 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Spatial Tuning
Nov 07, 2025Capturing spatial relationships from visual inputs is a cornerstone of human-like general intelligence. Several previous studies have tried to enhance the spatial awareness of Vision-Language Models (VLMs) by adding extra expert encoders, which brings extra overhead and usually harms general capabilities. To enhance the spatial ability in general architectures, we introduce Visual Spatial Tuning (VST), a comprehensive framework to cultivate VLMs with human-like visuospatial abilities, from spatial perception to reasoning. We first attempt to enhance spatial perception in VLMs by constructing a large-scale dataset termed VST-P, which comprises 4.1 million samples spanning 19 skills across single views, multiple images, and videos. Then, we present VST-R, a curated dataset with 135K samples that instruct models to reason in space. In particular, we adopt a progressive training pipeline: supervised fine-tuning to build foundational spatial knowledge, followed by reinforcement learning to further improve spatial reasoning abilities. Without the side-effect to general capabilities, the proposed VST consistently achieves state-of-the-art results on several spatial benchmarks, including $34.8\%$ on MMSI-Bench and $61.2\%$ on VSIBench. It turns out that the Vision-Language-Action models can be significantly enhanced with the proposed spatial tuning paradigm, paving the way for more physically grounded AI.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Beam Switching Based Beam Design for High-Speed Train mmWave Communications
Nov 27, 2024



For high-speed train (HST) millimeter wave (mmWave) communications, the use of narrow beams with small beam coverage needs frequent beam switching, while wider beams with small beam gain leads to weaker mmWave signal strength. In this paper, we consider beam switching based beam design, which is formulated as an optimization problem aiming to minimize the number of switched beams within a predetermined railway range subject to that the receiving signal-to-noise ratio (RSNR) at the HST is no lower than a predetermined threshold. To solve this problem, we propose two sequential beam design schemes, both including two alternately-performed stages. In the first stage, given an updated beam coverage according to the railway range, we transform the problem into a feasibility problem and further convert it into a min-max optimization problem by relaxing the RSNR constraints into a penalty of the objective function. In the second stage, we evaluate the feasibility of the beamformer obtained from solving the min-max problem and determine the beam coverage accordingly. Simulation results show that compared to the first scheme, the second scheme can achieve 96.20\% reduction in computational complexity at the cost of only 0.0657\% performance degradation.
Near-Field Communications for Extremely Large-Scale MIMO: A Beamspace Perspective
Oct 15, 2024



Extremely large-scale multiple-input multiple-output (XL-MIMO) is regarded as one of the key techniques to enhance the performance of future wireless communications. Different from regular MIMO, the XL-MIMO shifts part of the communication region from the far field to the near field, where the spherical-wave channel model cannot be accurately approximated by the commonly-adopted planar-wave channel model. As a result, the well-explored far-field beamspace is unsuitable for near-field communications, thereby requiring the exploration of specialized near-field beamspace. In this article, we investigate the near-field communications for XL-MIMO from the perspective of beamspace. Given the spherical wavefront characteristics of the near-field channels, we first map the antenna space to the near-field beamspace with the fractional Fourier transform. Then, we divide the near-field beamspace into three parts, including high mainlobe, low mainlobe, and sidelobe, and provide a comprehensive analysis of these components. Based on the analysis, we demonstrate the advantages of the near-field beamspace over the existing methods. Finally, we point out several applications of the near-field beamspace and highlight some potential directions for future study in the near-field beamspace.
Mug-STAN: Adapting Image-Language Pretrained Models for General Video Understanding
Nov 25, 2023Large-scale image-language pretrained models, e.g., CLIP, have demonstrated remarkable proficiency in acquiring general multi-modal knowledge through web-scale image-text data. Despite the impressive performance of image-language models on various image tasks, how to effectively expand them on general video understanding remains an area of ongoing exploration. In this paper, we investigate the image-to-video transferring from the perspective of the model and the data, unveiling two key obstacles impeding the adaptation of image-language models: non-generalizable temporal modeling and partially misaligned video-text data. To address these challenges, we propose Spatial-Temporal Auxiliary Network with Mutual-guided alignment module (Mug-STAN), a simple yet effective framework extending image-text model to diverse video tasks and video-text data.Specifically, STAN adopts a branch structure with decomposed spatial-temporal modules to enable generalizable temporal modeling, while Mug suppresses misalignment by introducing token-wise feature aggregation of either modality from the other. Extensive experimental results verify Mug-STAN significantly improves adaptation of language-image pretrained models such as CLIP and CoCa at both video-text post-pretraining and finetuning stages. With our solution, state-of-the-art zero-shot and finetuning results on various downstream datasets, including MSR-VTT, DiDeMo, LSMDC, Kinetics-400, Something-Something-2, HMDB-51, UCF- 101, and AVA, are achieved. Moreover, by integrating pretrained Mug-STAN with the emerging multimodal dialogue model, we can realize zero-shot video chatting. Codes are available at https://github.com/farewellthree/STAN
Associating Spatially-Consistent Grouping with Text-supervised Semantic Segmentation
Apr 03, 2023



In this work, we investigate performing semantic segmentation solely through the training on image-sentence pairs. Due to the lack of dense annotations, existing text-supervised methods can only learn to group an image into semantic regions via pixel-insensitive feedback. As a result, their grouped results are coarse and often contain small spurious regions, limiting the upper-bound performance of segmentation. On the other hand, we observe that grouped results from self-supervised models are more semantically consistent and break the bottleneck of existing methods. Motivated by this, we introduce associate self-supervised spatially-consistent grouping with text-supervised semantic segmentation. Considering the part-like grouped results, we further adapt a text-supervised model from image-level to region-level recognition with two core designs. First, we encourage fine-grained alignment with a one-way noun-to-region contrastive loss, which reduces the mismatched noun-region pairs. Second, we adopt a contextually aware masking strategy to enable simultaneous recognition of all grouped regions. Coupled with spatially-consistent grouping and region-adapted recognition, our method achieves 59.2% mIoU and 32.4% mIoU on Pascal VOC and Pascal Context benchmarks, significantly surpassing the state-of-the-art methods.
Revisiting Temporal Modeling for CLIP-based Image-to-Video Knowledge Transferring
Jan 26, 2023Image-text pretrained models, e.g., CLIP, have shown impressive general multi-modal knowledge learned from large-scale image-text data pairs, thus attracting increasing attention for their potential to improve visual representation learning in the video domain. In this paper, based on the CLIP model, we revisit temporal modeling in the context of image-to-video knowledge transferring, which is the key point for extending image-text pretrained models to the video domain. We find that current temporal modeling mechanisms are tailored to either high-level semantic-dominant tasks (e.g., retrieval) or low-level visual pattern-dominant tasks (e.g., recognition), and fail to work on the two cases simultaneously. The key difficulty lies in modeling temporal dependency while taking advantage of both high-level and low-level knowledge in CLIP model. To tackle this problem, we present Spatial-Temporal Auxiliary Network (STAN) -- a simple and effective temporal modeling mechanism extending CLIP model to diverse video tasks. Specifically, to realize both low-level and high-level knowledge transferring, STAN adopts a branch structure with decomposed spatial-temporal modules that enable multi-level CLIP features to be spatial-temporally contextualized. We evaluate our method on two representative video tasks: Video-Text Retrieval and Video Recognition. Extensive experiments demonstrate the superiority of our model over the state-of-the-art methods on various datasets, including MSR-VTT, DiDeMo, LSMDC, MSVD, Kinetics-400, and Something-Something-V2. Codes will be available at https://github.com/farewellthree/STAN
Temporal Perceiving Video-Language Pre-training
Jan 18, 2023Video-Language Pre-training models have recently significantly improved various multi-modal downstream tasks. Previous dominant works mainly adopt contrastive learning to achieve global feature alignment across modalities. However, the local associations between videos and texts are not modeled, restricting the pre-training models' generality, especially for tasks requiring the temporal video boundary for certain query texts. This work introduces a novel text-video localization pre-text task to enable fine-grained temporal and semantic alignment such that the trained model can accurately perceive temporal boundaries in videos given the text description. Specifically, text-video localization consists of moment retrieval, which predicts start and end boundaries in videos given the text description, and text localization which matches the subset of texts with the video features. To produce temporal boundaries, frame features in several videos are manually merged into a long video sequence that interacts with a text sequence. With the localization task, our method connects the fine-grained frame representations with the word representations and implicitly distinguishes representations of different instances in the single modality. Notably, comprehensive experimental results show that our method significantly improves the state-of-the-art performance on various benchmarks, covering text-to-video retrieval, video question answering, video captioning, temporal action localization and temporal moment retrieval. The code will be released soon.
Class Prototype-based Cleaner for Label Noise Learning
Dec 21, 2022



Semi-supervised learning based methods are current SOTA solutions to the noisy-label learning problem, which rely on learning an unsupervised label cleaner first to divide the training samples into a labeled set for clean data and an unlabeled set for noise data. Typically, the cleaner is obtained via fitting a mixture model to the distribution of per-sample training losses. However, the modeling procedure is \emph{class agnostic} and assumes the loss distributions of clean and noise samples are the same across different classes. Unfortunately, in practice, such an assumption does not always hold due to the varying learning difficulty of different classes, thus leading to sub-optimal label noise partition criteria. In this work, we reveal this long-ignored problem and propose a simple yet effective solution, named \textbf{C}lass \textbf{P}rototype-based label noise \textbf{C}leaner (\textbf{CPC}). Unlike previous works treating all the classes equally, CPC fully considers loss distribution heterogeneity and applies class-aware modulation to partition the clean and noise data. CPC takes advantage of loss distribution modeling and intra-class consistency regularization in feature space simultaneously and thus can better distinguish clean and noise labels. We theoretically justify the effectiveness of our method by explaining it from the Expectation-Maximization (EM) framework. Extensive experiments are conducted on the noisy-label benchmarks CIFAR-10, CIFAR-100, Clothing1M and WebVision. The results show that CPC consistently brings about performance improvement across all benchmarks. Codes and pre-trained models will be released at \url{https://github.com/hjjpku/CPC.git}.
Knowledge Guided Bidirectional Attention Network for Human-Object Interaction Detection
Jul 16, 2022
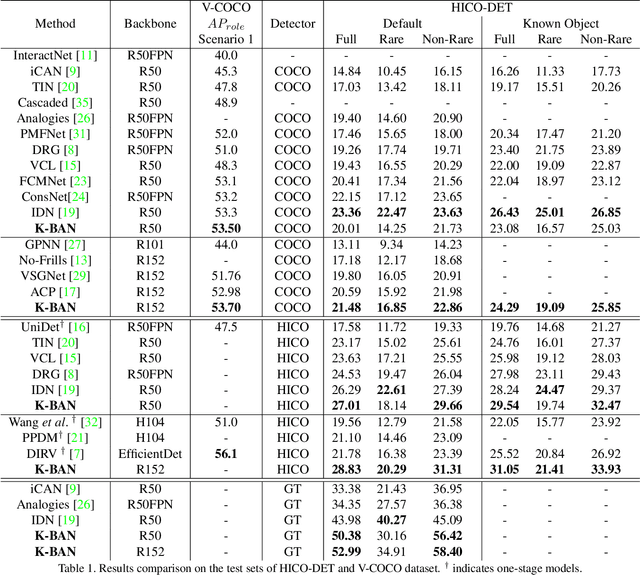
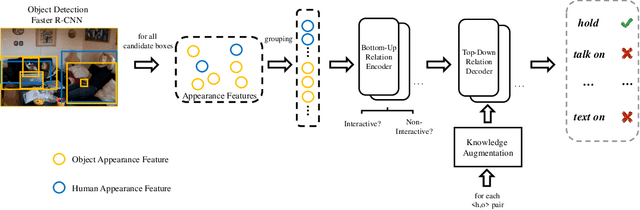
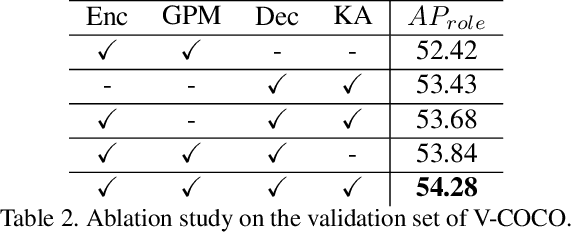
Human Object Interaction (HOI) detection is a challenging task that requires to distinguish the interaction between a human-object pair. Attention based relation parsing is a popular and effective strategy utilized in HOI. However, current methods execute relation parsing in a "bottom-up" manner. We argue that the independent use of the bottom-up parsing strategy in HOI is counter-intuitive and could lead to the diffusion of attention. Therefore, we introduce a novel knowledge-guided top-down attention into HOI, and propose to model the relation parsing as a "look and search" process: execute scene-context modeling (i.e. look), and then, given the knowledge of the target pair, search visual clues for the discrimination of the interaction between the pair. We implement the process via unifying the bottom-up and top-down attention in a single encoder-decoder based model. The experimental results show that our model achieves competitive performance on the V-COCO and HICO-DET datasets.