 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamicBench: Evaluating Real-Time Report Generation in Large Language Models
Jun 26, 2025Traditional benchmarks for large language models (LLMs) typically rely on static evaluations through storytelling or opinion expression, which fail to capture the dynamic requirements of real-time information processing in contemporary applications. To address this limitation, we present DynamicBench, a benchmark designed to evaluate the proficiency of LLMs in storing and processing up-to-the-minute data. DynamicBench utilizes a dual-path retrieval pipeline, integrating web searches with local report databases. It necessitates domain-specific knowledge, ensuring accurate responses report generation within specialized fields. By evaluating models in scenarios that either provide or withhold external documents, DynamicBench effectively measures their capability to independently process recent information or leverage contextual enhancements. Additionally, we introduce an advanced report generation system adept at managing dynamic information synthesis. Our experimental results confirm the efficacy of our approach, with our method achieving state-of-the-art performance, surpassing GPT4o in document-free and document-assisted scenarios by 7.0% and 5.8%, respectively. The code and data will be made publicly available.
TGDPO: Harnessing Token-Level Reward Guidance for Enhancing Direct Preference Optimization
Jun 17, 2025Recent advancements in reinforcement learning from human feedback have shown that utilizing fine-grained token-level reward models can substantially enhance the performance of Proximal Policy Optimization (PPO) in aligning large language models. However, it is challenging to leverage such token-level reward as guidance for Direct Preference Optimization (DPO), since DPO is formulated as a sequence-level bandit problem. To address this challenge, this work decomposes the sequence-level PPO into a sequence of token-level proximal policy optimization problems and then frames the problem of token-level PPO with token-level reward guidance, from which closed-form optimal token-level policy and the corresponding token-level reward can be derived. Using the obtained reward and Bradley-Terry model, this work establishes a framework of computable loss functions with token-level reward guidance for DPO, and proposes a practical reward guidance based on the induced DPO reward. This formulation enables different tokens to exhibit varying degrees of deviation from reference policy based on their respective rewards. Experiment results demonstrate that our method achieves substantial performance improvements over DPO, with win rate gains of up to 7.5 points on MT-Bench, 6.2 points on AlpacaEval 2, and 4.3 points on Arena-Hard. Code is available at https://github.com/dvlab-research/TGDPO.
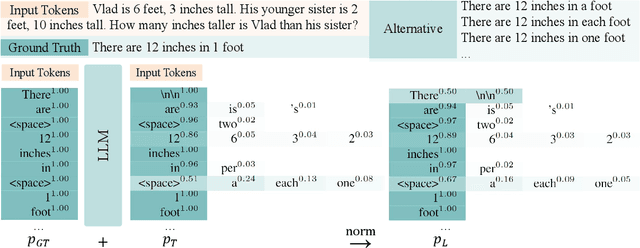
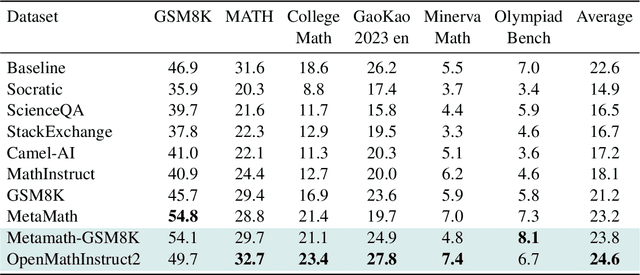
Logits-Based Finetuning
May 30, 2025

The core of out-of-distribution (OOD) detection is to learn the in-distribution (ID) representation, which is distinguishable from OOD samples. Previous work applied recognition-based methods to learn the ID features, which tend to learn shortcuts instead of comprehensive representations. In this work, we find surprisingly that simply using reconstruction-based methods could boost the performance of OOD detection significantly. We deeply explore the main contributors of OOD detection and find that reconstruction-based pretext tasks have the potential to provide a generally applicable and efficacious prior, which benefits the model in learning intrinsic data distributions of the ID dataset. Specifically, we take Masked Image Modeling as a pretext task for our OOD detection framework (MOOD). Without bells and whistles, MOOD outperforms previous SOTA of one-class OOD detection by 5.7%, multi-class OOD detection by 3.0%, and near-distribution OOD detection by 2.1%. It even defeats the 10-shot-per-class outlier exposure OOD detection, although we do not include any OOD samples for our detection. Codes are available at https://github.com/JulietLJY/MOOD.
RTime-QA: A Benchmark for Atomic Temporal Event Understanding in Large Multi-modal Models
May 25, 2025Understanding accurate atomic temporal event is essential for video comprehension. However, current video-language benchmarks often fall short to evaluate Large Multi-modal Models' (LMMs) temporal event understanding capabilities, as they can be effectively addressed using image-language models. In this paper, we introduce RTime-QA, a novel benchmark specifically designed to assess the atomic temporal event understanding ability of LMMs. RTime-QA comprises 822 high-quality, carefully-curated video-text questions, each meticulously annotated by human experts. Each question features a video depicting an atomic temporal event, paired with both correct answers and temporal negative descriptions, specifically designed to evaluate temporal understanding. To advance LMMs' temporal event understanding ability, we further introduce RTime-IT, a 14k instruction-tuning dataset that employs a similar annotation process as RTime-QA. Extensive experimental analysis demonstrates that RTime-QA presents a significant challenge for LMMs: the state-of-the-art model Qwen2-VL achieves only 34.6 on strict-ACC metric, substantially lagging behind human performance. Furthermore, our experiments reveal that RTime-IT effectively enhance LMMs' capacity in temporal understanding. By fine-tuning on RTime-IT, our Qwen2-VL achieves 65.9 on RTime-QA.
Training-Free Efficient Video Generation via Dynamic Token Carving
May 22, 2025



Despite the remarkable generation quality of video Diffusion Transformer (DiT) models, their practical deployment is severely hindered by extensive computational requirements. This inefficiency stems from two key challenges: the quadratic complexity of self-attention with respect to token length and the multi-step nature of diffusion models. To address these limitations, we present Jenga, a novel inference pipeline that combines dynamic attention carving with progressive resolution generation. Our approach leverages two key insights: (1) early denoising steps do not require high-resolution latents, and (2) later steps do not require dense attention. Jenga introduces a block-wise attention mechanism that dynamically selects relevant token interactions using 3D space-filling curves, alongside a progressive resolution strategy that gradually increases latent resolution during generation. Experimental results demonstrate that Jenga achieves substantial speedups across multiple state-of-the-art video diffusion models while maintaining comparable generation quality (8.83$\times$ speedup with 0.01\% performance drop on VBench). As a plug-and-play solution, Jenga enables practical, high-quality video generation on modern hardware by reducing inference time from minutes to seconds -- without requiring model retraining. Code: https://github.com/dvlab-research/Jenga
ARPO:End-to-End Policy Optimization for GUI Agents with Experience Replay
May 22, 2025



Training large language models (LLMs) as interactive agents for controlling graphical user interfaces (GUIs) presents a unique challenge to optimize long-horizon action sequences with multimodal feedback from complex environments. While recent works have advanced multi-turn reinforcement learning (RL) for reasoning and tool-using capabilities in LLMs, their application to GUI-based agents remains relatively underexplored due to the difficulty of sparse rewards, delayed feedback, and high rollout costs. In this paper, we investigate end-to-end policy optimization for vision-language-based GUI agents with the aim of improving performance on complex, long-horizon computer tasks. We propose Agentic Replay Policy Optimization (ARPO), an end-to-end RL approach that augments Group Relative Policy Optimization (GRPO) with a replay buffer to reuse the successful experience across training iterations. To further stabilize the training process, we propose a task selection strategy that filters tasks based on baseline agent performance, allowing the agent to focus on learning from informative interactions. Additionally, we compare ARPO with offline preference optimization approaches, highlighting the advantages of policy-based methods in GUI environments. Experiments on the OSWorld benchmark demonstrate that ARPO achieves competitive results, establishing a new performance baseline for LLM-based GUI agents trained via reinforcement learning. Our findings underscore the effectiveness of reinforcement learning for training multi-turn, vision-language GUI agents capable of managing complex real-world UI interactions. Codes and models:https://github.com/dvlab-research/ARPO.git.
VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning
May 17, 2025Large vision-language models exhibit inherent capabilities to handle diverse visual perception tasks. In this paper, we introduce VisionReasoner, a unified framework capable of reasoning and solving multiple visual perception tasks within a shared model. Specifically, by designing novel multi-object cognitive learning strategies and systematic task reformulation, VisionReasoner enhances its reasoning capabilities to analyze visual inputs, and addresses diverse perception tasks in a unified framework. The model generates a structured reasoning process before delivering the desired outputs responding to user queries. To rigorously assess unified visual perception capabilities, we evaluate VisionReasoner on ten diverse tasks spanning three critical domains: detection, segmentation, and counting. Experimental results show that VisionReasoner achieves superior performance as a unified model, outperforming Qwen2.5VL by relative margins of 29.1% on COCO (detection), 22.1% on ReasonSeg (segmentation), and 15.3% on CountBench (counting).
TraveLLaMA: Facilitating Multi-modal Large Language Models to Understand Urban Scenes and Provide Travel Assistance
Apr 23, 2025Tourism and travel planning increasingly rely on digital assistance, yet existing multimodal AI systems often lack specialized knowledge and contextual understanding of urban environments. We present TraveLLaMA, a specialized multimodal language model designed for urban scene understanding and travel assistance. Our work addresses the fundamental challenge of developing practical AI travel assistants through a novel large-scale dataset of 220k question-answer pairs. This comprehensive dataset uniquely combines 130k text QA pairs meticulously curated from authentic travel forums with GPT-enhanced responses, alongside 90k vision-language QA pairs specifically focused on map understanding and scene comprehension. Through extensive fine-tuning experiments on state-of-the-art vision-language models (LLaVA, Qwen-VL, Shikra), we demonstrate significant performance improvements ranging from 6.5\%-9.4\% in both pure text travel understanding and visual question answering tasks. Our model exhibits exceptional capabilities in providing contextual travel recommendations, interpreting map locations, and understanding place-specific imagery while offering practical information such as operating hours and visitor reviews. Comparative evaluations show TraveLLaMA significantly outperforms general-purpose models in travel-specific tasks, establishing a new benchmark for multi-modal travel assistance systems.
STEVE: AStep Verification Pipeline for Computer-use Agent Training
Mar 16, 2025Developing AI agents to autonomously manipulate graphical user interfaces is a long challenging task. Recent advances in data scaling law inspire us to train computer-use agents with a scaled instruction set, yet using behavior cloning to train agents still requires immense high-quality trajectories. To meet the scalability need, we designed STEVE, a step verification pipeline for computer-use agent training. First, we establish a large instruction set for computer-use agents and collect trajectory data with some suboptimal agents. GPT-4o is used to verify the correctness of each step in the trajectories based on the screens before and after the action execution, assigning each step with a binary label. Last, we adopt the Kahneman and Tversky Optimization to optimize the agent from the binary stepwise labels. Extensive experiments manifest that our agent outperforms supervised finetuning by leveraging both positive and negative actions within a trajectory. Also, STEVE enables us to train a 7B vision-language model as a computer-use agent, achieving leading performance in the challenging live desktop environment WinAgentArena with great efficiency at a reduced cost. Code and data: https://github.com/FanbinLu/STEVE.
Does Your Vision-Language Model Get Lost in the Long Video Sampling Dilemma?
Mar 16, 2025



The rise of Large Vision-Language Models (LVLMs) has significantly advanced video understanding. However, efficiently processing long videos remains a challenge due to the ``Sampling Dilemma'': low-density sampling risks missing critical information, while high-density sampling introduces redundancy. To address this issue, we introduce LSDBench, the first benchmark designed to evaluate LVLMs on long-video tasks by constructing high Necessary Sampling Density (NSD) questions, where NSD represents the minimum sampling density required to accurately answer a given question. LSDBench focuses on dense, short-duration actions to rigorously assess the sampling strategies employed by LVLMs. To tackle the challenges posed by high-NSD questions, we propose a novel Reasoning-Driven Hierarchical Sampling (RHS) framework, which combines global localization of question-relevant cues with local dense sampling for precise inference. Additionally, we develop a lightweight Semantic-Guided Frame Selector to prioritize informative frames, enabling RHS to achieve comparable or superior performance with significantly fewer sampled frames. Together, our LSDBench and RHS framework address the unique challenges of high-NSD long-video tasks, setting a new standard for evaluating and improving LVLMs in this domain.