 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLADE: Scalable Bi-level Adaptive Data Selection for LLM Training
Jun 17, 2026As Large Language Model (LLM) datasets scale to trillions of tokens, data selection has emerged as a critical frontier to filter out uninformative noise and construct adaptive learning trajectories. Beyond static heuristic filtering, advanced data selection methods for LLM training largely follow two paradigms, each with fundamental limitations. Influence-based methods provide principled bi-level objectives but require intractable inverse-Hessian computations, while excess-loss methods are computationally efficient but rely on a static reference model that becomes misaligned with the evolving proxy model during training. We propose BLADE (Bi-Level Adaptive Data sElection), a Hessian-free framework for data selection. BLADE reformulates the bi-level optimization problem underlying influence-based methods as a penalized single-level objective via Lagrange multipliers, avoiding inverse-Hessian computation while revealing a principled connection to excess-loss based data selection. The resulting objective recovers an excess-loss form but replaces the static reference model with a dynamic one that stays synchronized with training. Theoretically, we prove that this penalized formulation guarantees first-order convergence. For efficient online batch selection, we instantiate BLADE as a memoryless randomized block-coordinate Frank-Wolfe algorithm. Extensive experiments show that BLADE consistently outperforms state-of-the-art data selection baselines, providing a practical recipe for LLM training.
The Hidden Power of Scaling Factor in LoRA Optimization
Jun 11, 2026In Low-Rank Adaptation (LoRA), the scaling factor $α$ is often treated as a mere complement to the learning rate, yet its role in optimization remains poorly understood. In this paper, we reveal that the scaling factor $α$ and the learning rate function differently, with $α$ emerging as the dominant driver of effective optimization, delivering gains that cannot be replicated by learning rate scaling alone. Through the synergy of extensive empirical analysis and a theoretical Signal-Drift framework, we uncover three findings into LoRA's scaling mechanism: First, LoRA's spectral suppression smooths the optimization landscape, rendering standard hyperparameters overly conservative and creating an optimization gap. Second, when leveraging this smoothness to accelerate convergence, $α$ outperforms the learning rate by amplifying the task signal without increasing the drift ratio. Third, the optimal scaling factor follows a sublinear relationship with the rank, well characterized by a square-root law with an unexpectedly large coefficient, revealing the insufficient scaling of existing rank-tied heuristics. Based on these insights, we propose LoRA-$α$, a minimalist framework that restores $α$ to its principled regime, making LoRA compatible with standard small learning rates. Extensive evaluations across diverse tasks demonstrate that LoRA-$α$ consistently improves performance while streamlining hyperparameter search, unleashing the learning potential of LoRA.
Spectral Disentanglement and Enhancement: A Dual-domain Contrastive Framework for Representation Learning
Feb 09, 2026Large-scale multimodal contrastive learning has recently achieved impressive success in learning rich and transferable representations, yet it remains fundamentally limited by the uniform treatment of feature dimensions and the neglect of the intrinsic spectral structure of the learned features. Empirical evidence indicates that high-dimensional embeddings tend to collapse into narrow cones, concentrating task-relevant semantics in a small subspace, while the majority of dimensions remain occupied by noise and spurious correlations. Such spectral imbalance and entanglement undermine model generalization. We propose Spectral Disentanglement and Enhancement (SDE), a novel framework that bridges the gap between the geometry of the embedded spaces and their spectral properties. Our approach leverages singular value decomposition to adaptively partition feature dimensions into strong signals that capture task-critical semantics, weak signals that reflect ancillary correlations, and noise representing irrelevant perturbations. A curriculum-based spectral enhancement strategy is then applied, selectively amplifying informative components with theoretical guarantees on training stability. Building upon the enhanced features, we further introduce a dual-domain contrastive loss that jointly optimizes alignment in both the feature and spectral spaces, effectively integrating spectral regularization into the training process and encouraging richer, more robust representations. Extensive experiments on large-scale multimodal benchmarks demonstrate that SDE consistently improves representation robustness and generalization, outperforming state-of-the-art methods. SDE integrates seamlessly with existing contrastive pipelines, offering an effective solution for multimodal representation learning.
The Primacy of Magnitude in Low-Rank Adaptation
Jul 09, 2025Low-Rank Adaptation (LoRA) offers a parameter-efficient paradigm for tuning large models. While recent spectral initialization methods improve convergence and performance over the naive "Noise & Zeros" scheme, their extra computational and storage overhead undermines efficiency. In this paper, we establish update magnitude as the fundamental driver of LoRA performance and propose LoRAM, a magnitude-driven "Basis & Basis" initialization scheme that matches spectral methods without their inefficiencies. Our key contributions are threefold: (i) Magnitude of weight updates determines convergence. We prove low-rank structures intrinsically bound update magnitudes, unifying hyperparameter tuning in learning rate, scaling factor, and initialization as mechanisms to optimize magnitude regulation. (ii) Spectral initialization succeeds via magnitude amplification. We demystify that the presumed knowledge-driven benefit of the spectral component essentially arises from the boost in the weight update magnitude. (iii) A novel and compact initialization strategy, LoRAM, scales deterministic orthogonal bases using pretrained weight magnitudes to simulate spectral gains. Extensive experiments show that LoRAM serves as a strong baseline, retaining the full efficiency of LoRA while matching or outperforming spectral initialization across benchmarks.
Infer Implicit Contexts in Real-time Online-to-Offline Recommendation
Jul 08, 2019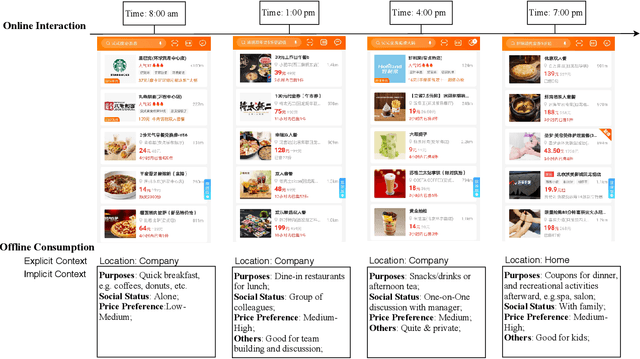
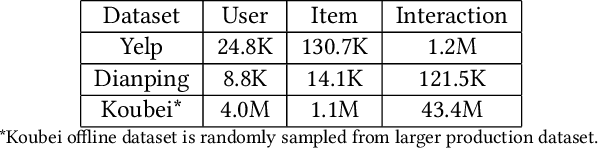
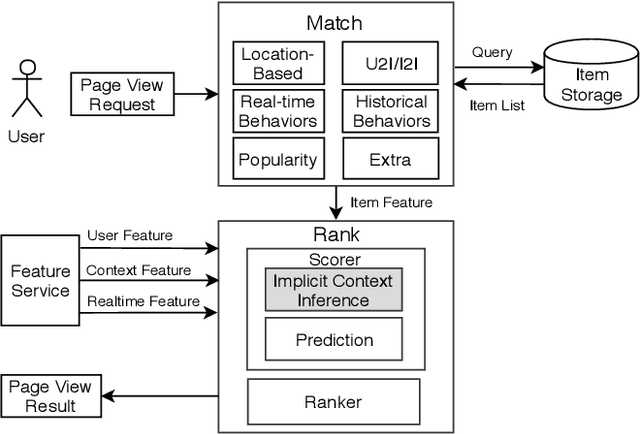
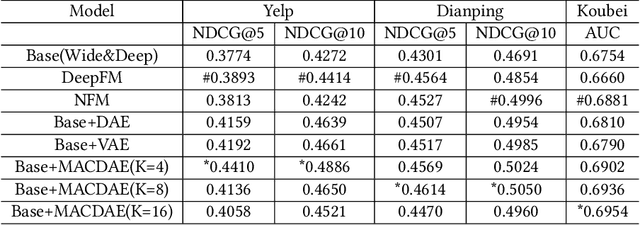
Understanding users' context is essential for successful recommendations, especially for Online-to-Offline (O2O) recommendation, such as Yelp, Groupon, and Koubei. Different from traditional recommendation where individual preference is mostly static, O2O recommendation should be dynamic to capture variation of users' purposes across time and location. However, precisely inferring users' real-time contexts information, especially those implicit ones, is extremely difficult, and it is a central challenge for O2O recommendation. In this paper, we propose a new approach, called Mixture Attentional Constrained Denoise AutoEncoder (MACDAE), to infer implicit contexts and consequently, to improve the quality of real-time O2O recommendation. In MACDAE, we first leverage the interaction among users, items, and explicit contexts to infer users' implicit contexts, then combine the learned implicit-context representation into an end-to-end model to make the recommendation. MACDAE works quite well in the real system. We conducted both offline and online evaluations of the proposed approach. Experiments on several real-world datasets (Yelp, Dianping, and Koubei) show our approach could achieve significant improvements over state-of-the-arts. Furthermore, online A/B test suggests a 2.9% increase for click-through rate and 5.6% improvement for conversion rate in real-world traffic. Our model has been deployed in the product of "Guess You Like" recommendation in Koubei.