 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased and Efficient Self-Supervised Incremental Contrastive Learning
Jan 28, 2023Contrastive Learning (CL) has been proved to be a powerful self-supervised approach for a wide range of domains, including computer vision and graph representation learning. However, the incremental learning issue of CL has rarely been studied, which brings the limitation in applying it to real-world applications. Contrastive learning identifies the samples with the negative ones from the noise distribution that changes in the incremental scenarios. Therefore, only fitting the change of data without noise distribution causes bias, and directly retraining results in low efficiency. To bridge this research gap, we propose a self-supervised Incremental Contrastive Learning (ICL) framework consisting of (i) a novel Incremental InfoNCE (NCE-II) loss function by estimating the change of noise distribution for old data to guarantee no bias with respect to the retraining, (ii) a meta-optimization with deep reinforced Learning Rate Learning (LRL) mechanism which can adaptively learn the learning rate according to the status of the training processes and achieve fast convergence which is critical for incremental learning. Theoretically, the proposed ICL is equivalent to retraining, which is based on solid mathematical derivation. In practice, extensive experiments in different domains demonstrate that, without retraining a new model, ICL achieves up to 16.7x training speedup and 16.8x faster convergence with competitive results.
SUGAR: Subgraph Neural Network with Reinforcement Pooling and Self-Supervised Mutual Information Mechanism
Jan 20, 2021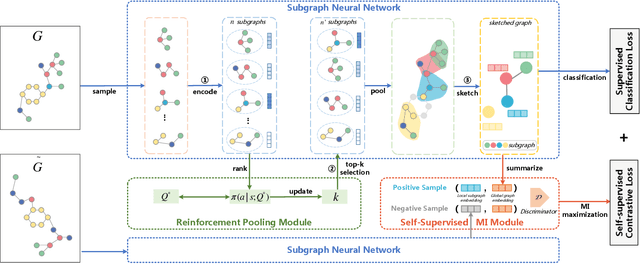
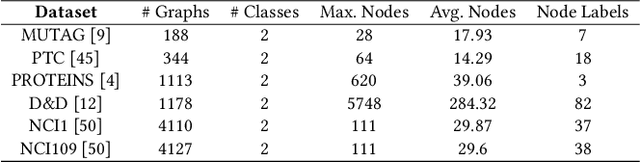
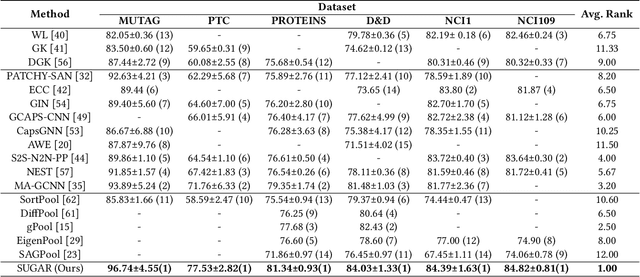
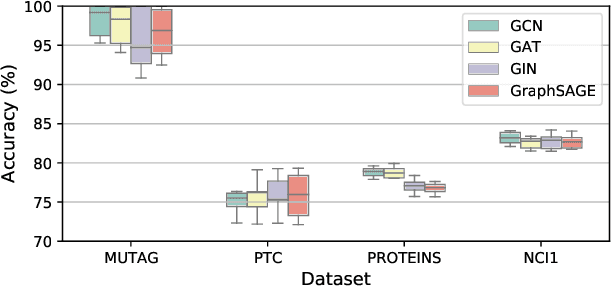
Graph representation learning has attracted increasing research attention. However, most existing studies fuse all structural features and node attributes to provide an overarching view of graphs, neglecting finer substructures' semantics, and suffering from interpretation enigmas. This paper presents a novel hierarchical subgraph-level selection and embedding based graph neural network for graph classification, namely SUGAR, to learn more discriminative subgraph representations and respond in an explanatory way. SUGAR reconstructs a sketched graph by extracting striking subgraphs as the representative part of the original graph to reveal subgraph-level patterns. To adaptively select striking subgraphs without prior knowledge, we develop a reinforcement pooling mechanism, which improves the generalization ability of the model. To differentiate subgraph representations among graphs, we present a self-supervised mutual information mechanism to encourage subgraph embedding to be mindful of the global graph structural properties by maximizing their mutual information. Extensive experiments on six typical bioinformatics datasets demonstrate a significant and consistent improvement in model quality with competitive performance and interpretability.
Real-World Multi-Domain Data Applications for Generalizations to Clinical Settings
Jul 24, 2020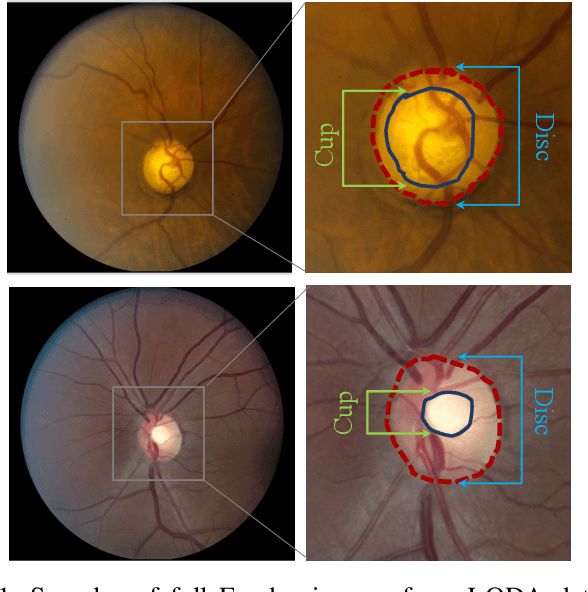
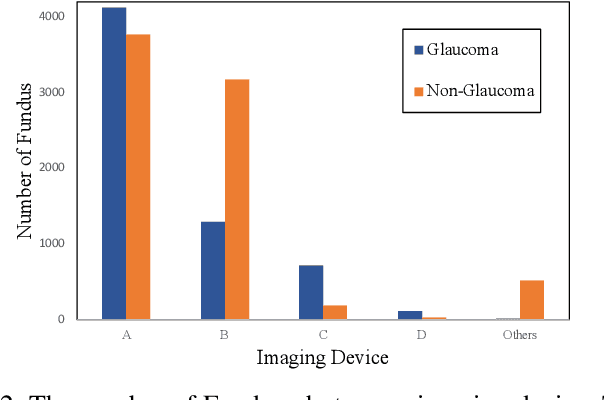
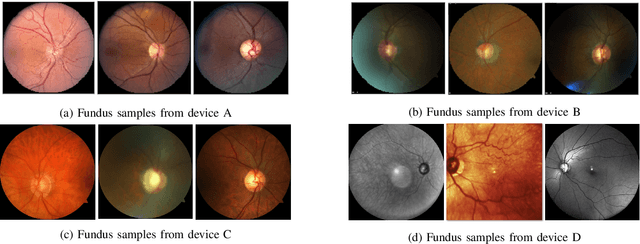
With promising results of machine learning based models in computer vision, applications on medical imaging data have been increasing exponentially. However, generalizations to complex real-world clinical data is a persistent problem. Deep learning models perform well when trained on standardized datasets from artificial settings, such as clinical trials. However, real-world data is different and translations are yielding varying results. The complexity of real-world applications in healthcare could emanate from a mixture of different data distributions across multiple device domains alongside the inevitable noise sourced from varying image resolutions, human errors, and the lack of manual gradings. In addition, healthcare applications not only suffer from the scarcity of labeled data, but also face limited access to unlabeled data due to HIPAA regulations, patient privacy, ambiguity in data ownership, and challenges in collecting data from different sources. These limitations pose additional challenges to applying deep learning algorithms in healthcare and clinical translations. In this paper, we utilize self-supervised representation learning methods, formulated effectively in transfer learning settings, to address limited data availability. Our experiments verify the importance of diverse real-world data for generalization to clinical settings. We show that by employing a self-supervised approach with transfer learning on a multi-domain real-world dataset, we can achieve 16% relative improvement on a standardized dataset over supervised baselines.
An Introduction to Image Synthesis with Generative Adversarial Nets
Mar 12, 2018There has been a drastic growth of research in Generative Adversarial Nets (GANs) in the past few years. Proposed in 2014, GAN has been applied to various applications such as computer vision and natural language processing, and achieves impressive performance. Among the many applications of GAN, image synthesis is the most well-studied one, and research in this area has already demonstrated the great potential of using GAN in image synthesis. In this paper, we provide a taxonomy of methods used in image synthesis, review different models for text-to-image synthesis and image-to-image translation, and discuss some evaluation metrics as well as possible future research directions in image synthesis with GAN.