 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to bag with a simulation-free reinforcement learning framework for robots
Oct 22, 2023Bagging is an essential skill that humans perform in their daily activities. However, deformable objects, such as bags, are complex for robots to manipulate. This paper presents an efficient learning-based framework that enables robots to learn bagging. The novelty of this framework is its ability to perform bagging without relying on simulations. The learning process is accomplished through a reinforcement learning algorithm introduced in this work, designed to find the best grasping points of the bag based on a set of compact state representations. The framework utilizes a set of primitive actions and represents the task in five states. In our experiments, the framework reaches a 60 % and 80 % of success rate after around three hours of training in the real world when starting the bagging task from folded and unfolded, respectively. Finally, we test the trained model with two more bags of different sizes to evaluate its generalizability.
Learning from Few Demonstrations with Frame-Weighted Motion Generation
Mar 29, 2023Learning from Demonstration (LfD) aims to encode versatile skills from human demonstrations. The field has been gaining popularity since it facilitates knowledge transfer to robots without requiring expert knowledge in robotics. During task executions, the robot motion is usually influenced by constraints imposed by environments. In light of this, task-parameterized LfD (TP-LfD) encodes relevant contextual information in reference frames, enabling better skill generalization to new situations. However, most TP-LfD algorithms require multiple demonstrations in various environment conditions to ensure sufficient statistics for a meaningful model. It is not a trivial task for robot users to create different situations and perform demonstrations under all of them. Therefore, this paper presents a novel concept for learning motion policies from few demonstrations by finding the reference frame weights which capture frame importance/relevance during task executions. Experimental results in both simulation and real robotic environments validate our approach.
Robotic Fabric Flattening with Wrinkle Direction Detection
Mar 10, 2023Deformable Object Manipulation (DOM) is an important field of research as it contributes to practical tasks such as automatic cloth handling, cable routing, surgical operation, etc. Perception is considered one of the major challenges in DOM due to the complex dynamics and high degree of freedom of deformable objects. In this paper, we develop a novel image-processing algorithm based on Gabor filters to extract useful features from cloth, and based on this, devise a strategy for cloth flattening tasks. We evaluate the overall framework experimentally, and compare it with three human operators. The results show that our algorithm can determine the direction of wrinkles on the cloth accurately in the simulation as well as the real robot experiments. Besides, the robot executing the flattening tasks using the dewrinkling strategy given by our algorithm achieves satisfying performance compared to other baseline methods. The experiment video is available on https://sites.google.com/view/robotic-fabric-flattening/home
DASTSiam: Spatio-Temporal Fusion and Discriminative Augmentation for Improved Siamese Tracking
Jan 22, 2023



Tracking tasks based on deep neural networks have greatly improved with the emergence of Siamese trackers. However, the appearance of targets often changes during tracking, which can reduce the robustness of the tracker when facing challenges such as aspect ratio change, occlusion, and scale variation. In addition, cluttered backgrounds can lead to multiple high response points in the response map, leading to incorrect target positioning. In this paper, we introduce two transformer-based modules to improve Siamese tracking called DASTSiam: the spatio-temporal (ST) fusion module and the Discriminative Augmentation (DA) module. The ST module uses cross-attention based accumulation of historical cues to improve robustness against object appearance changes, while the DA module associates semantic information between the template and search region to improve target discrimination. Moreover, Modifying the label assignment of anchors also improves the reliability of the object location. Our modules can be used with all Siamese trackers and show improved performance on several public datasets through comparative and ablation experiments.
Do You Need a Hand? -- a Bimanual Robotic Dressing Assistance Scheme
Jan 19, 2023



Developing physically assistive robots capable of dressing assistance has the potential to significantly improve the lives of the elderly and disabled population. However, most robotics dressing strategies considered a single robot only, which greatly limited the performance of the dressing assistance. In fact, healthcare professionals perform the task bimanually. Inspired by them, we propose a bimanual cooperative scheme for robotic dressing assistance. In the scheme, an interactive robot joins hands with the human thus supporting/guiding the human in the dressing process, while the dressing robot performs the dressing task. We identify a key feature that affects the dressing action and propose an optimal strategy for the interactive robot using the feature. A dressing coordinate based on the posture of the arm is defined to better encode the dressing policy. We validate the interactive dressing scheme with extensive experiments and also an ablation study. The experiment video is available on https://sites.google.com/view/bimanualassitdressing/home
Improving transferability of 3D adversarial attacks with scale and shear transformations
Nov 02, 2022



Previous work has shown that 3D point cloud classifiers can be vulnerable to adversarial examples. However, most of the existing methods are aimed at white-box attacks, where the parameters and other information of the classifiers are known in the attack, which is unrealistic for real-world applications. In order to improve the attack performance of the black-box classifiers, the research community generally uses the transfer-based black-box attack. However, the transferability of current 3D attacks is still relatively low. To this end, this paper proposes Scale and Shear (SS) Attack to generate 3D adversarial examples with strong transferability. Specifically, we randomly scale or shear the input point cloud, so that the attack will not overfit the white-box model, thereby improving the transferability of the attack. Extensive experiments show that the SS attack proposed in this paper can be seamlessly combined with the existing state-of-the-art (SOTA) 3D point cloud attack methods to form more powerful attack methods, and the SS attack improves the transferability over 3.6 times compare to the baseline. Moreover, while substantially outperforming the baseline methods, the SS attack achieves SOTA transferability under various defenses. Our code will be available online at https://github.com/cuge1995/SS-attack
A Dual-Arm Collaborative Framework for Dexterous Manipulation in Unstructured Environments with Contrastive Planning
Sep 13, 2022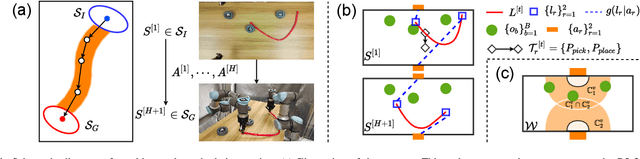
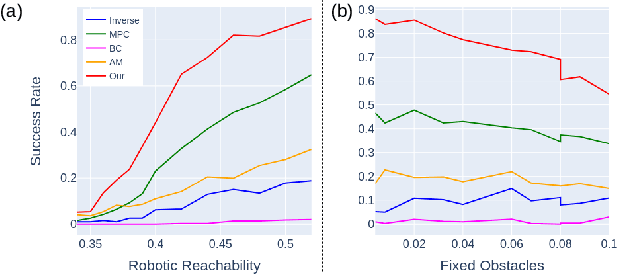
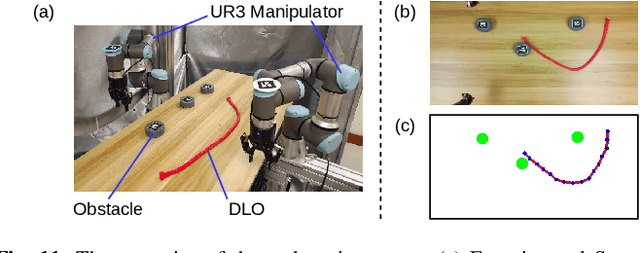
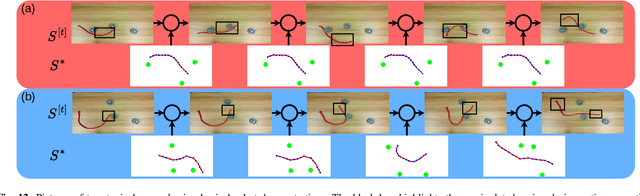
Most object manipulation strategies for robots are based on the assumption that the object is rigid (i.e., with fixed geometry) and the goal's details have been fully specified (e.g., the exact target pose). However, there are many tasks that involve spatial relations in human environments where these conditions may be hard to satisfy, e.g., bending and placing a cable inside an unknown container. To develop advanced robotic manipulation capabilities in unstructured environments that avoid these assumptions, we propose a novel long-horizon framework that exploits contrastive planning in finding promising collaborative actions. Using simulation data collected by random actions, we learn an embedding model in a contrastive manner that encodes the spatio-temporal information from successful experiences, which facilitates the subgoal planning through clustering in the latent space. Based on the keypoint correspondence-based action parameterization, we design a leader-follower control scheme for the collaboration between dual arms. All models of our policy are automatically trained in simulation and can be directly transferred to real-world environments. To validate the proposed framework, we conduct a detailed experimental study on a complex scenario subject to environmental and reachability constraints in both simulation and real environments.
Adversarial samples for deep monocular 6D object pose estimation
Mar 05, 2022


Estimating 6D object pose from an RGB image is important for many real-world applications such as autonomous driving and robotic grasping. Recent deep learning models have achieved significant progress on this task but their robustness received little research attention. In this work, for the first time, we study adversarial samples that can fool deep learning models with imperceptible perturbations to input image. In particular, we propose a Unified 6D pose estimation Attack, namely U6DA, which can successfully attack several state-of-the-art (SOTA) deep learning models for 6D pose estimation. The key idea of our U6DA is to fool the models to predict wrong results for object instance localization and shape that are essential for correct 6D pose estimation. Specifically, we explore a transfer-based black-box attack to 6D pose estimation. We design the U6DA loss to guide the generation of adversarial examples, the loss aims to shift the segmentation attention map away from its original position. We show that the generated adversarial samples are not only effective for direct 6D pose estimation models, but also are able to attack two-stage models regardless of their robust RANSAC modules. Extensive experiments were conducted to demonstrate the effectiveness, transferability, and anti-defense capability of our U6DA on large-scale public benchmarks. We also introduce a new U6DA-Linemod dataset for robustness study of the 6D pose estimation task. Our codes and dataset will be available at \url{https://github.com/cuge1995/U6DA}.
Boosting 3D Adversarial Attacks with Attacking On Frequency
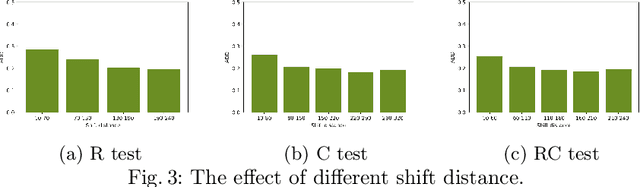
Jan 26, 2022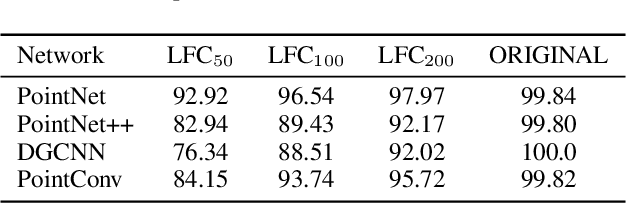
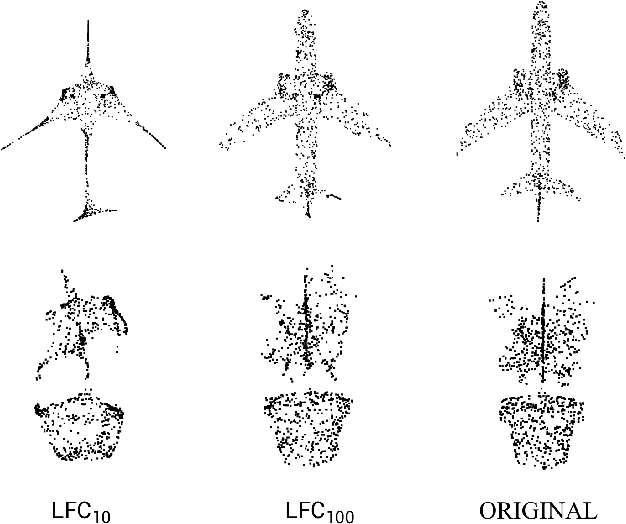
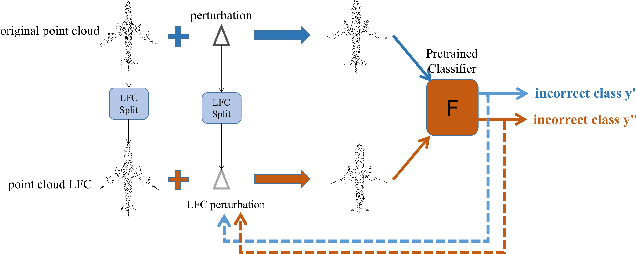
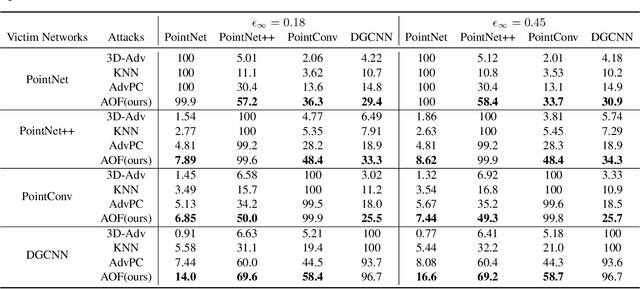
Deep neural networks (DNNs) have been shown to be vulnerable to adversarial attacks. Recently, 3D adversarial attacks, especially adversarial attacks on point clouds, have elicited mounting interest. However, adversarial point clouds obtained by previous methods show weak transferability and are easy to defend. To address these problems, in this paper we propose a novel point cloud attack (dubbed AOF) that pays more attention on the low-frequency component of point clouds. We combine the losses from point cloud and its low-frequency component to craft adversarial samples. Extensive experiments validate that AOF can improve the transferability significantly compared to state-of-the-art (SOTA) attacks, and is more robust to SOTA 3D defense methods. Otherwise, compared to clean point clouds, adversarial point clouds obtained by AOF contain more deformation than outlier.
Learning Task-Parameterized Skills from Few Demonstrations
Jan 24, 2022


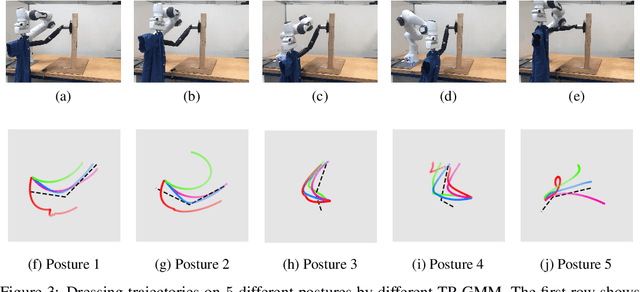
Moving away from repetitive tasks, robots nowadays demand versatile skills that adapt to different situations. Task-parameterized learning improves the generalization of motion policies by encoding relevant contextual information in the task parameters, hence enabling flexible task executions. However, training such a policy often requires collecting multiple demonstrations in different situations. To comprehensively create different situations is non-trivial thus renders the method less applicable to real-world problems. Therefore, training with fewer demonstrations/situations is desirable. This paper presents a novel concept to augment the original training dataset with synthetic data for policy improvements, thus allows learning task-parameterized skills with few demonstrations.