability challenge: traditional reinforcement learning (RL) methods require task-specific rewards and struggle to leverage growing datasets, even as more training terrains are introduced. We propose DreamPolicy, a unified framework that enables a single policy to master diverse terrains and generalize zero-shot to unseen scenarios by systematically integrating offline data and diffusion-driven motion synthesis. At its core, DreamPolicy introduces Humanoid Motion Imagery (HMI) - future state predictions synthesized through an autoregressive terrain-aware diffusion planner curated by aggregating rollouts from specialized policies across various distinct terrains. Unlike human motion datasets requiring laborious retargeting, our data directly captures humanoid kinematics, enabling the diffusion planner to synthesize "dreamed" trajectories that encode terrain-specific physical constraints. These trajectories act as dynamic objectives for our HMI-conditioned policy, bypassing manual reward engineering and enabling cross-terrain generalization. DreamPolicy addresses the scalability limitations of prior methods: while traditional RL fails to exploit growing datasets, our framework scales seamlessly with more offline data. As the dataset expands, the diffusion prior learns richer locomotion skills, which the policy leverages to master new terrains without retraining. Experiments demonstrate that DreamPolicy achieves average 90% success rates in training environments and an average of 20% higher success on unseen terrains than the prevalent method. It also generalizes to perturbed and composite scenarios where prior approaches collapse. By unifying offline data, diffusion-based trajectory synthesis, and policy optimization, DreamPolicy overcomes the "one task, one policy" bottleneck, establishing a paradigm for scalable, data-driven humanoid control.
JSover: Joint Spectrum Estimation and Multi-Material Decomposition from Single-Energy CT Projections
May 12, 2025Multi-material decomposition (MMD) enables quantitative reconstruction of tissue compositions in the human body, supporting a wide range of clinical applications. However, traditional MMD typically requires spectral CT scanners and pre-measured X-ray energy spectra, significantly limiting clinical applicability. To this end, various methods have been developed to perform MMD using conventional (i.e., single-energy, SE) CT systems, commonly referred to as SEMMD. Despite promising progress, most SEMMD methods follow a two-step image decomposition pipeline, which first reconstructs monochromatic CT images using algorithms such as FBP, and then performs decomposition on these images. The initial reconstruction step, however, neglects the energy-dependent attenuation of human tissues, introducing severe nonlinear beam hardening artifacts and noise into the subsequent decomposition. This paper proposes JSover, a fundamentally reformulated one-step SEMMD framework that jointly reconstructs multi-material compositions and estimates the energy spectrum directly from SECT projections. By explicitly incorporating physics-informed spectral priors into the SEMMD process, JSover accurately simulates a virtual spectral CT system from SE acquisitions, thereby improving the reliability and accuracy of decomposition. Furthermore, we introduce implicit neural representation (INR) as an unsupervised deep learning solver for representing the underlying material maps. The inductive bias of INR toward continuous image patterns constrains the solution space and further enhances estimation quality. Extensive experiments on both simulated and real CT datasets show that JSover outperforms state-of-the-art SEMMD methods in accuracy and computational efficiency.