 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Robustness of Summarization Models by Detecting and Removing Input Noise
Dec 20, 2022



The evaluation of abstractive summarization models typically uses test data that is identically distributed as training data. In real-world practice, documents to be summarized may contain input noise caused by text extraction artifacts or data pipeline bugs. The robustness of model performance under distribution shift caused by such noise is relatively under-studied. We present a large empirical study quantifying the sometimes severe loss in performance (up to 12 ROUGE-1 points) from different types of input noise for a range of datasets and model sizes. We then propose a light-weight method for detecting and removing such noise in the input during model inference without requiring any extra training, auxiliary models, or even prior knowledge of the type of noise. Our proposed approach effectively mitigates the loss in performance, recovering a large fraction of the performance drop, sometimes as large as 11 ROUGE-1 points.
Improving Zero-shot Generalization and Robustness of Multi-modal Models
Dec 04, 2022



Multi-modal image-text models such as CLIP and LiT have demonstrated impressive performance on image classification benchmarks and their zero-shot generalization ability is particularly exciting. While the top-5 zero-shot accuracies of these models are very high, the top-1 accuracies are much lower (over 25% gap in some cases). We investigate the reasons for this performance gap and find that many of the failure cases are caused by ambiguity in the text prompts. First, we develop a simple and efficient zero-shot post-hoc method to identify images whose top-1 prediction is likely to be incorrect, by measuring consistency of the predictions w.r.t. multiple prompts and image transformations. We show that our procedure better predicts mistakes, outperforming the popular max logit baseline on selective prediction tasks. Next, we propose a simple and efficient way to improve accuracy on such uncertain images by making use of the WordNet hierarchy; specifically we augment the original class by incorporating its parent and children from the semantic label hierarchy, and plug the augmentation into text promts. We conduct experiments on both CLIP and LiT models with five different ImageNet-based datasets. For CLIP, our method improves the top-1 accuracy by 17.13% on the uncertain subset and 3.6% on the entire ImageNet validation set. We also show that our method improves across ImageNet shifted datasets and other model architectures such as LiT. Our proposed method is hyperparameter-free, requires no additional model training and can be easily scaled to other large multi-modal architectures.
TorchOpt: An Efficient Library for Differentiable Optimization
Nov 13, 2022



Recent years have witnessed the booming of various differentiable optimization algorithms. These algorithms exhibit different execution patterns, and their execution needs massive computational resources that go beyond a single CPU and GPU. Existing differentiable optimization libraries, however, cannot support efficient algorithm development and multi-CPU/GPU execution, making the development of differentiable optimization algorithms often cumbersome and expensive. This paper introduces TorchOpt, a PyTorch-based efficient library for differentiable optimization. TorchOpt provides a unified and expressive differentiable optimization programming abstraction. This abstraction allows users to efficiently declare and analyze various differentiable optimization programs with explicit gradients, implicit gradients, and zero-order gradients. TorchOpt further provides a high-performance distributed execution runtime. This runtime can fully parallelize computation-intensive differentiation operations (e.g. tensor tree flattening) on CPUs / GPUs and automatically distribute computation to distributed devices. Experimental results show that TorchOpt achieves $5.2\times$ training time speedup on an 8-GPU server. TorchOpt is available at: https://github.com/metaopt/torchopt/.
Transferable Unlearnable Examples
Oct 18, 2022


With more people publishing their personal data online, unauthorized data usage has become a serious concern. The unlearnable strategies have been introduced to prevent third parties from training on the data without permission. They add perturbations to the users' data before publishing, which aims to make the models trained on the perturbed published dataset invalidated. These perturbations have been generated for a specific training setting and a target dataset. However, their unlearnable effects significantly decrease when used in other training settings and datasets. To tackle this issue, we propose a novel unlearnable strategy based on Classwise Separability Discriminant (CSD), which aims to better transfer the unlearnable effects to other training settings and datasets by enhancing the linear separability. Extensive experiments demonstrate the transferability of the proposed unlearnable examples across training settings and datasets.
Probabilistic Categorical Adversarial Attack & Adversarial Training
Oct 17, 2022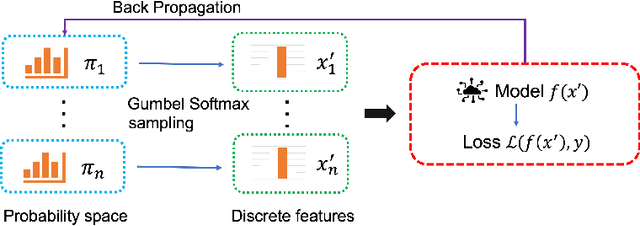
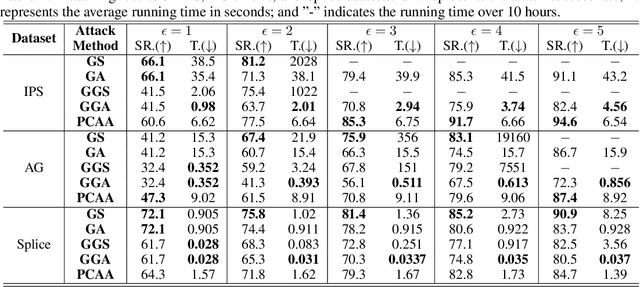
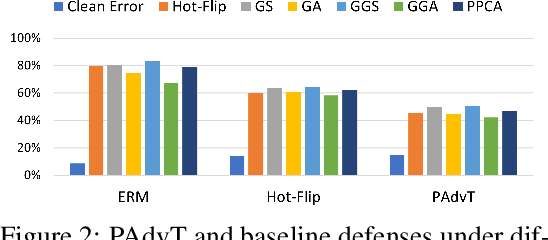

The existence of adversarial examples brings huge concern for people to apply Deep Neural Networks (DNNs) in safety-critical tasks. However, how to generate adversarial examples with categorical data is an important problem but lack of extensive exploration. Previously established methods leverage greedy search method, which can be very time-consuming to conduct successful attack. This also limits the development of adversarial training and potential defenses for categorical data. To tackle this problem, we propose Probabilistic Categorical Adversarial Attack (PCAA), which transfers the discrete optimization problem to a continuous problem that can be solved efficiently by Projected Gradient Descent. In our paper, we theoretically analyze its optimality and time complexity to demonstrate its significant advantage over current greedy based attacks. Moreover, based on our attack, we propose an efficient adversarial training framework. Through a comprehensive empirical study, we justify the effectiveness of our proposed attack and defense algorithms.
Out-of-Distribution Detection and Selective Generation for Conditional Language Models
Sep 30, 2022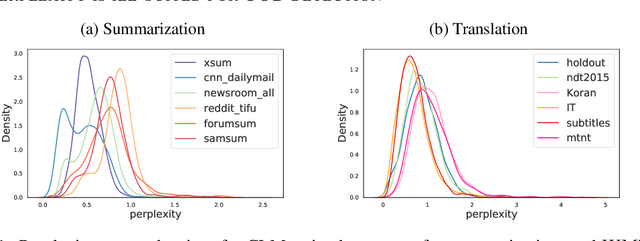
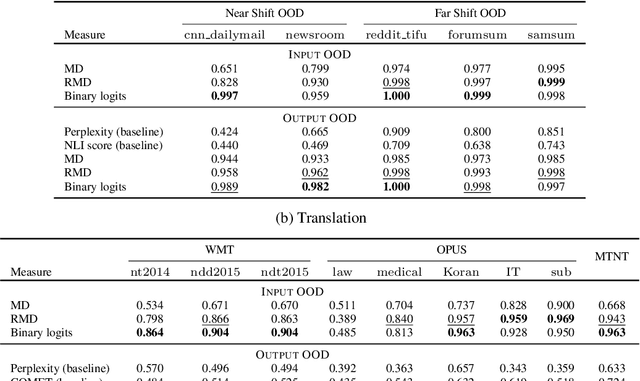
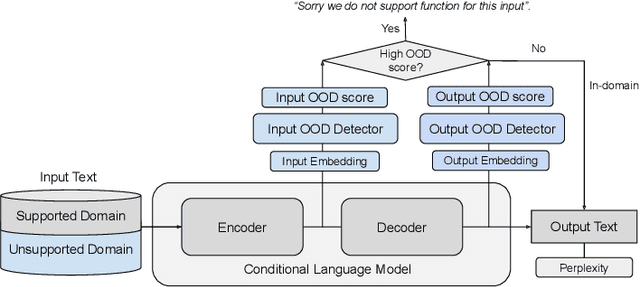
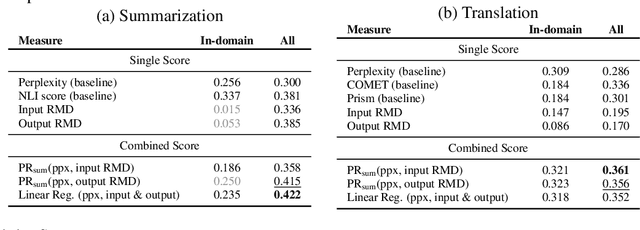
Machine learning algorithms typically assume independent and identically distributed samples in training and at test time. Much work has shown that high-performing ML classifiers can degrade significantly and provide overly-confident, wrong classification predictions, particularly for out-of-distribution (OOD) inputs. Conditional language models (CLMs) are predominantly trained to classify the next token in an output sequence, and may suffer even worse degradation on OOD inputs as the prediction is done auto-regressively over many steps. Furthermore, the space of potential low-quality outputs is larger as arbitrary text can be generated and it is important to know when to trust the generated output. We present a highly accurate and lightweight OOD detection method for CLMs, and demonstrate its effectiveness on abstractive summarization and translation. We also show how our method can be used under the common and realistic setting of distribution shift for selective generation (analogous to selective prediction for classification) of high-quality outputs, while automatically abstaining from low-quality ones, enabling safer deployment of generative language models.
Exemplar-Based Image Colorization with A Learning Framework
Sep 13, 2022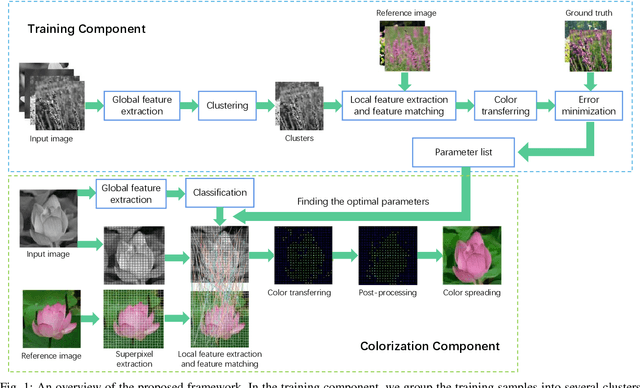



Image learning and colorization are hot spots in multimedia domain. Inspired by the learning capability of humans, in this paper, we propose an automatic colorization method with a learning framework. This method can be viewed as a hybrid of exemplar-based and learning-based method, and it decouples the colorization process and learning process so as to generate various color styles for the same gray image. The matching process in the exemplar-based colorization method can be regarded as a parameterized function, and we employ a large amount of color images as the training samples to fit the parameters. During the training process, the color images are the ground truths, and we learn the optimal parameters for the matching process by minimizing the errors in terms of the parameters for the matching function. To deal with images with various compositions, a global feature is introduced, which can be used to classify the images with respect to their compositions, and then learn the optimal matching parameters for each image category individually. What's more, a spatial consistency based post-processing is design to smooth the extracted color information from the reference image to remove matching errors. Extensive experiments are conducted to verify the effectiveness of the method, and it achieves comparable performance against the state-of-the-art colorization algorithms.
Color Image Edge Detection using Multi-scale and Multi-directional Gabor filter
Aug 16, 2022
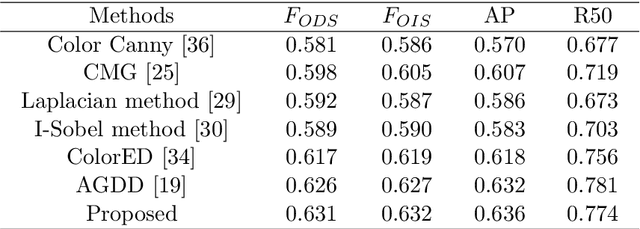

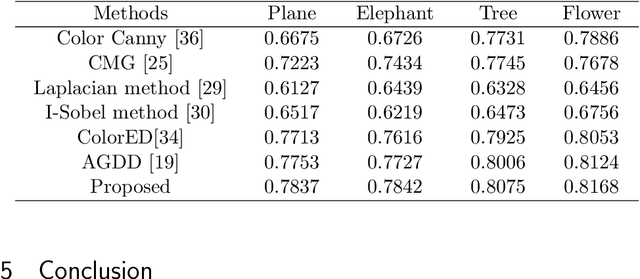
In this paper, a color edge detection method is proposed where the multi-scale Gabor filter are used to obtain edges from input color images. The main advantage of the proposed method is that high edge detection accuracy is attained while maintaining good noise robustness. The proposed method consists of three aspects: First, the RGB color image is converted to CIE L*a*b* space because of its wide coloring area and uniform color distribution. Second, a set of Gabor filters are used to smooth the input images and the color edge strength maps are extracted, which are fused into a new ESM with the noise robustness and accurate edge extraction. Third, Embedding the fused ESM in the route of the Canny detector yields a noise-robust color edge detector. The results show that the proposed detector has the better experience in detection accuracy and noise-robustness.
Proving Common Mechanisms Shared by Twelve Methods of Boosting Adversarial Transferability
Jul 24, 2022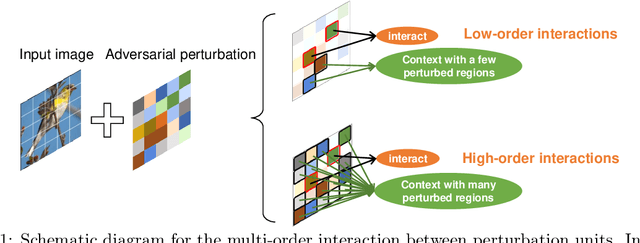
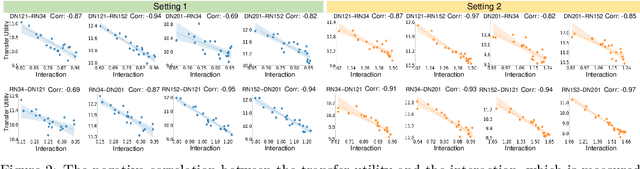
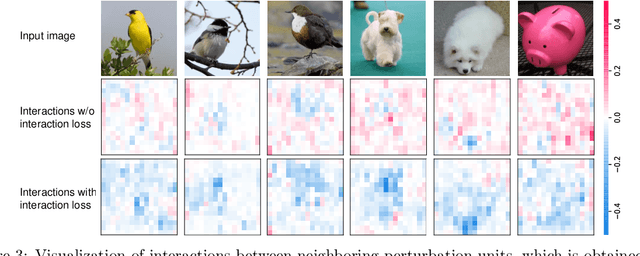
Although many methods have been proposed to enhance the transferability of adversarial perturbations, these methods are designed in a heuristic manner, and the essential mechanism for improving adversarial transferability is still unclear. This paper summarizes the common mechanism shared by twelve previous transferability-boosting methods in a unified view, i.e., these methods all reduce game-theoretic interactions between regional adversarial perturbations. To this end, we focus on the attacking utility of all interactions between regional adversarial perturbations, and we first discover and prove the negative correlation between the adversarial transferability and the attacking utility of interactions. Based on this discovery, we theoretically prove and empirically verify that twelve previous transferability-boosting methods all reduce interactions between regional adversarial perturbations. More crucially, we consider the reduction of interactions as the essential reason for the enhancement of adversarial transferability. Furthermore, we design the interaction loss to directly penalize interactions between regional adversarial perturbations during attacking. Experimental results show that the interaction loss significantly improves the transferability of adversarial perturbations.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022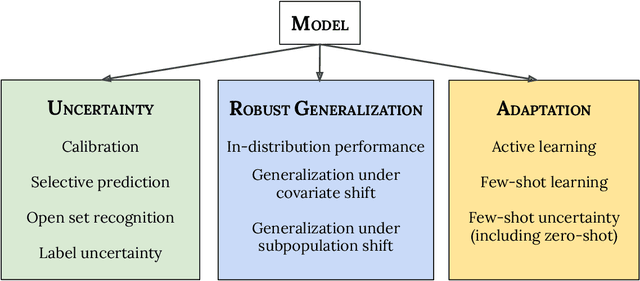

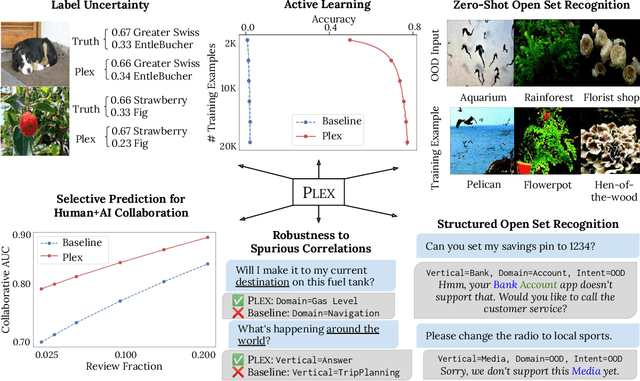

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.