 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
The Primacy of Magnitude in Low-Rank Adaptation
Jul 09, 2025Low-Rank Adaptation (LoRA) offers a parameter-efficient paradigm for tuning large models. While recent spectral initialization methods improve convergence and performance over the naive "Noise & Zeros" scheme, their extra computational and storage overhead undermines efficiency. In this paper, we establish update magnitude as the fundamental driver of LoRA performance and propose LoRAM, a magnitude-driven "Basis & Basis" initialization scheme that matches spectral methods without their inefficiencies. Our key contributions are threefold: (i) Magnitude of weight updates determines convergence. We prove low-rank structures intrinsically bound update magnitudes, unifying hyperparameter tuning in learning rate, scaling factor, and initialization as mechanisms to optimize magnitude regulation. (ii) Spectral initialization succeeds via magnitude amplification. We demystify that the presumed knowledge-driven benefit of the spectral component essentially arises from the boost in the weight update magnitude. (iii) A novel and compact initialization strategy, LoRAM, scales deterministic orthogonal bases using pretrained weight magnitudes to simulate spectral gains. Extensive experiments show that LoRAM serves as a strong baseline, retaining the full efficiency of LoRA while matching or outperforming spectral initialization across benchmarks.
RLHGNN: Reinforcement Learning-driven Heterogeneous Graph Neural Network for Next Activity Prediction in Business Processes
Jul 03, 2025Next activity prediction represents a fundamental challenge for optimizing business processes in service-oriented architectures such as microservices environments, distributed enterprise systems, and cloud-native platforms, which enables proactive resource allocation and dynamic service composition. Despite the prevalence of sequence-based methods, these approaches fail to capture non-sequential relationships that arise from parallel executions and conditional dependencies. Even though graph-based approaches address structural preservation, they suffer from homogeneous representations and static structures that apply uniform modeling strategies regardless of individual process complexity characteristics. To address these limitations, we introduce RLHGNN, a novel framework that transforms event logs into heterogeneous process graphs with three distinct edge types grounded in established process mining theory. Our approach creates four flexible graph structures by selectively combining these edges to accommodate different process complexities, and employs reinforcement learning formulated as a Markov Decision Process to automatically determine the optimal graph structure for each specific process instance. RLHGNN then applies heterogeneous graph convolution with relation-specific aggregation strategies to effectively predict the next activity. This adaptive methodology enables precise modeling of both sequential and non-sequential relationships in service interactions. Comprehensive evaluation on six real-world datasets demonstrates that RLHGNN consistently outperforms state-of-the-art approaches. Furthermore, it maintains an inference latency of approximately 1 ms per prediction, representing a highly practical solution suitable for real-time business process monitoring applications. The source code is available at https://github.com/Joker3993/RLHGNN.
GPR Full-Waveform Inversion through Adaptive Filtering of Model Parameters and Gradients Using CNN
Oct 11, 2024



GPR full-waveform inversion optimizes the subsurface property model iteratively to match the entire waveform information. However, the model gradients derived from wavefield continuation often contain errors, such as ghost values and excessively large values at transmitter and receiver points. Furthermore, models updated based on these gradients frequently exhibit unclear characterization of anomalous bodies or false anomalies, making it challenging to obtain accurate inversion results. To address these issues, we introduced a novel full-waveform inversion (FWI) framework that incorporates an embedded convolutional neural network (CNN) to adaptively filter model parameters and gradients. Specifically, we embedded the CNN module before the forward modeling process and ensured the entire FWI process remains differentiable. This design leverages the auto-grad tool of the deep learning library, allowing model values to pass through the CNN module during forward computation and model gradients to pass through the CNN module during backpropagation. Experiments have shown that filtering the model parameters during forward computation and the model gradients during backpropagation can ultimately yield high-quality inversion results.
Logic-of-Thought: Injecting Logic into Contexts for Full Reasoning in Large Language Models
Sep 26, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks but their performance in complex logical reasoning tasks remains unsatisfactory. Although some prompting methods, such as Chain-of-Thought, can improve the reasoning ability of LLMs to some extent, they suffer from an unfaithful issue where derived conclusions may not align with the generated reasoning chain. To address this issue, some studies employ the approach of propositional logic to further enhance logical reasoning abilities of LLMs. However, the potential omissions in the extraction of logical expressions in these methods can cause information loss in the logical reasoning process, thereby generating incorrect results. To this end, we propose Logic-of-Thought (LoT) prompting which employs propositional logic to generate expanded logical information from input context, and utilizes the generated logical information as an additional augmentation to the input prompts, thereby enhancing the capability of logical reasoning. The LoT is orthogonal to existing prompting methods and can be seamlessly integrated with them. Extensive experiments demonstrate that LoT boosts the performance of various prompting methods with a striking margin across five logical reasoning tasks. In particular, the LoT enhances Chain-of-Thought's performance on the ReClor dataset by +4.35%; moreover, it improves Chain-of-Thought with Self-Consistency's performance on LogiQA by +5%; additionally, it boosts performance of Tree-of-Thoughts on ProofWriter dataset by +8%.
Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval
Jul 31, 2024



Generative retrieval (GR) has emerged as a transformative paradigm in search and recommender systems, leveraging numeric-based identifier representations to enhance efficiency and generalization. Notably, methods like TIGER employing Residual Quantization-based Semantic Identifiers (RQ-SID), have shown significant promise in e-commerce scenarios by effectively managing item IDs. However, a critical issue termed the "\textbf{Hourglass}" phenomenon, occurs in RQ-SID, where intermediate codebook tokens become overly concentrated, hindering the full utilization of generative retrieval methods. This paper analyses and addresses this problem by identifying data sparsity and long-tailed distribution as the primary causes. Through comprehensive experiments and detailed ablation studies, we analyze the impact of these factors on codebook utilization and data distribution. Our findings reveal that the "Hourglass" phenomenon substantially impacts the performance of RQ-SID in generative retrieval. We propose effective solutions to mitigate this issue, thereby significantly enhancing the effectiveness of generative retrieval in real-world E-commerce applications.
LB-KBQA: Large-language-model and BERT based Knowledge-Based Question and Answering System
Feb 09, 2024

Generative Artificial Intelligence (AI), because of its emergent abilities, has empowered various fields, one typical of which is large language models (LLMs). One of the typical application fields of Generative AI is large language models (LLMs), and the natural language understanding capability of LLM is dramatically improved when compared with conventional AI-based methods. The natural language understanding capability has always been a barrier to the intent recognition performance of the Knowledge-Based-Question-and-Answer (KBQA) system, which arises from linguistic diversity and the newly appeared intent. Conventional AI-based methods for intent recognition can be divided into semantic parsing-based and model-based approaches. However, both of the methods suffer from limited resources in intent recognition. To address this issue, we propose a novel KBQA system based on a Large Language Model(LLM) and BERT (LB-KBQA). With the help of generative AI, our proposed method could detect newly appeared intent and acquire new knowledge. In experiments on financial domain question answering, our model has demonstrated superior effectiveness.
Age of Incorrect Information in Semantic Communications for NOMA Aided XR Applications
May 16, 2023



As an evolving successor to the mobile Internet, the extended reality (XR) devices can generate a fully digital immersive environment similar to the real world, integrating integrating virtual and real-world elements. However, in addition to the difficulties encountered in traditional communications, there emerge a range of new challenges such as ultra-massive access, real-time synchronization as well as unprecedented amount of multi-modal data transmission and processing. To address these challenges, semantic communications might be harnessed in support of XR applications, whereas it lacks a practical and effective performance metric. For broadening a new path for evaluating semantic communications, in this paper, we construct a multi-user uplink non-orthogonal multiple access (NOMA) system to analyze its transmission performance by harnessing a novel metric called age of incorrect information (AoII). First, we derive the average semantic similarity of all the users based on DeepSC and obtain the closed-form expressions for the packets' age of information (AoI) relying on queue theory. Besides, we formulate a non-convex optimization problem for the proposed AoII which combines both error-and AoI-based performance under the constraints of semantic rate, transmit power and status update rate. Finally, in order to solve the problem, we apply an exact linear search based algorithm for finding the optimal policy. Simulation results show that the AoII metric can beneficially evaluate both the error- and AoI-based transmission performance simultaneously.
Alleviating Cold-start Problem in CTR Prediction with A Variational Embedding Learning Framework
Jan 17, 2022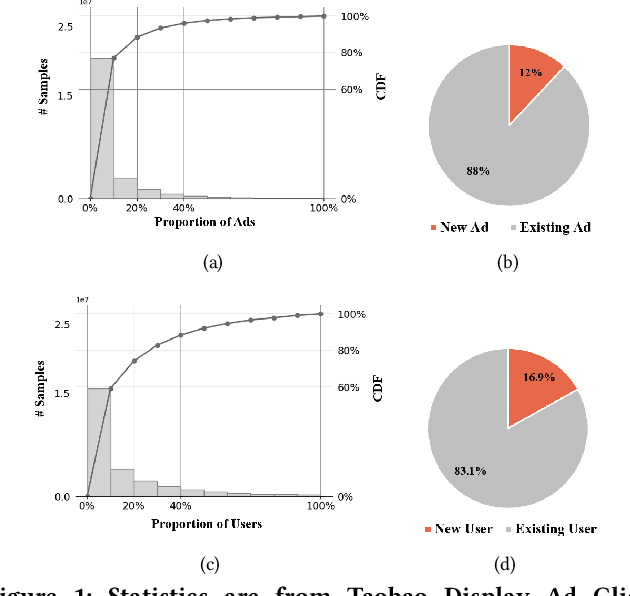

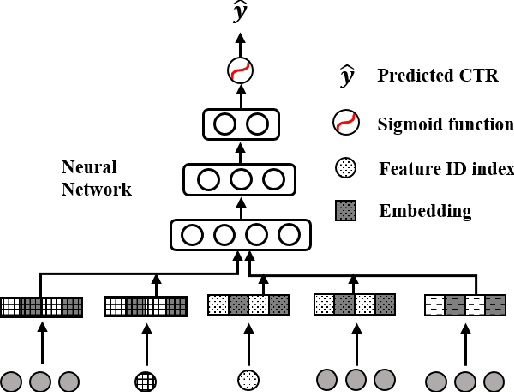
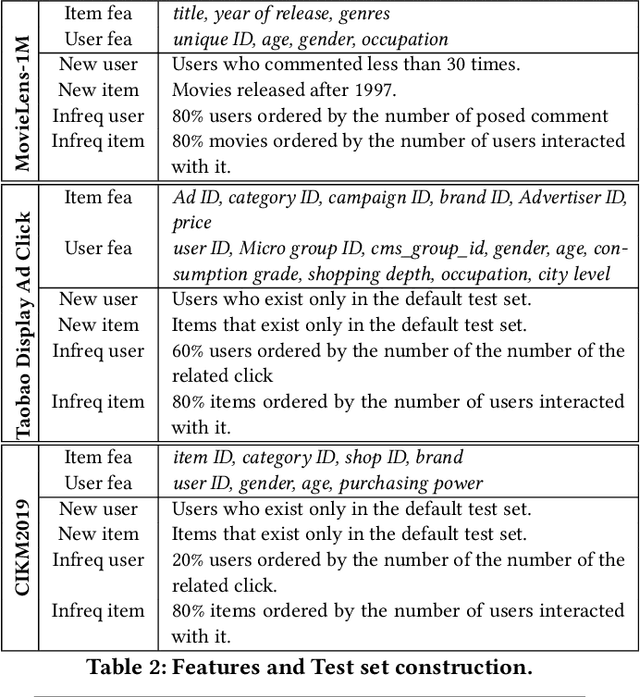
We propose a general Variational Embedding Learning Framework (VELF) for alleviating the severe cold-start problem in CTR prediction. VELF addresses the cold start problem via alleviating over-fits caused by data-sparsity in two ways: learning probabilistic embedding, and incorporating trainable and regularized priors which utilize the rich side information of cold start users and advertisements (Ads). The two techniques are naturally integrated into a variational inference framework, forming an end-to-end training process. Abundant empirical tests on benchmark datasets well demonstrate the advantages of our proposed VELF. Besides, extended experiments confirmed that our parameterized and regularized priors provide more generalization capability than traditional fixed priors.
Joint Channel and Weight Pruning for Model Acceleration on Moblie Devices
Nov 09, 2021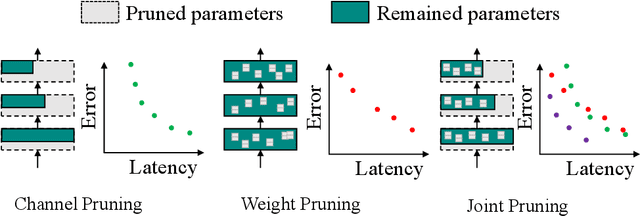
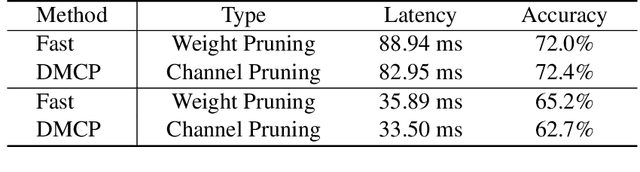
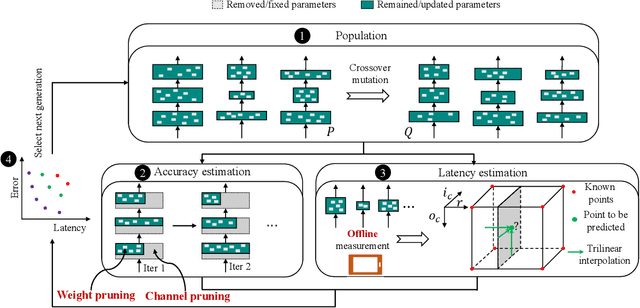
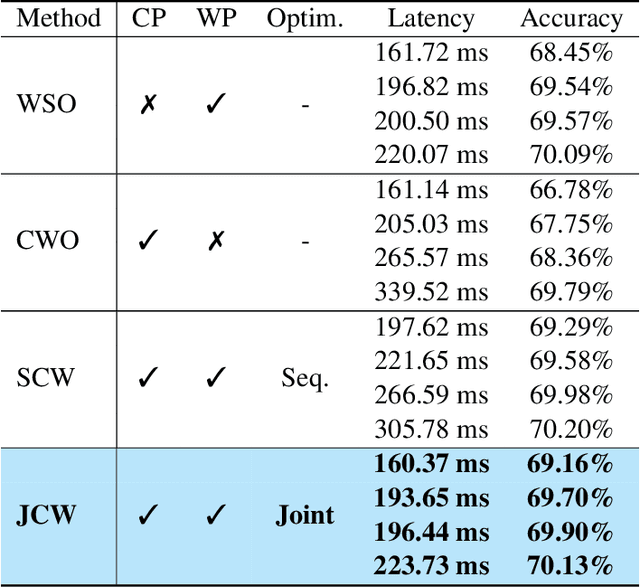
For practical deep neural network design on mobile devices, it is essential to consider the constraints incurred by the computational resources and the inference latency in various applications. Among deep network acceleration related approaches, pruning is a widely adopted practice to balance the computational resource consumption and the accuracy, where unimportant connections can be removed either channel-wisely or randomly with a minimal impact on model accuracy. The channel pruning instantly results in a significant latency reduction, while the random weight pruning is more flexible to balance the latency and accuracy. In this paper, we present a unified framework with Joint Channel pruning and Weight pruning (JCW), and achieves a better Pareto-frontier between the latency and accuracy than previous model compression approaches. To fully optimize the trade-off between the latency and accuracy, we develop a tailored multi-objective evolutionary algorithm in the JCW framework, which enables one single search to obtain the optimal candidate architectures for various deployment requirements. Extensive experiments demonstrate that the JCW achieves a better trade-off between the latency and accuracy against various state-of-the-art pruning methods on the ImageNet classification dataset. Our codes are available at https://github.com/jcw-anonymous/JCW.