 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForeSplat: Optimization-Aware Foresight for Feed-Forward 3D Gaussian Splatting
May 21, 2026Feed-forward 3D Gaussian Splatting (3DGS) models offer fast single-pass reconstruction,but scaling them to match per-scene optimization quality is fundamentally hindered by the scarcity of large-scale 3D annotations.A practical compromise is predict-then-refine,where post-prediction optimization compensates for the limited capacity of the feed-forward network.However,standard feed-forward 3DGS is trained solely for zero-step rendering error,ignoring whether its output constitutes a good initialization for the downstream optimizer.We present ForeSplat,an optimization-aware training framework that equips feed-forward 3DGS models to produce initializations explicitly designed for rapid,effective refinement.By offloading part of the scene-modeling burden to the optimizer,ForeSplat substantially reduces the capacity pressure on the feed-forward model,making high-quality reconstruction feasible even with compact networks.At its core is MetaGrad,a lightweight multi-anchor meta-gradient training rule that bypasses costly higher-order differentiation through the 3DGS optimizer.MetaGrad unrolls a short inner-loop refinement trajectory,samples anchor states,and back-propagates aggregated first-order gradients to the prediction head as a surrogate optimization-aware signal.This fine-tuning adds no inference cost and enables high-quality reconstruction within seconds after a few refinement steps.We instantiate ForeSplat on diverse backbones,including AnySplat,Pi3X,and a distilled variant tailored for edge deployment.Across all tested architectures,a ForeSplat-trained initialization converges in fewer refinement steps and reaches a higher peak reconstruction quality than its vanilla counterpart,even fully converged.The framework consistently bridges the gap between amortized prediction and per-scene optimization,establishing a practical path toward lightweight,high-fidelity 3D reconstruction.
An Agentic AI Framework with Large Language Models and Chain-of-Thought for UAV-Assisted Logistics Scheduling with Mobile Edge Computing
May 13, 2026In cloud manufacturing, unmanned aerial vehicles (UAVs) can support both product collection and mobile edge computing (MEC). This joint operation forms a hybrid scheduling problem, where physical logistics decisions are coupled with computational task scheduling. In this paper, UAVs collect finished products from manufacturing stations and transport them back to a central depot. Meanwhile, computational tasks generated by industrial sensor devices at these stations are processed locally, at UAVs, or offloaded via UAVs to the cloud. This coupling makes the problem challenging. A UAV can provide MEC services only during its service window at a station, so routing decisions directly determine when UAV-assisted offloading is available. Routing decisions also affect the UAV energy budget and the availability of onboard computing and communication resources for computational task execution under task deadline constraints. To address this, we propose an agentic-AI-assisted optimization framework with two components. First, we develop an agentic AI that combines large language models, retrieval-augmented generation, and chain-of-thought reasoning to translate user input into an interpretable mathematical formulation for the hybrid scheduling problem. Second, we design a hierarchical deep reinforcement learning approach based on proximal policy optimization (PPO), where the upper layer learns UAV routing and the lower layer optimizes per-slot task execution and resource allocation. Simulation results show that the proposed framework yields more consistent formulations, while the hierarchical PPO achieves full product collection in 99.6% of the last 500 episodes and maintains a 100% deadline satisfaction rate, with more stable performance than the advantage actor-critic approach.
TsallisPGD: Adaptive Gradient Weighting for Adversarial Attacks on Semantic Segmentation
May 05, 2026Attacking semantic segmentation models is significantly harder than image classification models because an attacker must flip thousands of pixel predictions simultaneously. Standard pixel-wise cross-entropy (CE) is ill-suited to this setting: it tends to overemphasize already-misclassified pixels, which slows optimization and overstates model robustness. To address these issues, we introduce TsallisPGD, an adversarial attack built on the Tsallis cross-entropy, a generalization of CE parameterized by $q$, which adaptively reshapes the gradient landscape by controlling gradient concentration across pixels. By varying $q$, we steer the attack toward pixels at different confidence levels. We first show that no single fixed-$q$ is universally optimal, as its effectiveness depends on the dataset, model architecture, and perturbation budget. Motivated by this, we propose a dynamic $q$-schedule that sweeps $q$ during optimization. Extensive experiments on Cityscapes, Pascal VOC, and ADE20K show that TsallisPGD, using a single validation-selected schedule, achieves the best average attack rank across all evaluated settings and improves over CEPGD, SegPGD, CosPGD, JSPGD, and MaskedPGD in reducing accuracy and mIoU on both standard and robust models.
ICA: Information-Aware Credit Assignment for Visually Grounded Long-Horizon Information-Seeking Agents
Feb 11, 2026Despite the strong performance achieved by reinforcement learning-trained information-seeking agents, learning in open-ended web environments remains severely constrained by low signal-to-noise feedback. Text-based parsers often discard layout semantics and introduce unstructured noise, while long-horizon training typically relies on sparse outcome rewards that obscure which retrieval actions actually matter. We propose a visual-native search framework that represents webpages as visual snapshots, allowing agents to leverage layout cues to quickly localize salient evidence and suppress distractors. To learn effectively from these high-dimensional observations, we introduce Information-Aware Credit Assignment (ICA), a post-hoc method that estimates each retrieved snapshot's contribution to the final outcome via posterior analysis and propagates dense learning signals back to key search turns. Integrated with a GRPO-based training pipeline, our approach consistently outperforms text-based baselines on diverse information-seeking benchmarks, providing evidence that visual snapshot grounding with information-level credit assignment alleviates the credit-assignment bottleneck in open-ended web environments. The code and datasets will be released in https://github.com/pc-inno/ICA_MM_deepsearch.git.
Pace: Physics-Aware Attentive Temporal Convolutional Network for Battery Health Estimation
Dec 16, 2025Batteries are critical components in modern energy systems such as electric vehicles and power grid energy storage. Effective battery health management is essential for battery system safety, cost-efficiency, and sustainability. In this paper, we propose Pace, a physics-aware attentive temporal convolutional network for battery health estimation. Pace integrates raw sensor measurements with battery physics features derived from the equivalent circuit model. We develop three battery-specific modules, including dilated temporal blocks for efficient temporal encoding, chunked attention blocks for context modeling, and a dual-head output block for fusing short- and long-term battery degradation patterns. Together, the modules enable Pace to predict battery health accurately and efficiently in various battery usage conditions. In a large public dataset, Pace performs much better than existing models, achieving an average performance improvement of 6.5 and 2.0x compared to two best-performing baseline models. We further demonstrate its practical viability with a real-time edge deployment on a Raspberry Pi. These results establish Pace as a practical and high-performance solution for battery health analytics.
Towards Fine-Grained Recognition with Large Visual Language Models: Benchmark and Optimization Strategies
Dec 11, 2025



Large Vision Language Models (LVLMs) have made remarkable progress, enabling sophisticated vision-language interaction and dialogue applications. However, existing benchmarks primarily focus on reasoning tasks, often neglecting fine-grained recognition, which is crucial for practical application scenarios. To address this gap, we introduce the Fine-grained Recognition Open World (FROW) benchmark, designed for detailed evaluation of LVLMs with GPT-4o. On the basis of that, we propose a novel optimization strategy from two perspectives: \textit{data construction} and \textit{training process}, to improve the performance of LVLMs. Our dataset includes mosaic data, which combines multiple short-answer responses, and open-world data, generated from real-world questions and answers using GPT-4o, creating a comprehensive framework for evaluating fine-grained recognition in LVLMs. Experiments show that mosaic data improves category recognition accuracy by 1\% and open-world data boosts FROW benchmark accuracy by 10\%-20\% and content accuracy by 6\%-12\%. Meanwhile, incorporating fine-grained data into the pre-training phase can improve the model's category recognition accuracy by up to 10\%. The benchmark will be available at https://github.com/pc-inno/FROW.
An Energy-Efficient Edge Coprocessor for Neural Rendering with Explicit Data Reuse Strategies
Oct 09, 2025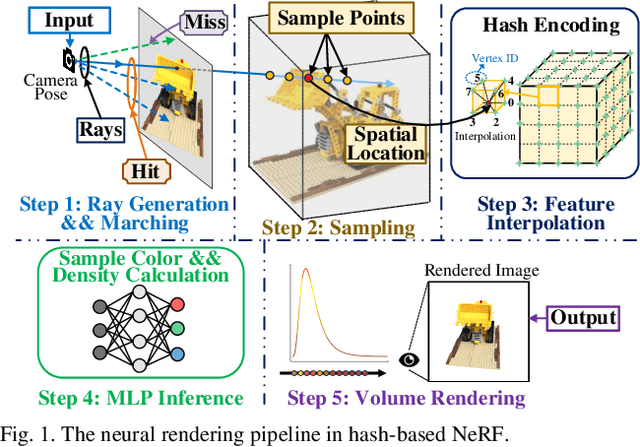
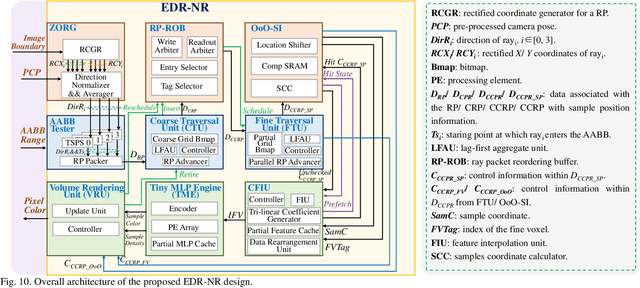
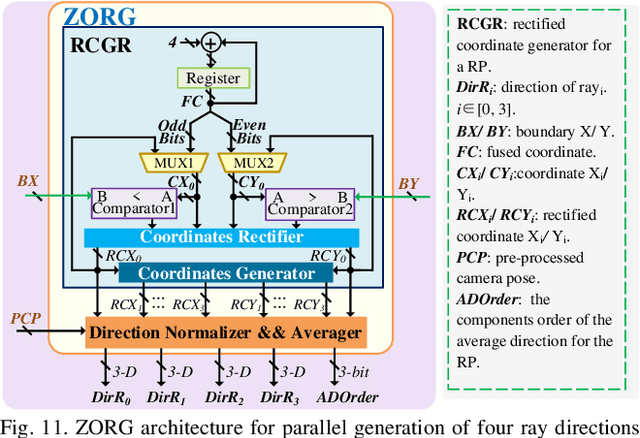
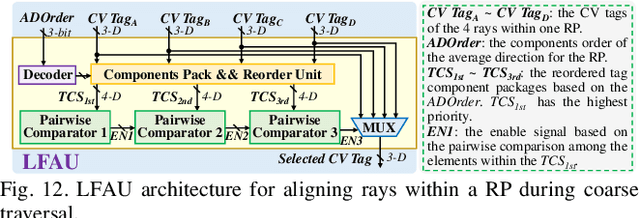
Neural radiance fields (NeRF) have transformed 3D reconstruction and rendering, facilitating photorealistic image synthesis from sparse viewpoints. This work introduces an explicit data reuse neural rendering (EDR-NR) architecture, which reduces frequent external memory accesses (EMAs) and cache misses by exploiting the spatial locality from three phases, including rays, ray packets (RPs), and samples. The EDR-NR architecture features a four-stage scheduler that clusters rays on the basis of Z-order, prioritize lagging rays when ray divergence happens, reorders RPs based on spatial proximity, and issues samples out-of-orderly (OoO) according to the availability of on-chip feature data. In addition, a four-tier hierarchical RP marching (HRM) technique is integrated with an axis-aligned bounding box (AABB) to facilitate spatial skipping (SS), reducing redundant computations and improving throughput. Moreover, a balanced allocation strategy for feature storage is proposed to mitigate SRAM bank conflicts. Fabricated using a 40 nm process with a die area of 10.5 mmX, the EDR-NR chip demonstrates a 2.41X enhancement in normalized energy efficiency, a 1.21X improvement in normalized area efficiency, a 1.20X increase in normalized throughput, and a 53.42% reduction in on-chip SRAM consumption compared to state-of-the-art accelerators.
CityGo: Lightweight Urban Modeling and Rendering with Proxy Buildings and Residual Gaussians
May 28, 2025



Accurate and efficient modeling of large-scale urban scenes is critical for applications such as AR navigation, UAV based inspection, and smart city digital twins. While aerial imagery offers broad coverage and complements limitations of ground-based data, reconstructing city-scale environments from such views remains challenging due to occlusions, incomplete geometry, and high memory demands. Recent advances like 3D Gaussian Splatting (3DGS) improve scalability and visual quality but remain limited by dense primitive usage, long training times, and poor suit ability for edge devices. We propose CityGo, a hybrid framework that combines textured proxy geometry with residual and surrounding 3D Gaussians for lightweight, photorealistic rendering of urban scenes from aerial perspectives. Our approach first extracts compact building proxy meshes from MVS point clouds, then uses zero order SH Gaussians to generate occlusion-free textures via image-based rendering and back-projection. To capture high-frequency details, we introduce residual Gaussians placed based on proxy-photo discrepancies and guided by depth priors. Broader urban context is represented by surrounding Gaussians, with importance-aware downsampling applied to non-critical regions to reduce redundancy. A tailored optimization strategy jointly refines proxy textures and Gaussian parameters, enabling real-time rendering of complex urban scenes on mobile GPUs with significantly reduced training and memory requirements. Extensive experiments on real-world aerial datasets demonstrate that our hybrid representation significantly reduces training time, achieving on average 1.4x speedup, while delivering comparable visual fidelity to pure 3D Gaussian Splatting approaches. Furthermore, CityGo enables real-time rendering of large-scale urban scenes on mobile consumer GPUs, with substantially reduced memory usage and energy consumption.
GiNet: Integrating Sequential and Context-Aware Learning for Battery Capacity Prediction
Jan 09, 2025



The surging demand for batteries requires advanced battery management systems, where battery capacity modelling is a key functionality. In this paper, we aim to achieve accurate battery capacity prediction by learning from historical measurements of battery dynamics. We propose GiNet, a gated recurrent units enhanced Informer network, for predicting battery's capacity. The novelty and competitiveness of GiNet lies in its capability of capturing sequential and contextual information from raw battery data and reflecting the battery's complex behaviors with both temporal dynamics and long-term dependencies. We conducted an experimental study based on a publicly available dataset to showcase GiNet's strength of gaining a holistic understanding of battery behavior and predicting battery capacity accurately. GiNet achieves 0.11 mean absolute error for predicting the battery capacity in a sequence of future time slots without knowing the historical battery capacity. It also outperforms the latest algorithms significantly with 27% error reduction on average compared to Informer. The promising results highlight the importance of customized and optimized integration of algorithm and battery knowledge and shed light on other industry applications as well.
Content-Aware Radiance Fields: Aligning Model Complexity with Scene Intricacy Through Learned Bitwidth Quantization
Oct 25, 2024The recent popular radiance field models, exemplified by Neural Radiance Fields (NeRF), Instant-NGP and 3D Gaussian Splat?ting, are designed to represent 3D content by that training models for each individual scene. This unique characteristic of scene representation and per-scene training distinguishes radiance field models from other neural models, because complex scenes necessitate models with higher representational capacity and vice versa. In this paper, we propose content?aware radiance fields, aligning the model complexity with the scene intricacies through Adversarial Content-Aware Quantization (A-CAQ). Specifically, we make the bitwidth of parameters differentiable and train?able, tailored to the unique characteristics of specific scenes and requirements. The proposed framework has been assessed on Instant-NGP, a well-known NeRF variant and evaluated using various datasets. Experimental results demonstrate a notable reduction in computational complexity, while preserving the requisite reconstruction and rendering quality, making it beneficial for practical deployment of radiance fields models. Codes are available at https://github.com/WeihangLiu2024/Content_Aware_NeRF.