 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-Consistent Knowledge Graph Representation Learning for Multi-Modal Entity Alignment
Apr 04, 2023The multi-modal entity alignment (MMEA) aims to find all equivalent entity pairs between multi-modal knowledge graphs (MMKGs). Rich attributes and neighboring entities are valuable for the alignment task, but existing works ignore contextual gap problems that the aligned entities have different numbers of attributes on specific modality when learning entity representations. In this paper, we propose a novel attribute-consistent knowledge graph representation learning framework for MMEA (ACK-MMEA) to compensate the contextual gaps through incorporating consistent alignment knowledge. Attribute-consistent KGs (ACKGs) are first constructed via multi-modal attribute uniformization with merge and generate operators so that each entity has one and only one uniform feature in each modality. The ACKGs are then fed into a relation-aware graph neural network with random dropouts, to obtain aggregated relation representations and robust entity representations. In order to evaluate the ACK-MMEA facilitated for entity alignment, we specially design a joint alignment loss for both entity and attribute evaluation. Extensive experiments conducted on two benchmark datasets show that our approach achieves excellent performance compared to its competitors.
SE-GSL: A General and Effective Graph Structure Learning Framework through Structural Entropy Optimization
Mar 17, 2023



Graph Neural Networks (GNNs) are de facto solutions to structural data learning. However, it is susceptible to low-quality and unreliable structure, which has been a norm rather than an exception in real-world graphs. Existing graph structure learning (GSL) frameworks still lack robustness and interpretability. This paper proposes a general GSL framework, SE-GSL, through structural entropy and the graph hierarchy abstracted in the encoding tree. Particularly, we exploit the one-dimensional structural entropy to maximize embedded information content when auxiliary neighbourhood attributes are fused to enhance the original graph. A new scheme of constructing optimal encoding trees is proposed to minimize the uncertainty and noises in the graph whilst assuring proper community partition in hierarchical abstraction. We present a novel sample-based mechanism for restoring the graph structure via node structural entropy distribution. It increases the connectivity among nodes with larger uncertainty in lower-level communities. SE-GSL is compatible with various GNN models and enhances the robustness towards noisy and heterophily structures. Extensive experiments show significant improvements in the effectiveness and robustness of structure learning and node representation learning.
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
Feb 18, 2023The Pretrained Foundation Models (PFMs) are regarded as the foundation for various downstream tasks with different data modalities. A pretrained foundation model, such as BERT, GPT-3, MAE, DALLE-E, and ChatGPT, is trained on large-scale data which provides a reasonable parameter initialization for a wide range of downstream applications. The idea of pretraining behind PFMs plays an important role in the application of large models. Different from previous methods that apply convolution and recurrent modules for feature extractions, the generative pre-training (GPT) method applies Transformer as the feature extractor and is trained on large datasets with an autoregressive paradigm. Similarly, the BERT apples transformers to train on large datasets as a contextual language model. Recently, the ChatGPT shows promising success on large language models, which applies an autoregressive language model with zero shot or few show prompting. With the extraordinary success of PFMs, AI has made waves in a variety of fields over the past few years. Considerable methods, datasets, and evaluation metrics have been proposed in the literature, the need is raising for an updated survey. This study provides a comprehensive review of recent research advancements, current and future challenges, and opportunities for PFMs in text, image, graph, as well as other data modalities. We first review the basic components and existing pretraining in natural language processing, computer vision, and graph learning. We then discuss other advanced PFMs for other data modalities and unified PFMs considering the data quality and quantity. Besides, we discuss relevant research about the fundamentals of the PFM, including model efficiency and compression, security, and privacy. Finally, we lay out key implications, future research directions, challenges, and open problems.
Unbiased and Efficient Self-Supervised Incremental Contrastive Learning
Jan 28, 2023Contrastive Learning (CL) has been proved to be a powerful self-supervised approach for a wide range of domains, including computer vision and graph representation learning. However, the incremental learning issue of CL has rarely been studied, which brings the limitation in applying it to real-world applications. Contrastive learning identifies the samples with the negative ones from the noise distribution that changes in the incremental scenarios. Therefore, only fitting the change of data without noise distribution causes bias, and directly retraining results in low efficiency. To bridge this research gap, we propose a self-supervised Incremental Contrastive Learning (ICL) framework consisting of (i) a novel Incremental InfoNCE (NCE-II) loss function by estimating the change of noise distribution for old data to guarantee no bias with respect to the retraining, (ii) a meta-optimization with deep reinforced Learning Rate Learning (LRL) mechanism which can adaptively learn the learning rate according to the status of the training processes and achieve fast convergence which is critical for incremental learning. Theoretically, the proposed ICL is equivalent to retraining, which is based on solid mathematical derivation. In practice, extensive experiments in different domains demonstrate that, without retraining a new model, ICL achieves up to 16.7x training speedup and 16.8x faster convergence with competitive results.
Self-organization Preserved Graph Structure Learning with Principle of Relevant Information
Dec 30, 2022



Most Graph Neural Networks follow the message-passing paradigm, assuming the observed structure depicts the ground-truth node relationships. However, this fundamental assumption cannot always be satisfied, as real-world graphs are always incomplete, noisy, or redundant. How to reveal the inherent graph structure in a unified way remains under-explored. We proposed PRI-GSL, a Graph Structure Learning framework guided by the Principle of Relevant Information, providing a simple and unified framework for identifying the self-organization and revealing the hidden structure. PRI-GSL learns a structure that contains the most relevant yet least redundant information quantified by von Neumann entropy and Quantum Jensen-Shannon divergence. PRI-GSL incorporates the evolution of quantum continuous walk with graph wavelets to encode node structural roles, showing in which way the nodes interplay and self-organize with the graph structure. Extensive experiments demonstrate the superior effectiveness and robustness of PRI-GSL.
Type Information Utilized Event Detection via Multi-Channel GNNs in Electrical Power Systems
Nov 15, 2022Event detection in power systems aims to identify triggers and event types, which helps relevant personnel respond to emergencies promptly and facilitates the optimization of power supply strategies. However, the limited length of short electrical record texts causes severe information sparsity, and numerous domain-specific terminologies of power systems makes it difficult to transfer knowledge from language models pre-trained on general-domain texts. Traditional event detection approaches primarily focus on the general domain and ignore these two problems in the power system domain. To address the above issues, we propose a Multi-Channel graph neural network utilizing Type information for Event Detection in power systems, named MC-TED, leveraging a semantic channel and a topological channel to enrich information interaction from short texts. Concretely, the semantic channel refines textual representations with semantic similarity, building the semantic information interaction among potential event-related words. The topological channel generates a relation-type-aware graph modeling word dependencies, and a word-type-aware graph integrating part-of-speech tags. To further reduce errors worsened by professional terminologies in type analysis, a type learning mechanism is designed for updating the representations of both the word type and relation type in the topological channel. In this way, the information sparsity and professional term occurrence problems can be alleviated by enabling interaction between topological and semantic information. Furthermore, to address the lack of labeled data in power systems, we built a Chinese event detection dataset based on electrical Power Event texts, named PoE. In experiments, our model achieves compelling results not only on the PoE dataset, but on general-domain event detection datasets including ACE 2005 and MAVEN.
Position-aware Structure Learning for Graph Topology-imbalance by Relieving Under-reaching and Over-squashing
Aug 17, 2022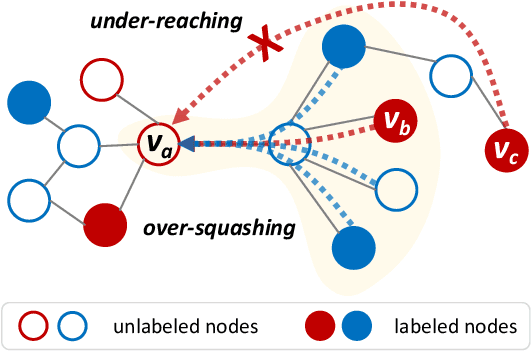
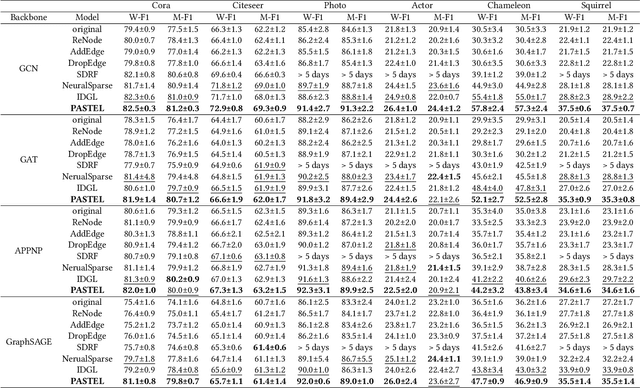
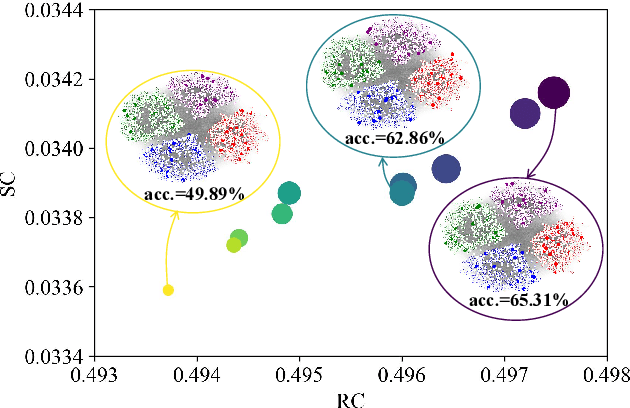
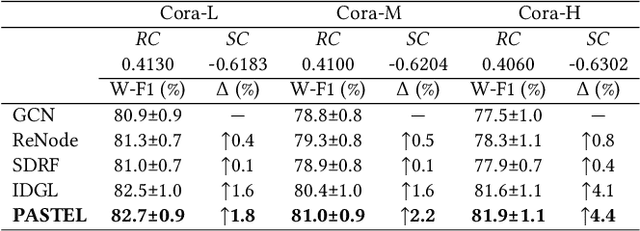
Topology-imbalance is a graph-specific imbalance problem caused by the uneven topology positions of labeled nodes, which significantly damages the performance of GNNs. What topology-imbalance means and how to measure its impact on graph learning remain under-explored. In this paper, we provide a new understanding of topology-imbalance from a global view of the supervision information distribution in terms of under-reaching and over-squashing, which motivates two quantitative metrics as measurements. In light of our analysis, we propose a novel position-aware graph structure learning framework named PASTEL, which directly optimizes the information propagation path and solves the topology-imbalance issue in essence. Our key insight is to enhance the connectivity of nodes within the same class for more supervision information, thereby relieving the under-reaching and over-squashing phenomena. Specifically, we design an anchor-based position encoding mechanism, which better incorporates relative topology position and enhances the intra-class inductive bias by maximizing the label influence. We further propose a class-wise conflict measure as the edge weights, which benefits the separation of different node classes. Extensive experiments demonstrate the superior potential and adaptability of PASTEL in enhancing GNNs' power in different data annotation scenarios.
Task-Specific Expert Pruning for Sparse Mixture-of-Experts
Jun 02, 2022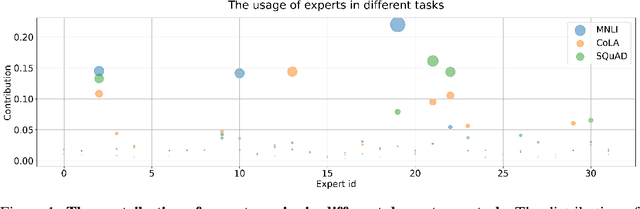
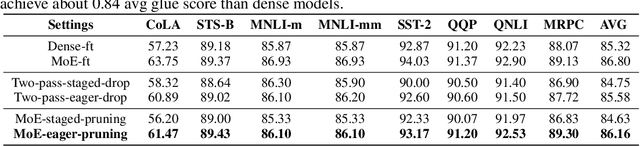
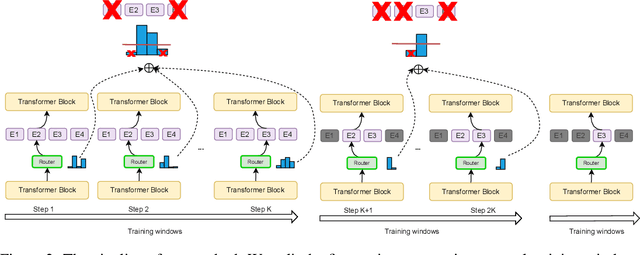
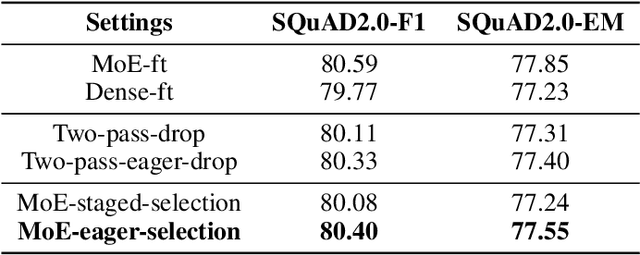
The sparse Mixture-of-Experts (MoE) model is powerful for large-scale pre-training and has achieved promising results due to its model capacity. However, with trillions of parameters, MoE is hard to be deployed on cloud or mobile environment. The inference of MoE requires expert parallelism, which is not hardware-friendly and communication expensive. Especially for resource-limited downstream tasks, such sparse structure has to sacrifice a lot of computing efficiency for limited performance gains. In this work, we observe most experts contribute scarcely little to the MoE fine-tuning and inference. We further propose a general method to progressively drop the non-professional experts for the target downstream task, which preserves the benefits of MoE while reducing the MoE model into one single-expert dense model. Our experiments reveal that the fine-tuned single-expert model could preserve 99.3% benefits from MoE across six different types of tasks while enjoying 2x inference speed with free communication cost.
THE-X: Privacy-Preserving Transformer Inference with Homomorphic Encryption
Jun 02, 2022As more and more pre-trained language models adopt on-cloud deployment, the privacy issues grow quickly, mainly for the exposure of plain-text user data (e.g., search history, medical record, bank account). Privacy-preserving inference of transformer models is on the demand of cloud service users. To protect privacy, it is an attractive choice to compute only with ciphertext in homomorphic encryption (HE). However, enabling pre-trained models inference on ciphertext data is difficult due to the complex computations in transformer blocks, which are not supported by current HE tools yet. In this work, we introduce $\textit{THE-X}$, an approximation approach for transformers, which enables privacy-preserving inference of pre-trained models developed by popular frameworks. $\textit{THE-X}$ proposes a workflow to deal with complex computation in transformer networks, including all the non-polynomial functions like GELU, softmax, and LayerNorm. Experiments reveal our proposed $\textit{THE-X}$ can enable transformer inference on encrypted data for different downstream tasks, all with negligible performance drop but enjoying the theory-guaranteed privacy-preserving advantage.
Cross-Domain Object Detection with Mean-Teacher Transformer
May 03, 2022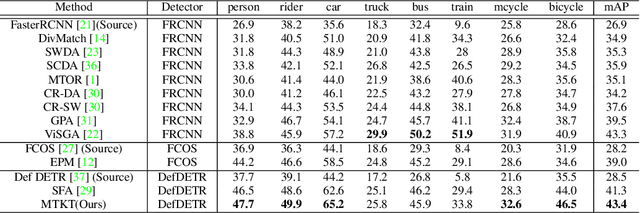
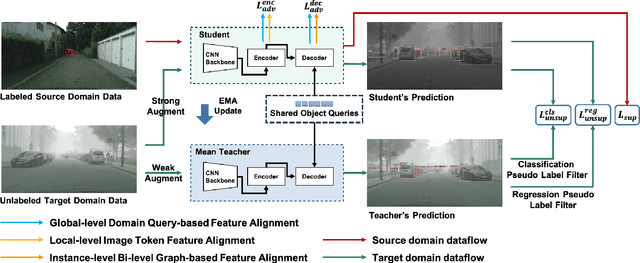
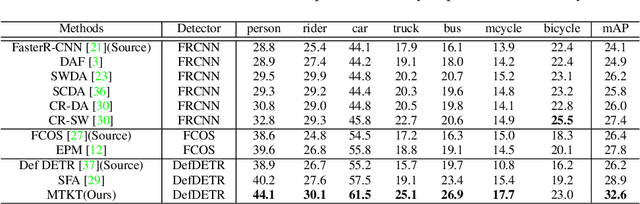
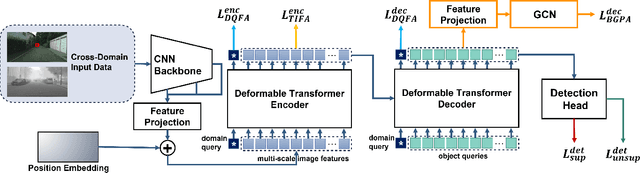
Recently, DEtection TRansformer (DETR), an end-to-end object detection pipeline, has achieved promising performance. However, it requires large-scale labeled data and suffers from domain shift, especially when no labeled data is available in the target domain. To solve this problem, we propose an end-to-end cross-domain detection transformer based on the mean teacher knowledge transfer (MTKT), which transfers knowledge between domains via pseudo labels. To improve the quality of pseudo labels in the target domain, which is a crucial factor for better domain adaptation, we design three levels of source-target feature alignment strategies based on the architecture of the Transformer, including domain query-based feature alignment (DQFA), bi-level-graph-based prototype alignment (BGPA), and token-wise image feature alignment (TIFA). These three levels of feature alignment match the global, local, and instance features between source and target, respectively. With these strategies, more accurate pseudo labels can be obtained, and knowledge can be better transferred from source to target, thus improving the cross-domain capability of the detection transformer. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on three domain adaptation scenarios, especially the result of Sim10k to Cityscapes scenario is remarkably improved from 52.6 mAP to 57.9 mAP. Code will be released.