 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
Think Proprioceptively: Embodied Visual Reasoning for VLA Manipulation
Feb 06, 2026Vision-language-action (VLA) models typically inject proprioception only as a late conditioning signal, which prevents robot state from shaping instruction understanding and from influencing which visual tokens are attended throughout the policy. We introduce ThinkProprio, which converts proprioception into a sequence of text tokens in the VLM embedding space and fuses them with the task instruction at the input. This early fusion lets embodied state participate in subsequent visual reasoning and token selection, biasing computation toward action-critical evidence while suppressing redundant visual tokens. In a systematic ablation over proprioception encoding, state entry point, and action-head conditioning, we find that text tokenization is more effective than learned projectors, and that retaining roughly 15% of visual tokens can match the performance of using the full token set. Across CALVIN, LIBERO, and real-world manipulation, ThinkProprio matches or improves over strong baselines while reducing end-to-end inference latency over 50%.
Failure-Aware Bimanual Teleoperation via Conservative Value Guided Assistance
Feb 01, 2026Teleoperation of high-precision manipulation is con-strained by tight success tolerances and complex contact dy-namics, which make impending failures difficult for human operators to anticipate under partial observability. This paper proposes a value-guided, failure-aware framework for bimanual teleoperation that provides compliant haptic assistance while pre-serving continuous human authority. The framework is trained entirely from heterogeneous offline teleoperation data containing both successful and failed executions. Task feasibility is mod-eled as a conservative success score learned via Conservative Value Learning, yielding a risk-sensitive estimate that remains reliable under distribution shift. During online operation, the learned success score regulates the level of assistance, while a learned actor provides a corrective motion direction. Both are integrated through a joint-space impedance interface on the master side, yielding continuous guidance that steers the operator away from failure-prone actions without overriding intent. Experimental results on contact-rich manipulation tasks demonstrate improved task success rates and reduced operator workload compared to conventional teleoperation and shared-autonomy baselines, indicating that conservative value learning provides an effective mechanism for embedding failure awareness into bilateral teleoperation. Experimental videos are available at https://www.youtube.com/watch?v=XDTsvzEkDRE
UniBiDex: A Unified Teleoperation Framework for Robotic Bimanual Dexterous Manipulation
Jan 08, 2026We present UniBiDex a unified teleoperation framework for robotic bimanual dexterous manipulation that supports both VRbased and leaderfollower input modalities UniBiDex enables realtime contactrich dualarm teleoperation by integrating heterogeneous input devices into a shared control stack with consistent kinematic treatment and safety guarantees The framework employs nullspace control to optimize bimanual configurations ensuring smooth collisionfree and singularityaware motion across tasks We validate UniBiDex on a longhorizon kitchentidying task involving five sequential manipulation subtasks demonstrating higher task success rates smoother trajectories and improved robustness compared to strong baselines By releasing all hardware and software components as opensource we aim to lower the barrier to collecting largescale highquality human demonstration datasets and accelerate progress in robot learning.
Prescribed Performance Control of Deformable Object Manipulation in Spatial Latent Space
Oct 16, 2025Manipulating three-dimensional (3D) deformable objects presents significant challenges for robotic systems due to their infinite-dimensional state space and complex deformable dynamics. This paper proposes a novel model-free approach for shape control with constraints imposed on key points. Unlike existing methods that rely on feature dimensionality reduction, the proposed controller leverages the coordinates of key points as the feature vector, which are extracted from the deformable object's point cloud using deep learning methods. This approach not only reduces the dimensionality of the feature space but also retains the spatial information of the object. By extracting key points, the manipulation of deformable objects is simplified into a visual servoing problem, where the shape dynamics are described using a deformation Jacobian matrix. To enhance control accuracy, a prescribed performance control method is developed by integrating barrier Lyapunov functions (BLF) to enforce constraints on the key points. The stability of the closed-loop system is rigorously analyzed and verified using the Lyapunov method. Experimental results further demonstrate the effectiveness and robustness of the proposed method.
HuBE: Cross-Embodiment Human-like Behavior Execution for Humanoid Robots
Aug 26, 2025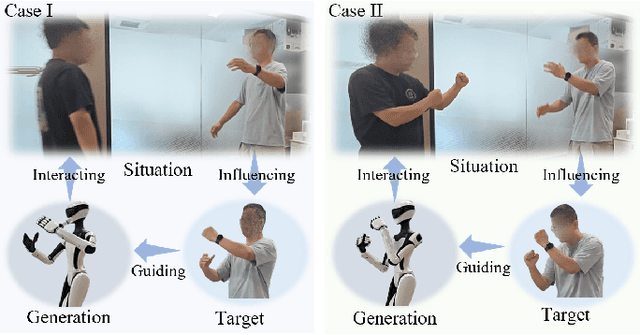
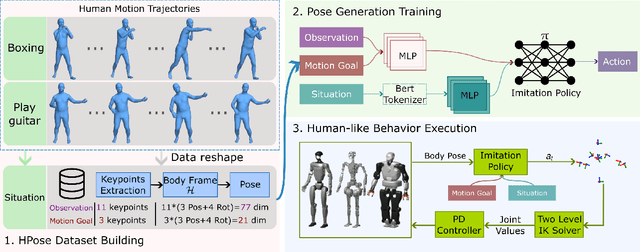

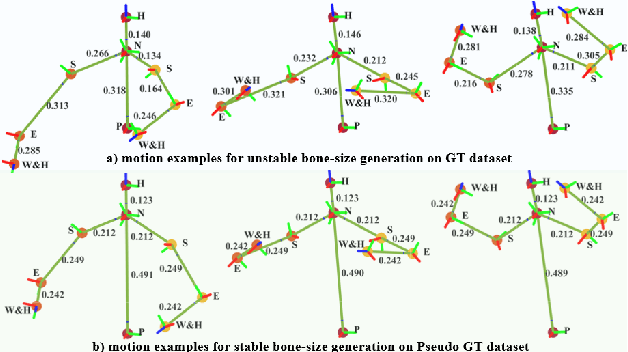
Achieving both behavioral similarity and appropriateness in human-like motion generation for humanoid robot remains an open challenge, further compounded by the lack of cross-embodiment adaptability. To address this problem, we propose HuBE, a bi-level closed-loop framework that integrates robot state, goal poses, and contextual situations to generate human-like behaviors, ensuring both behavioral similarity and appropriateness, and eliminating structural mismatches between motion generation and execution. To support this framework, we construct HPose, a context-enriched dataset featuring fine-grained situational annotations. Furthermore, we introduce a bone scaling-based data augmentation strategy that ensures millimeter-level compatibility across heterogeneous humanoid robots. Comprehensive evaluations on multiple commercial platforms demonstrate that HuBE significantly improves motion similarity, behavioral appropriateness, and computational efficiency over state-of-the-art baselines, establishing a solid foundation for transferable and human-like behavior execution across diverse humanoid robots.
Instruction-Augmented Long-Horizon Planning: Embedding Grounding Mechanisms in Embodied Mobile Manipulation
Mar 11, 2025Enabling humanoid robots to perform long-horizon mobile manipulation planning in real-world environments based on embodied perception and comprehension abilities has been a longstanding challenge. With the recent rise of large language models (LLMs), there has been a notable increase in the development of LLM-based planners. These approaches either utilize human-provided textual representations of the real world or heavily depend on prompt engineering to extract such representations, lacking the capability to quantitatively understand the environment, such as determining the feasibility of manipulating objects. To address these limitations, we present the Instruction-Augmented Long-Horizon Planning (IALP) system, a novel framework that employs LLMs to generate feasible and optimal actions based on real-time sensor feedback, including grounded knowledge of the environment, in a closed-loop interaction. Distinct from prior works, our approach augments user instructions into PDDL problems by leveraging both the abstract reasoning capabilities of LLMs and grounding mechanisms. By conducting various real-world long-horizon tasks, each consisting of seven distinct manipulatory skills, our results demonstrate that the IALP system can efficiently solve these tasks with an average success rate exceeding 80%. Our proposed method can operate as a high-level planner, equipping robots with substantial autonomy in unstructured environments through the utilization of multi-modal sensor inputs.
* 17 pages, 11 figures
Encircling General 2-D Boundaries by Mobile Robots with Collision Avoidance: A Vector Field Guided Approach
Jan 04, 2025The ability to automatically encircle boundaries with mobile robots is crucial for tasks such as border tracking and object enclosing. Previous research has primarily focused on regular boundaries, often assuming that their geometric equations are known in advance, which is not often the case in practice. In this paper, we investigate a more general case and propose an algorithm that addresses geometric irregularities of boundaries without requiring prior knowledge of their analytical expressions. To achieve this, we develop a Fourier-based curve fitting method for boundary approximation using sampled points, enabling parametric characterization of general 2-D boundaries. This approach allows star-shaped boundaries to be fitted into polar-angle-based parametric curves, while boundaries of other shapes are handled through decomposition. Then, we design a vector field (VF) to achieve the encirclement of the parameterized boundary, wherein a polar radius error is introduced to measure the robot's ``distance'' to the boundary. The controller is finally synthesized using a control barrier function and quadratic programming to mediate some potentially conflicting specifications: boundary encirclement, obstacle avoidance, and limited actuation. In this manner, the VF-guided reference control not only guides the boundary encircling action, but can also be minimally modified to satisfy obstacle avoidance and input saturation constraints. Simulations and experiments are presented to verify the performance of our new method, which can be applied to mobile robots to perform practical tasks such as cleaning chemical spills and environment monitoring.
Non-Prehensile Tool-Object Manipulation by Integrating LLM-Based Planning and Manoeuvrability-Driven Controls
Dec 09, 2024The ability to wield tools was once considered exclusive to human intelligence, but it's now known that many other animals, like crows, possess this capability. Yet, robotic systems still fall short of matching biological dexterity. In this paper, we investigate the use of Large Language Models (LLMs), tool affordances, and object manoeuvrability for non-prehensile tool-based manipulation tasks. Our novel method leverages LLMs based on scene information and natural language instructions to enable symbolic task planning for tool-object manipulation. This approach allows the system to convert the human language sentence into a sequence of feasible motion functions. We have developed a novel manoeuvrability-driven controller using a new tool affordance model derived from visual feedback. This controller helps guide the robot's tool utilization and manipulation actions, even within confined areas, using a stepping incremental approach. The proposed methodology is evaluated with experiments to prove its effectiveness under various manipulation scenarios.
Revolutionizing Packaging: A Robotic Bagging Pipeline with Constraint-aware Structure-of-Interest Planning
Mar 15, 2024



Bagging operations, common in packaging and assisted living applications, are challenging due to a bag's complex deformable properties. To address this, we develop a robotic system for automated bagging tasks using an adaptive structure-of-interest (SOI) manipulation approach. Our method relies on real-time visual feedback to dynamically adjust manipulation without requiring prior knowledge of bag materials or dynamics. We present a robust pipeline featuring state estimation for SOIs using Gaussian Mixture Models (GMM), SOI generation via optimization-based bagging techniques, SOI motion planning with Constrained Bidirectional Rapidly-exploring Random Trees (CBiRRT), and dual-arm manipulation coordinated by Model Predictive Control (MPC). Experiments demonstrate the system's ability to achieve precise, stable bagging of various objects using adaptive coordination of the manipulators. The proposed framework advances the capability of dual-arm robots to perform more sophisticated automation of common tasks involving interactions with deformable objects.