 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCityGo: Lightweight Urban Modeling and Rendering with Proxy Buildings and Residual Gaussians
May 28, 2025



Accurate and efficient modeling of large-scale urban scenes is critical for applications such as AR navigation, UAV based inspection, and smart city digital twins. While aerial imagery offers broad coverage and complements limitations of ground-based data, reconstructing city-scale environments from such views remains challenging due to occlusions, incomplete geometry, and high memory demands. Recent advances like 3D Gaussian Splatting (3DGS) improve scalability and visual quality but remain limited by dense primitive usage, long training times, and poor suit ability for edge devices. We propose CityGo, a hybrid framework that combines textured proxy geometry with residual and surrounding 3D Gaussians for lightweight, photorealistic rendering of urban scenes from aerial perspectives. Our approach first extracts compact building proxy meshes from MVS point clouds, then uses zero order SH Gaussians to generate occlusion-free textures via image-based rendering and back-projection. To capture high-frequency details, we introduce residual Gaussians placed based on proxy-photo discrepancies and guided by depth priors. Broader urban context is represented by surrounding Gaussians, with importance-aware downsampling applied to non-critical regions to reduce redundancy. A tailored optimization strategy jointly refines proxy textures and Gaussian parameters, enabling real-time rendering of complex urban scenes on mobile GPUs with significantly reduced training and memory requirements. Extensive experiments on real-world aerial datasets demonstrate that our hybrid representation significantly reduces training time, achieving on average 1.4x speedup, while delivering comparable visual fidelity to pure 3D Gaussian Splatting approaches. Furthermore, CityGo enables real-time rendering of large-scale urban scenes on mobile consumer GPUs, with substantially reduced memory usage and energy consumption.
LetsGo: Large-Scale Garage Modeling and Rendering via LiDAR-Assisted Gaussian Primitives
Apr 15, 2024



Large garages are ubiquitous yet intricate scenes in our daily lives, posing challenges characterized by monotonous colors, repetitive patterns, reflective surfaces, and transparent vehicle glass. Conventional Structure from Motion (SfM) methods for camera pose estimation and 3D reconstruction fail in these environments due to poor correspondence construction. To address these challenges, this paper introduces LetsGo, a LiDAR-assisted Gaussian splatting approach for large-scale garage modeling and rendering. We develop a handheld scanner, Polar, equipped with IMU, LiDAR, and a fisheye camera, to facilitate accurate LiDAR and image data scanning. With this Polar device, we present a GarageWorld dataset consisting of five expansive garage scenes with diverse geometric structures and will release the dataset to the community for further research. We demonstrate that the collected LiDAR point cloud by the Polar device enhances a suite of 3D Gaussian splatting algorithms for garage scene modeling and rendering. We also propose a novel depth regularizer for 3D Gaussian splatting algorithm training, effectively eliminating floating artifacts in rendered images, and a lightweight Level of Detail (LOD) Gaussian renderer for real-time viewing on web-based devices. Additionally, we explore a hybrid representation that combines the advantages of traditional mesh in depicting simple geometry and colors (e.g., walls and the ground) with modern 3D Gaussian representations capturing complex details and high-frequency textures. This strategy achieves an optimal balance between memory performance and rendering quality. Experimental results on our dataset, along with ScanNet++ and KITTI-360, demonstrate the superiority of our method in rendering quality and resource efficiency.
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

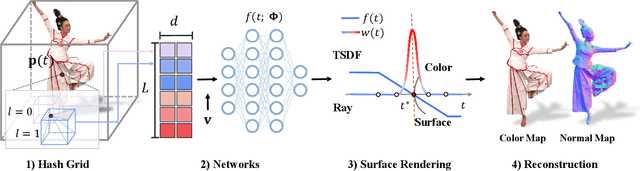
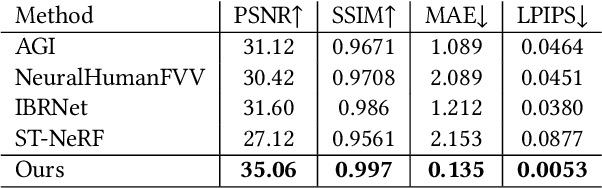
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.