 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Retrieval: A Systematic Review of Methods and Future Directions
Aug 28, 2023



With the exponential surge in diverse multi-modal data, traditional uni-modal retrieval methods struggle to meet the needs of users demanding access to data from various modalities. To address this, cross-modal retrieval has emerged, enabling interaction across modalities, facilitating semantic matching, and leveraging complementarity and consistency between different modal data. Although prior literature undertook a review of the cross-modal retrieval field, it exhibits numerous deficiencies pertaining to timeliness, taxonomy, and comprehensiveness. This paper conducts a comprehensive review of cross-modal retrieval's evolution, spanning from shallow statistical analysis techniques to vision-language pre-training models. Commencing with a comprehensive taxonomy grounded in machine learning paradigms, mechanisms, and models, the paper then delves deeply into the principles and architectures underpinning existing cross-modal retrieval methods. Furthermore, it offers an overview of widely used benchmarks, metrics, and performances. Lastly, the paper probes the prospects and challenges that confront contemporary cross-modal retrieval, while engaging in a discourse on potential directions for further progress in the field. To facilitate the research on cross-modal retrieval, we develop an open-source code repository at https://github.com/BMC-SDNU/Cross-Modal-Retrieval.
Beyond Sharing: Conflict-Aware Multivariate Time Series Anomaly Detection
Aug 25, 2023



Massive key performance indicators (KPIs) are monitored as multivariate time series data (MTS) to ensure the reliability of the software applications and service system. Accurately detecting the abnormality of MTS is very critical for subsequent fault elimination. The scarcity of anomalies and manual labeling has led to the development of various self-supervised MTS anomaly detection (AD) methods, which optimize an overall objective/loss encompassing all metrics' regression objectives/losses. However, our empirical study uncovers the prevalence of conflicts among metrics' regression objectives, causing MTS models to grapple with different losses. This critical aspect significantly impacts detection performance but has been overlooked in existing approaches. To address this problem, by mimicking the design of multi-gate mixture-of-experts (MMoE), we introduce CAD, a Conflict-aware multivariate KPI Anomaly Detection algorithm. CAD offers an exclusive structure for each metric to mitigate potential conflicts while fostering inter-metric promotions. Upon thorough investigation, we find that the poor performance of vanilla MMoE mainly comes from the input-output misalignment settings of MTS formulation and convergence issues arising from expansive tasks. To address these challenges, we propose a straightforward yet effective task-oriented metric selection and p&s (personalized and shared) gating mechanism, which establishes CAD as the first practicable multi-task learning (MTL) based MTS AD model. Evaluations on multiple public datasets reveal that CAD obtains an average F1-score of 0.943 across three public datasets, notably outperforming state-of-the-art methods. Our code is accessible at https://github.com/dawnvince/MTS_CAD.
Zero-Shot Learning by Harnessing Adversarial Samples
Aug 01, 2023Zero-Shot Learning (ZSL) aims to recognize unseen classes by generalizing the knowledge, i.e., visual and semantic relationships, obtained from seen classes, where image augmentation techniques are commonly applied to improve the generalization ability of a model. However, this approach can also cause adverse effects on ZSL since the conventional augmentation techniques that solely depend on single-label supervision is not able to maintain semantic information and result in the semantic distortion issue consequently. In other words, image argumentation may falsify the semantic (e.g., attribute) information of an image. To take the advantage of image augmentations while mitigating the semantic distortion issue, we propose a novel ZSL approach by Harnessing Adversarial Samples (HAS). HAS advances ZSL through adversarial training which takes into account three crucial aspects: (1) robust generation by enforcing augmentations to be similar to negative classes, while maintaining correct labels, (2) reliable generation by introducing a latent space constraint to avert significant deviations from the original data manifold, and (3) diverse generation by incorporating attribute-based perturbation by adjusting images according to each semantic attribute's localization. Through comprehensive experiments on three prominent zero-shot benchmark datasets, we demonstrate the effectiveness of our adversarial samples approach in both ZSL and Generalized Zero-Shot Learning (GZSL) scenarios. Our source code is available at https://github.com/uqzhichen/HASZSL.
VOLTA: Diverse and Controllable Question-Answer Pair Generation with Variational Mutual Information Maximizing Autoencoder
Jul 03, 2023



Previous question-answer pair generation methods aimed to produce fluent and meaningful question-answer pairs but tend to have poor diversity. Recent attempts addressing this issue suffer from either low model capacity or overcomplicated architecture. Furthermore, they overlooked the problem where the controllability of their models is highly dependent on the input. In this paper, we propose a model named VOLTA that enhances generative diversity by leveraging the Variational Autoencoder framework with a shared backbone network as its encoder and decoder. In addition, we propose adding InfoGAN-style latent codes to enable input-independent controllability over the generation process. We perform comprehensive experiments and the results show that our approach can significantly improve diversity and controllability over state-of-the-art models.
Segment Anything Is Not Always Perfect: An Investigation of SAM on Different Real-world Applications
Apr 13, 2023Recently, Meta AI Research approaches a general, promptable Segment Anything Model (SAM) pre-trained on an unprecedentedly large segmentation dataset (SA-1B). Without a doubt, the emergence of SAM will yield significant benefits for a wide array of practical image segmentation applications. In this study, we conduct a series of intriguing investigations into the performance of SAM across various applications, particularly in the fields of natural images, agriculture, manufacturing, remote sensing, and healthcare. We analyze and discuss the benefits and limitations of SAM and provide an outlook on future development of segmentation tasks. Note that our work does not intend to propose new algorithms or theories, but rather provide a comprehensive view of SAM in practice. This work is expected to provide insights that facilitate future research activities toward generic segmentation.
Imbalanced Open Set Domain Adaptation via Moving-threshold Estimation and Gradual Alignment
Mar 09, 2023



Multimedia applications are often associated with cross-domain knowledge transfer, where Unsupervised Domain Adaptation (UDA) can be used to reduce the domain shifts. Open Set Domain Adaptation (OSDA) aims to transfer knowledge from a well-labeled source domain to an unlabeled target domain under the assumption that the target domain contains unknown classes. Existing OSDA methods consistently lay stress on the covariate shift, ignoring the potential label shift problem. The performance of OSDA methods degrades drastically under intra-domain class imbalance and inter-domain label shift. However, little attention has been paid to this issue in the community. In this paper, the Imbalanced Open Set Domain Adaptation (IOSDA) is explored where the covariate shift, label shift and category mismatch exist simultaneously. To alleviate the negative effects raised by label shift in OSDA, we propose Open-set Moving-threshold Estimation and Gradual Alignment (OMEGA) - a novel architecture that improves existing OSDA methods on class-imbalanced data. Specifically, a novel unknown-aware target clustering scheme is proposed to form tight clusters in the target domain to reduce the negative effects of label shift and intra-domain class imbalance. Furthermore, moving-threshold estimation is designed to generate specific thresholds for each target sample rather than using one for all. Extensive experiments on IOSDA, OSDA and OPDA benchmarks demonstrate that our method could significantly outperform existing state-of-the-arts. Code and data are available at https://github.com/mendicant04/OMEGA.
A Comprehensive Survey on Source-free Domain Adaptation
Feb 23, 2023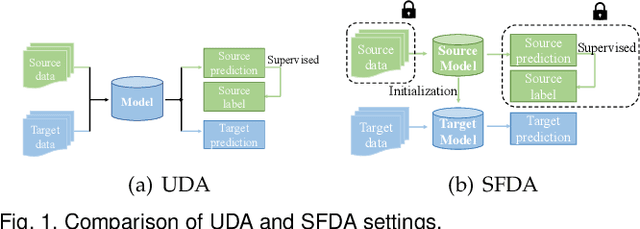

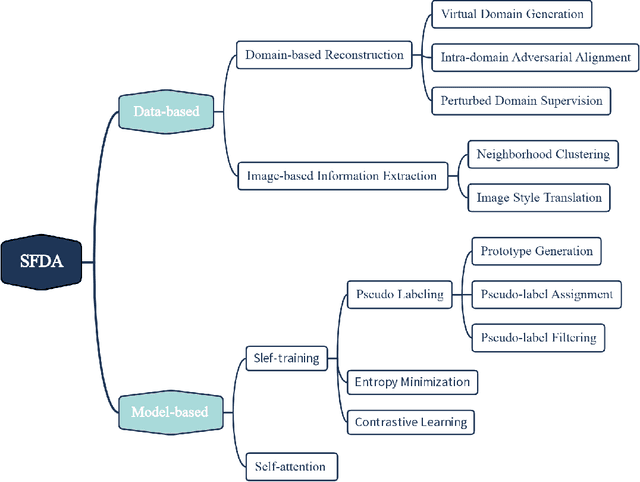

Over the past decade, domain adaptation has become a widely studied branch of transfer learning that aims to improve performance on target domains by leveraging knowledge from the source domain. Conventional domain adaptation methods often assume access to both source and target domain data simultaneously, which may not be feasible in real-world scenarios due to privacy and confidentiality concerns. As a result, the research of Source-Free Domain Adaptation (SFDA) has drawn growing attention in recent years, which only utilizes the source-trained model and unlabeled target data to adapt to the target domain. Despite the rapid explosion of SFDA work, yet there has no timely and comprehensive survey in the field. To fill this gap, we provide a comprehensive survey of recent advances in SFDA and organize them into a unified categorization scheme based on the framework of transfer learning. Instead of presenting each approach independently, we modularize several components of each method to more clearly illustrate their relationships and mechanics in light of the composite properties of each method. Furthermore, we compare the results of more than 30 representative SFDA methods on three popular classification benchmarks, namely Office-31, Office-home, and VisDA, to explore the effectiveness of various technical routes and the combination effects among them. Additionally, we briefly introduce the applications of SFDA and related fields. Drawing from our analysis of the challenges facing SFDA, we offer some insights into future research directions and potential settings.
Semantic Enhanced Knowledge Graph for Large-Scale Zero-Shot Learning
Dec 26, 2022Zero-Shot Learning has been a highlighted research topic in both vision and language areas. Recently, most existing methods adopt structured knowledge information to model explicit correlations among categories and use deep graph convolutional network to propagate information between different categories. However, it is difficult to add new categories to existing structured knowledge graph, and deep graph convolutional network suffers from over-smoothing problem. In this paper, we provide a new semantic enhanced knowledge graph that contains both expert knowledge and categories semantic correlation. Our semantic enhanced knowledge graph can further enhance the correlations among categories and make it easy to absorb new categories. To propagate information on the knowledge graph, we propose a novel Residual Graph Convolutional Network (ResGCN), which can effectively alleviate the problem of over-smoothing. Experiments conducted on the widely used large-scale ImageNet-21K dataset and AWA2 dataset show the effectiveness of our method, and establish a new state-of-the-art on zero-shot learning. Moreover, our results on the large-scale ImageNet-21K with various feature extraction networks show that our method has better generalization and robustness.
Minimizing Maximum Model Discrepancy for Transferable Black-box Targeted Attacks
Dec 18, 2022



In this work, we study the black-box targeted attack problem from the model discrepancy perspective. On the theoretical side, we present a generalization error bound for black-box targeted attacks, which gives a rigorous theoretical analysis for guaranteeing the success of the attack. We reveal that the attack error on a target model mainly depends on empirical attack error on the substitute model and the maximum model discrepancy among substitute models. On the algorithmic side, we derive a new algorithm for black-box targeted attacks based on our theoretical analysis, in which we additionally minimize the maximum model discrepancy(M3D) of the substitute models when training the generator to generate adversarial examples. In this way, our model is capable of crafting highly transferable adversarial examples that are robust to the model variation, thus improving the success rate for attacking the black-box model. We conduct extensive experiments on the ImageNet dataset with different classification models, and our proposed approach outperforms existing state-of-the-art methods by a significant margin. Our codes will be released.
Variational Model Perturbation for Source-Free Domain Adaptation
Oct 19, 2022
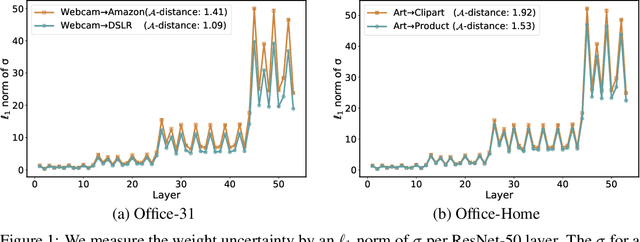
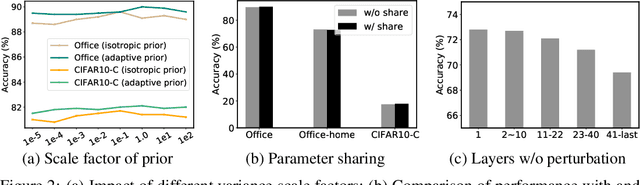
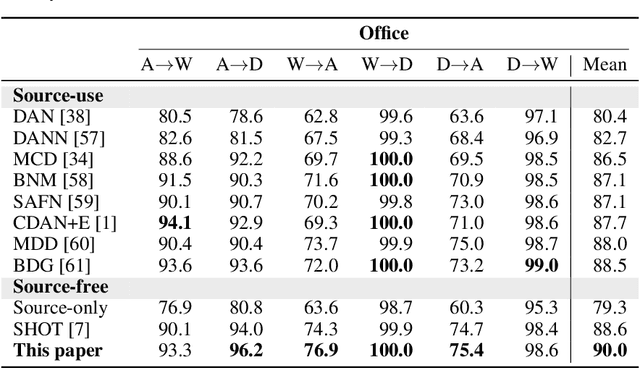
We aim for source-free domain adaptation, where the task is to deploy a model pre-trained on source domains to target domains. The challenges stem from the distribution shift from the source to the target domain, coupled with the unavailability of any source data and labeled target data for optimization. Rather than fine-tuning the model by updating the parameters, we propose to perturb the source model to achieve adaptation to target domains. We introduce perturbations into the model parameters by variational Bayesian inference in a probabilistic framework. By doing so, we can effectively adapt the model to the target domain while largely preserving the discriminative ability. Importantly, we demonstrate the theoretical connection to learning Bayesian neural networks, which proves the generalizability of the perturbed model to target domains. To enable more efficient optimization, we further employ a parameter sharing strategy, which substantially reduces the learnable parameters compared to a fully Bayesian neural network. Our model perturbation provides a new probabilistic way for domain adaptation which enables efficient adaptation to target domains while maximally preserving knowledge in source models. Experiments on several source-free benchmarks under three different evaluation settings verify the effectiveness of the proposed variational model perturbation for source-free domain adaptation.