 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Scaling Exponents Across Parameterizations and Optimizers
Jul 08, 2024



Robust and effective scaling of models from small to large width typically requires the precise adjustment of many algorithmic and architectural details, such as parameterization and optimizer choices. In this work, we propose a new perspective on parameterization by investigating a key assumption in prior work about the alignment between parameters and data and derive new theoretical results under weaker assumptions and a broader set of optimizers. Our extensive empirical investigation includes tens of thousands of models trained with all combinations of three optimizers, four parameterizations, several alignment assumptions, more than a dozen learning rates, and fourteen model sizes up to 26.8B parameters. We find that the best learning rate scaling prescription would often have been excluded by the assumptions in prior work. Our results show that all parameterizations, not just maximal update parameterization (muP), can achieve hyperparameter transfer; moreover, our novel per-layer learning rate prescription for standard parameterization outperforms muP. Finally, we demonstrate that an overlooked aspect of parameterization, the epsilon parameter in Adam, must be scaled correctly to avoid gradient underflow and propose Adam-atan2, a new numerically stable, scale-invariant version of Adam that eliminates the epsilon hyperparameter entirely.
LiPO: Listwise Preference Optimization through Learning-to-Rank
Feb 02, 2024



Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a listwise ranking problem and describe the Listwise Preference Optimization (LiPO) framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives, especially pairwise ones. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment withDPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-{\lambda}, which leverages a state-of-the-art listwise ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-{\lambda} can outperform DPO and SLiC by a clear margin on two preference alignment tasks.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Dec 22, 2023



Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Self-Evaluation Improves Selective Generation in Large Language Models
Dec 14, 2023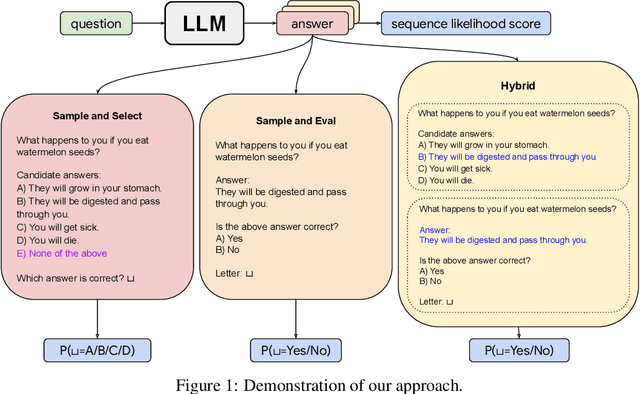

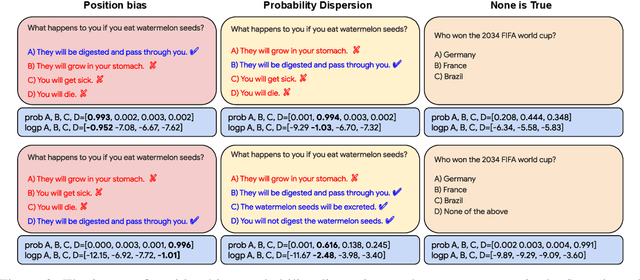

Safe deployment of large language models (LLMs) may benefit from a reliable method for assessing their generated content to determine when to abstain or to selectively generate. While likelihood-based metrics such as perplexity are widely employed, recent research has demonstrated the limitations of using sequence-level probability estimates given by LLMs as reliable indicators of generation quality. Conversely, LLMs have demonstrated strong calibration at the token level, particularly when it comes to choosing correct answers in multiple-choice questions or evaluating true/false statements. In this work, we reformulate open-ended generation tasks into token-level prediction tasks, and leverage LLMs' superior calibration at the token level. We instruct an LLM to self-evaluate its answers, employing either a multi-way comparison or a point-wise evaluation approach, with the option to include a ``None of the above'' option to express the model's uncertainty explicitly. We benchmark a range of scoring methods based on self-evaluation and evaluate their performance in selective generation using TruthfulQA and TL;DR. Through experiments with PaLM-2 and GPT-3, we demonstrate that self-evaluation based scores not only improve accuracy, but also correlate better with the overall quality of generated content.
Frontier Language Models are not Robust to Adversarial Arithmetic, or "What do I need to say so you agree 2+2=5?
Nov 15, 2023



We introduce and study the problem of adversarial arithmetic, which provides a simple yet challenging testbed for language model alignment. This problem is comprised of arithmetic questions posed in natural language, with an arbitrary adversarial string inserted before the question is complete. Even in the simple setting of 1-digit addition problems, it is easy to find adversarial prompts that make all tested models (including PaLM2, GPT4, Claude2) misbehave, and even to steer models to a particular wrong answer. We additionally provide a simple algorithm for finding successful attacks by querying those same models, which we name "prompt inversion rejection sampling" (PIRS). We finally show that models can be partially hardened against these attacks via reinforcement learning and via agentic constitutional loops. However, we were not able to make a language model fully robust against adversarial arithmetic attacks.
Improving Large Language Model Fine-tuning for Solving Math Problems
Oct 16, 2023Despite their success in many natural language tasks, solving math problems remains a significant challenge for large language models (LLMs). A large gap exists between LLMs' pass-at-one and pass-at-N performance in solving math problems, suggesting LLMs might be close to finding correct solutions, motivating our exploration of fine-tuning methods to unlock LLMs' performance. Using the challenging MATH dataset, we investigate three fine-tuning strategies: (1) solution fine-tuning, where we fine-tune to generate a detailed solution for a given math problem; (2) solution-cluster re-ranking, where the LLM is fine-tuned as a solution verifier/evaluator to choose among generated candidate solution clusters; (3) multi-task sequential fine-tuning, which integrates both solution generation and evaluation tasks together efficiently to enhance the LLM performance. With these methods, we present a thorough empirical study on a series of PaLM 2 models and find: (1) The quality and style of the step-by-step solutions used for fine-tuning can make a significant impact on the model performance; (2) While solution re-ranking and majority voting are both effective for improving the model performance when used separately, they can also be used together for an even greater performance boost; (3) Multi-task fine-tuning that sequentially separates the solution generation and evaluation tasks can offer improved performance compared with the solution fine-tuning baseline. Guided by these insights, we design a fine-tuning recipe that yields approximately 58.8% accuracy on the MATH dataset with fine-tuned PaLM 2-L models, an 11.2% accuracy improvement over the few-shot performance of pre-trained PaLM 2-L model with majority voting.
Small-scale proxies for large-scale Transformer training instabilities
Sep 25, 2023



Teams that have trained large Transformer-based models have reported training instabilities at large scale that did not appear when training with the same hyperparameters at smaller scales. Although the causes of such instabilities are of scientific interest, the amount of resources required to reproduce them has made investigation difficult. In this work, we seek ways to reproduce and study training stability and instability at smaller scales. First, we focus on two sources of training instability described in previous work: the growth of logits in attention layers (Dehghani et al., 2023) and divergence of the output logits from the log probabilities (Chowdhery et al., 2022). By measuring the relationship between learning rate and loss across scales, we show that these instabilities also appear in small models when training at high learning rates, and that mitigations previously employed at large scales are equally effective in this regime. This prompts us to investigate the extent to which other known optimizer and model interventions influence the sensitivity of the final loss to changes in the learning rate. To this end, we study methods such as warm-up, weight decay, and the $\mu$Param (Yang et al., 2022), and combine techniques to train small models that achieve similar losses across orders of magnitude of learning rate variation. Finally, to conclude our exploration we study two cases where instabilities can be predicted before they emerge by examining the scaling behavior of model activation and gradient norms.
Statistical Rejection Sampling Improves Preference Optimization
Sep 13, 2023



Improving the alignment of language models with human preferences remains an active research challenge. Previous approaches have primarily utilized Reinforcement Learning from Human Feedback (RLHF) via online RL methods such as Proximal Policy Optimization (PPO). Recently, offline methods such as Sequence Likelihood Calibration (SLiC) and Direct Preference Optimization (DPO) have emerged as attractive alternatives, offering improvements in stability and scalability while maintaining competitive performance. SLiC refines its loss function using sequence pairs sampled from a supervised fine-tuned (SFT) policy, while DPO directly optimizes language models based on preference data, foregoing the need for a separate reward model. However, the maximum likelihood estimator (MLE) of the target optimal policy requires labeled preference pairs sampled from that policy. DPO's lack of a reward model constrains its ability to sample preference pairs from the optimal policy, and SLiC is restricted to sampling preference pairs only from the SFT policy. To address these limitations, we introduce a novel approach called Statistical Rejection Sampling Optimization (RSO) that aims to source preference data from the target optimal policy using rejection sampling, enabling a more accurate estimation of the optimal policy. We also propose a unified framework that enhances the loss functions used in both SLiC and DPO from a preference modeling standpoint. Through extensive experiments across three diverse tasks, we demonstrate that RSO consistently outperforms both SLiC and DPO on evaluations from both Large Language Model (LLM) and human raters.
SLiC-HF: Sequence Likelihood Calibration with Human Feedback
May 17, 2023Learning from human feedback has been shown to be effective at aligning language models with human preferences. Past work has often relied on Reinforcement Learning from Human Feedback (RLHF), which optimizes the language model using reward scores assigned from a reward model trained on human preference data. In this work we show how the recently introduced Sequence Likelihood Calibration (SLiC), can also be used to effectively learn from human preferences (SLiC-HF). Furthermore, we demonstrate this can be done with human feedback data collected for a different model, similar to off-policy, offline RL data. Automatic and human evaluation experiments on the TL;DR summarization task show that SLiC-HF significantly improves supervised fine-tuning baselines. Furthermore, SLiC-HF presents a competitive alternative to the PPO RLHF implementation used in past work while being much simpler to implement, easier to tune and more computationally efficient in practice.