 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Interaction Learning for Video-based Person Re-identification
Mar 18, 2021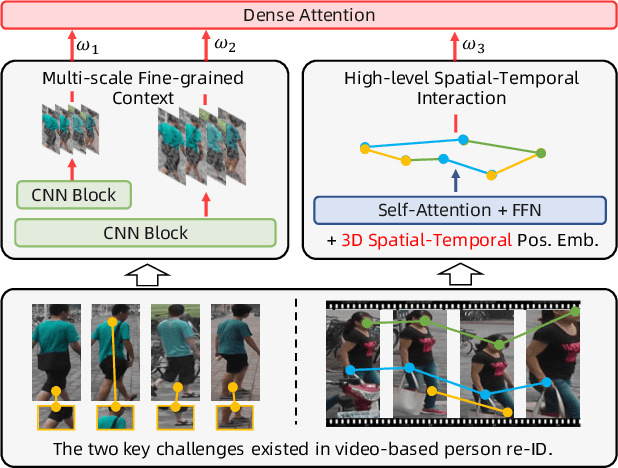
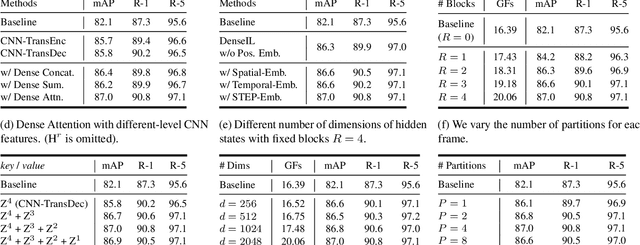
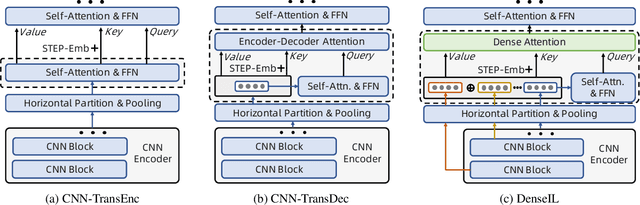
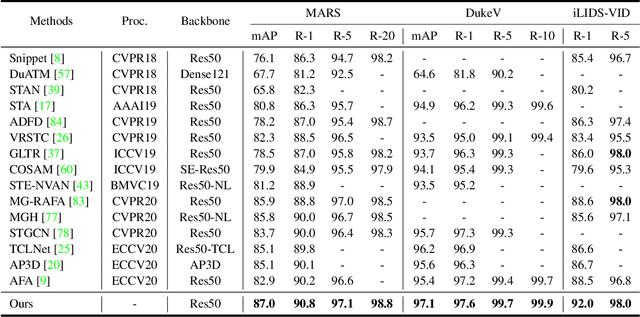
Video-based person re-identification (re-ID) aims at matching the same person across video clips. Efficiently exploiting multi-scale fine-grained features while building the structural interaction among them is pivotal for its success. In this paper, we propose a hybrid framework, Dense Interaction Learning (DenseIL), that takes the principal advantages of both CNN-based and Attention-based architectures to tackle video-based person re-ID difficulties. DenseIL contains a CNN encoder and a Dense Interaction (DI) decoder. The CNN encoder is responsible for efficiently extracting discriminative spatial features while the DI decoder is designed to densely model spatial-temporal inherent interaction across frames. Different from previous works, we additionally let the DI decoder densely attends to intermediate fine-grained CNN features and that naturally yields multi-grained spatial-temporal representation for each video clip. Moreover, we introduce Spatio-TEmporal Positional Embedding (STEP-Emb) into the DI decoder to investigate the positional relation among the spatial-temporal inputs. Our experiments consistently and significantly outperform all the state-of-the-art methods on multiple standard video-based re-ID datasets.
Camera-aware Proxies for Unsupervised Person Re-Identification
Dec 19, 2020

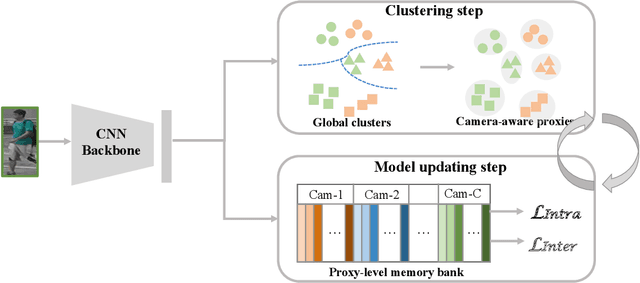

This paper tackles the purely unsupervised person re-identification (Re-ID) problem that requires no annotations. Some previous methods adopt clustering techniques to generate pseudo labels and use the produced labels to train Re-ID models progressively. These methods are relatively simple but effective. However, most clustering-based methods take each cluster as a pseudo identity class, neglecting the large intra-ID variance caused mainly by the change of camera views. To address this issue, we propose to split each single cluster into multiple proxies and each proxy represents the instances coming from the same camera. These camera-aware proxies enable us to deal with large intra-ID variance and generate more reliable pseudo labels for learning. Based on the camera-aware proxies, we design both intra- and inter-camera contrastive learning components for our Re-ID model to effectively learn the ID discrimination ability within and across cameras. Meanwhile, a proxy-balanced sampling strategy is also designed, which facilitates our learning further. Extensive experiments on three large-scale Re-ID datasets show that our proposed approach outperforms most unsupervised methods by a significant margin. Especially, on the challenging MSMT17 dataset, we gain $14.3\%$ Rank-1 and $10.2\%$ mAP improvements when compared to the second place.
Learning to Generate Content-Aware Dynamic Detectors
Dec 08, 2020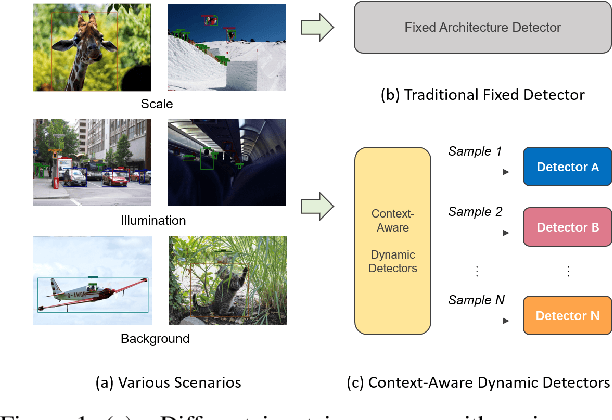
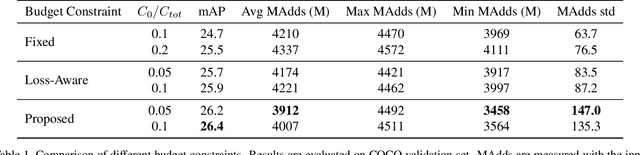
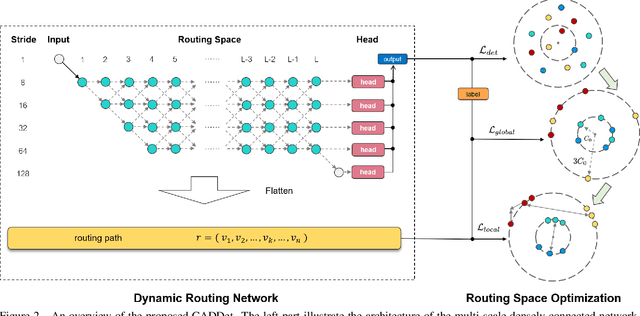
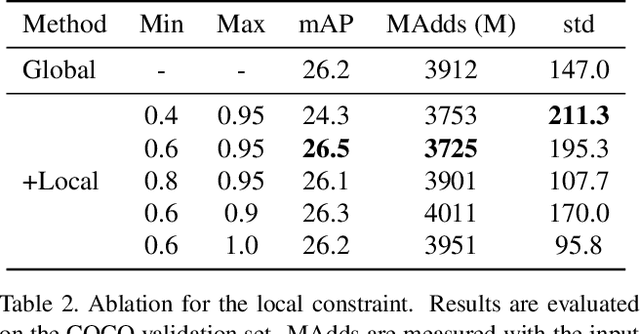
Model efficiency is crucial for object detection. Mostprevious works rely on either hand-crafted design or auto-search methods to obtain a static architecture, regardless ofthe difference of inputs. In this paper, we introduce a newperspective of designing efficient detectors, which is automatically generating sample-adaptive model architectureon the fly. The proposed method is named content-aware dynamic detectors (CADDet). It first applies a multi-scale densely connected network with dynamic routing as the supernet. Furthermore, we introduce a course-to-fine strat-egy tailored for object detection to guide the learning of dynamic routing, which contains two metrics: 1) dynamic global budget constraint assigns data-dependent expectedbudgets for individual samples; 2) local path similarity regularization aims to generate more diverse routing paths. With these, our method achieves higher computational efficiency while maintaining good performance. To the best of our knowledge, our CADDet is the first work to introduce dynamic routing mechanism in object detection. Experiments on MS-COCO dataset demonstrate that CADDet achieves 1.8 higher mAP with 10% fewer FLOPs compared with vanilla routing strategy. Compared with the models based upon similar building blocks, CADDet achieves a 42% FLOPs reduction with a competitive mAP.
Spatio-Temporal Inception Graph Convolutional Networks for Skeleton-Based Action Recognition
Nov 26, 2020
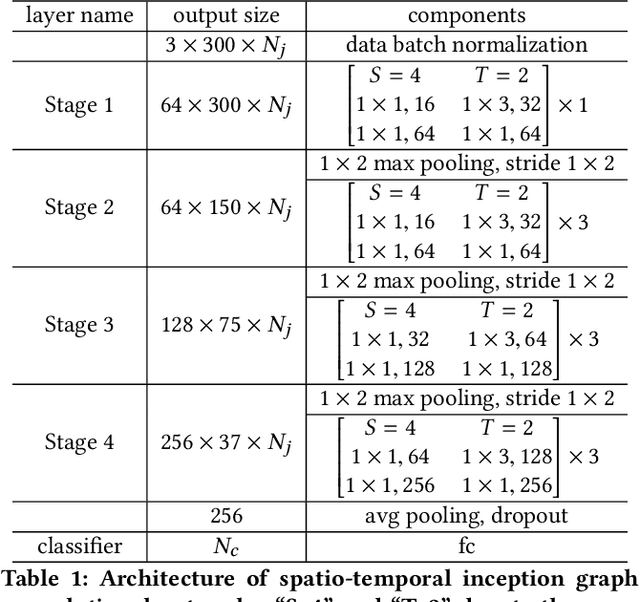

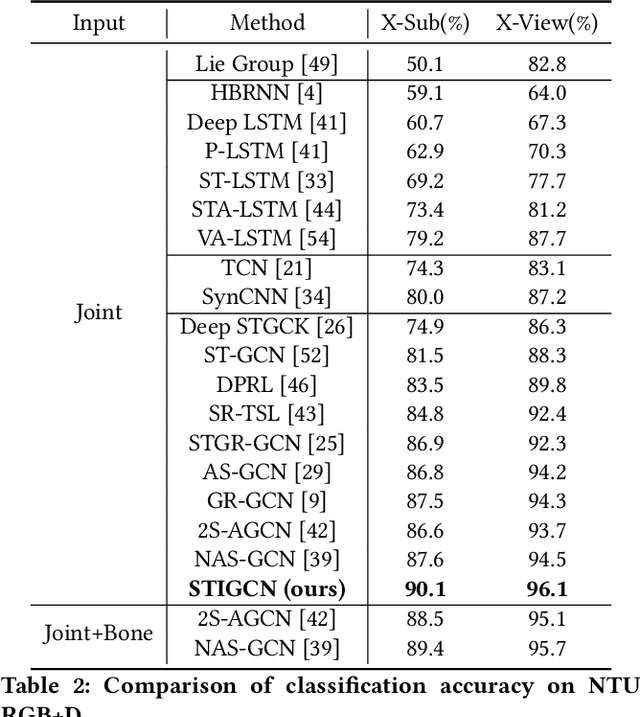
Skeleton-based human action recognition has attracted much attention with the prevalence of accessible depth sensors. Recently, graph convolutional networks (GCNs) have been widely used for this task due to their powerful capability to model graph data. The topology of the adjacency graph is a key factor for modeling the correlations of the input skeletons. Thus, previous methods mainly focus on the design/learning of the graph topology. But once the topology is learned, only a single-scale feature and one transformation exist in each layer of the networks. Many insights, such as multi-scale information and multiple sets of transformations, that have been proven to be very effective in convolutional neural networks (CNNs), have not been investigated in GCNs. The reason is that, due to the gap between graph-structured skeleton data and conventional image/video data, it is very challenging to embed these insights into GCNs. To overcome this gap, we reinvent the split-transform-merge strategy in GCNs for skeleton sequence processing. Specifically, we design a simple and highly modularized graph convolutional network architecture for skeleton-based action recognition. Our network is constructed by repeating a building block that aggregates multi-granularity information from both the spatial and temporal paths. Extensive experiments demonstrate that our network outperforms state-of-the-art methods by a significant margin with only 1/5 of the parameters and 1/10 of the FLOPs.
DCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation
Nov 19, 2020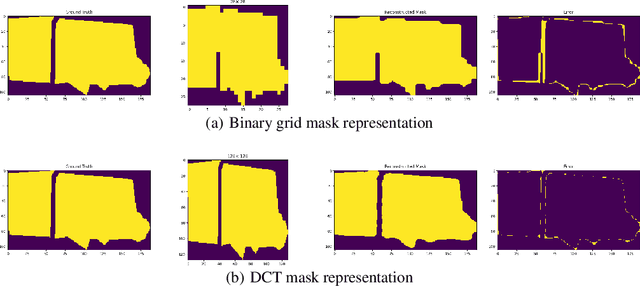
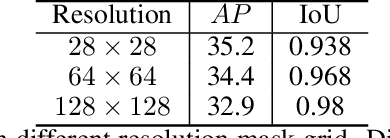
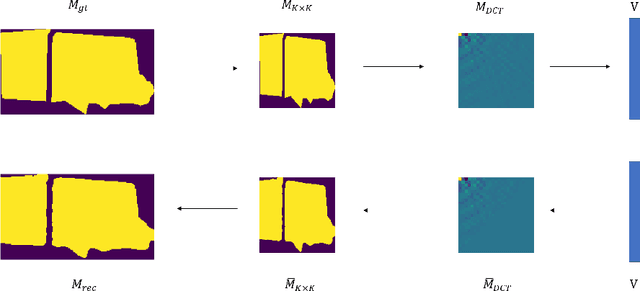
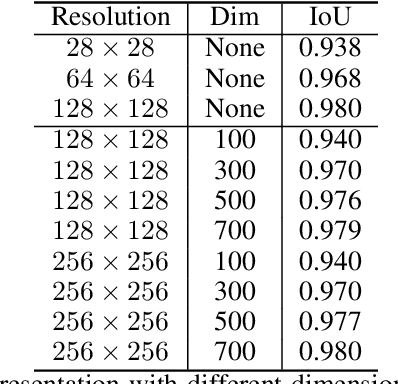
Binary grid mask representation is broadly used in instance segmentation. A representative instantiation is Mask R-CNN which predicts masks on a $28\times 28$ binary grid. Generally, a low-resolution grid is not sufficient to capture the details, while a high-resolution grid dramatically increases the training complexity. In this paper, we propose a new mask representation by applying the discrete cosine transform(DCT) to encode the high-resolution binary grid mask into a compact vector. Our method, termed DCT-Mask, could be easily integrated into most pixel-based instance segmentation methods. Without any bells and whistles, DCT-Mask yields significant gains on different frameworks, backbones, datasets, and training schedules. It does not require any pre-processing or pre-training, and almost no harm to the running speed. Especially, for higher-quality annotations and more complex backbones, our method has a greater improvement. Moreover, we analyze the performance of our method from the perspective of the quality of mask representation. The main reason why DCT-Mask works well is that it obtains a high-quality mask representation with low complexity. Code will be made available.
CIMON: Towards High-quality Hash Codes
Nov 05, 2020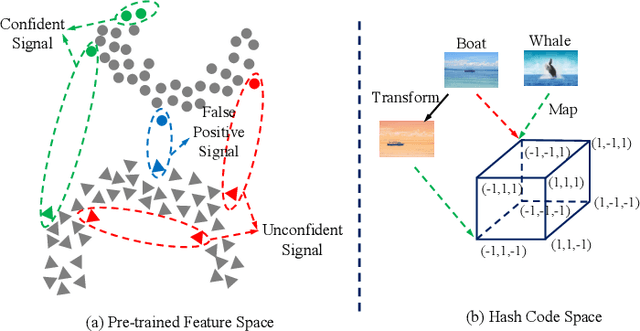
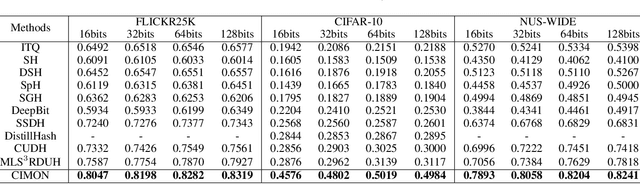
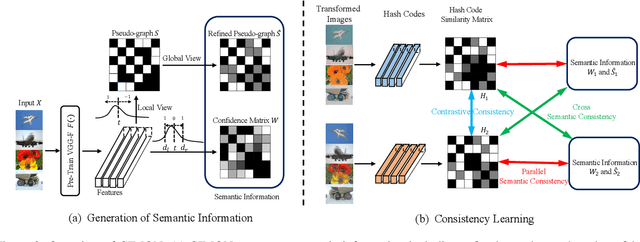
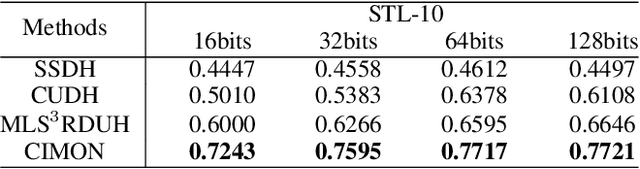
Recently, hashing is widely-used in approximate nearest neighbor search for its storage and computational efficiency. Due to the lack of labeled data in practice, many studies focus on unsupervised hashing. Most of the unsupervised hashing methods learn to map images into semantic similarity-preserving hash codes by constructing local semantic similarity structure from the pre-trained model as guiding information, i.e., treating each point pair similar if their distance is small in feature space. However, due to the inefficient representation ability of the pre-trained model, many false positives and negatives in local semantic similarity will be introduced and lead to error propagation during hash code learning. Moreover, most of hashing methods ignore the basic characteristics of hash codes such as collisions, which will cause instability of hash codes to disturbance. In this paper, we propose a new method named Comprehensive sImilarity Mining and cOnsistency learNing (CIMON). First, we use global constraint learning and similarity statistical distribution to obtain reliable and smooth guidance. Second, image augmentation and consistency learning will be introduced to explore both semantic and contrastive consistency to derive robust hash codes with fewer collisions. Extensive experiments on several benchmark datasets show that the proposed method consistently outperforms a wide range of state-of-the-art methods in both retrieval performance and robustness.
FGAGT: Flow-Guided Adaptive Graph Tracking
Nov 04, 2020
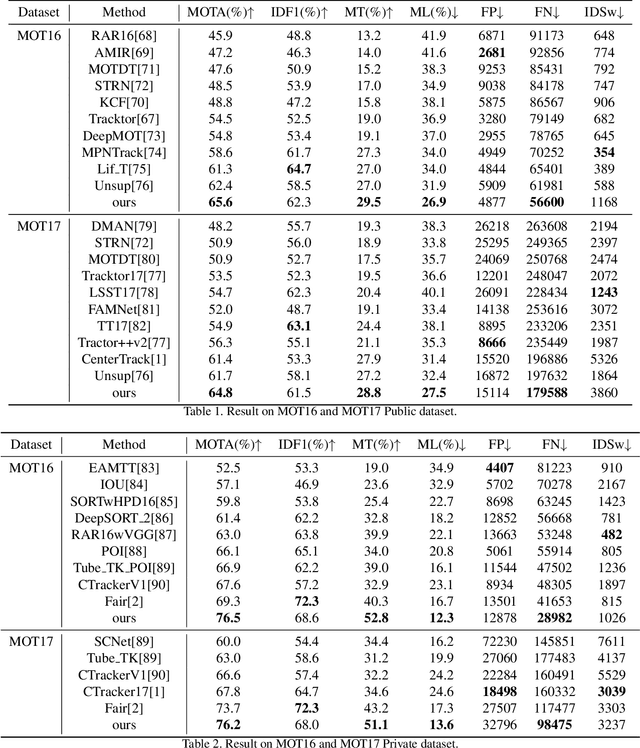
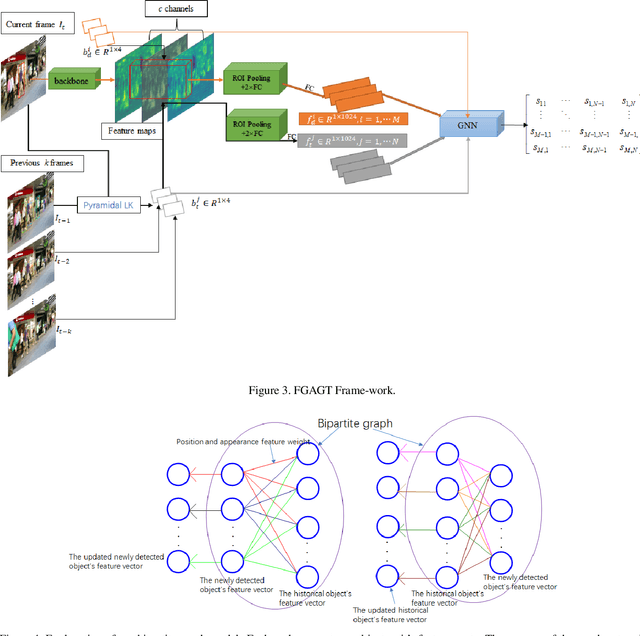
Most previous tracking methods usually use the optical flow method to estimate the position of the historical object in the current frame and then use the linear combination of feature similarity and IOU(Intersection over Union) to perform association matching near the position. However, the features used in these methods are not aligned, i.e., the features of the historical objects are extracted from the historical feature maps, not from the current frame, even the same object may undergo posture, angle, etc. changes during the movement, and even light intensity changes. In addition, most methods only use the appearance information when extracting the feature vector, not the position relationship, nor the feature information of the historical object, so the information is not fully utilized. In order to solve the above problems, we proposed the FGAGT tracker, which uses the optical flow method to predict the center position of the historical object in the current frame and extract the feature vector, so that the feature of the historical object can be aligned with the feature of the object in the current frame. Then these features are input into the graph neural network, and the global Spatio-temporal position and appearance information are integrated to update the feature vectors of all objects. In the training phase, we propose the Balanced MSE LOSS to balance the sample distribution for data association. Experiments show that our method reaches the level of state-of-the-art, where the MOTA index exceeds FairMOT by 2.5 points, and CenterTrack by 8.4 points on the MOT17 dataset, exceeds FairMOT by 1.6 points on the MOT16 dataset. Code will be avaliable.
Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect
Oct 03, 2020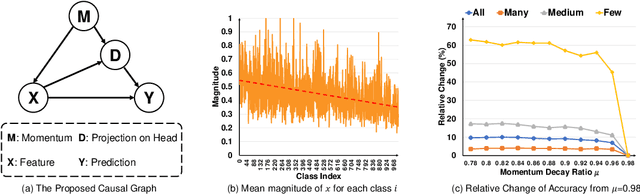

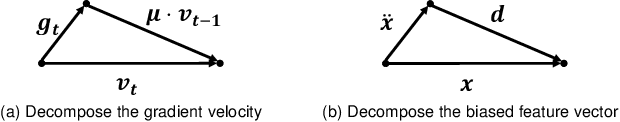
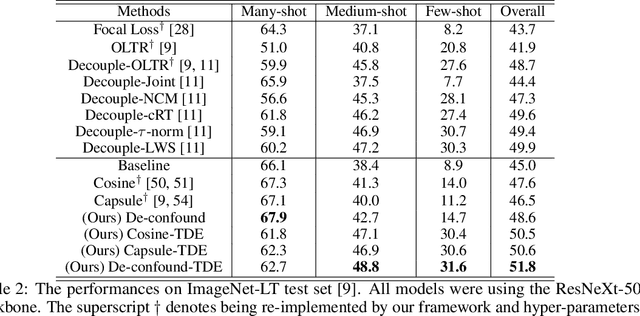
As the class size grows, maintaining a balanced dataset across many classes is challenging because the data are long-tailed in nature; it is even impossible when the sample-of-interest co-exists with each other in one collectable unit, e.g., multiple visual instances in one image. Therefore, long-tailed classification is the key to deep learning at scale. However, existing methods are mainly based on re-weighting/re-sampling heuristics that lack a fundamental theory. In this paper, we establish a causal inference framework, which not only unravels the whys of previous methods, but also derives a new principled solution. Specifically, our theory shows that the SGD momentum is essentially a confounder in long-tailed classification. On one hand, it has a harmful causal effect that misleads the tail prediction biased towards the head. On the other hand, its induced mediation also benefits the representation learning and head prediction. Our framework elegantly disentangles the paradoxical effects of the momentum, by pursuing the direct causal effect caused by an input sample. In particular, we use causal intervention in training, and counterfactual reasoning in inference, to remove the "bad" while keep the "good". We achieve new state-of-the-arts on three long-tailed visual recognition benchmarks: Long-tailed CIFAR-10/-100, ImageNet-LT for image classification and LVIS for instance segmentation.
PCPL: Predicate-Correlation Perception Learning for Unbiased Scene Graph Generation
Sep 02, 2020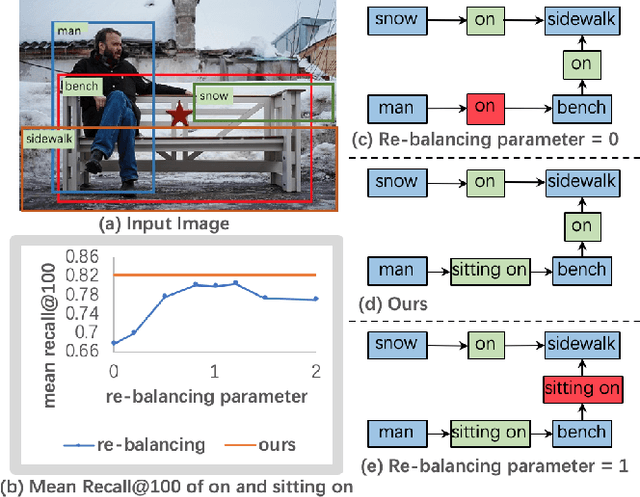
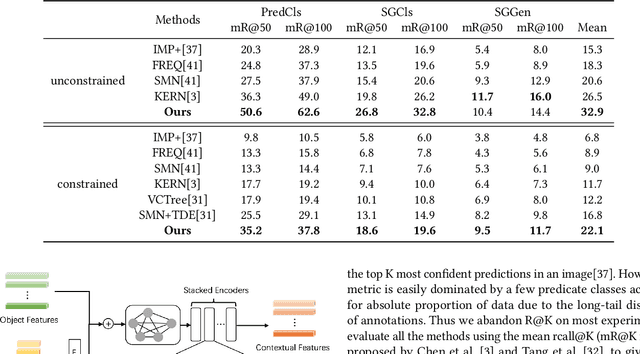
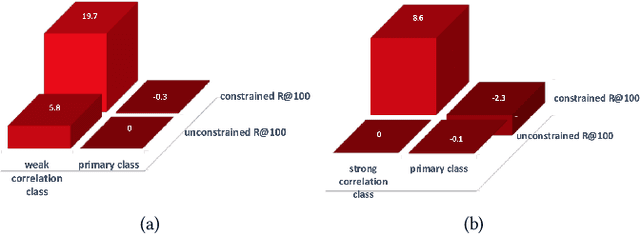
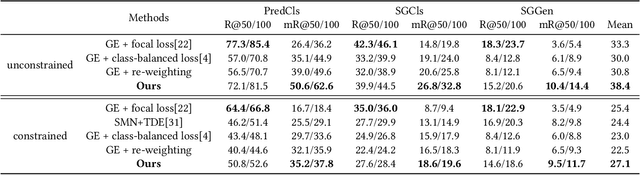
Today, scene graph generation(SGG) task is largely limited in realistic scenarios, mainly due to the extremely long-tailed bias of predicate annotation distribution. Thus, tackling the class imbalance trouble of SGG is critical and challenging. In this paper, we first discover that when predicate labels have strong correlation with each other, prevalent re-balancing strategies(e.g., re-sampling and re-weighting) will give rise to either over-fitting the tail data(e.g., bench sitting on sidewalk rather than on), or still suffering the adverse effect from the original uneven distribution(e.g., aggregating varied parked on/standing on/sitting on into on). We argue the principal reason is that re-balancing strategies are sensitive to the frequencies of predicates yet blind to their relatedness, which may play a more important role to promote the learning of predicate features. Therefore, we propose a novel Predicate-Correlation Perception Learning(PCPL for short) scheme to adaptively seek out appropriate loss weights by directly perceiving and utilizing the correlation among predicate classes. Moreover, our PCPL framework is further equipped with a graph encoder module to better extract context features. Extensive experiments on the benchmark VG150 dataset show that the proposed PCPL performs markedly better on tail classes while well-preserving the performance on head ones, which significantly outperforms previous state-of-the-art methods.
Apparel-invariant Feature Learning for Apparel-changed Person Re-identification
Aug 17, 2020
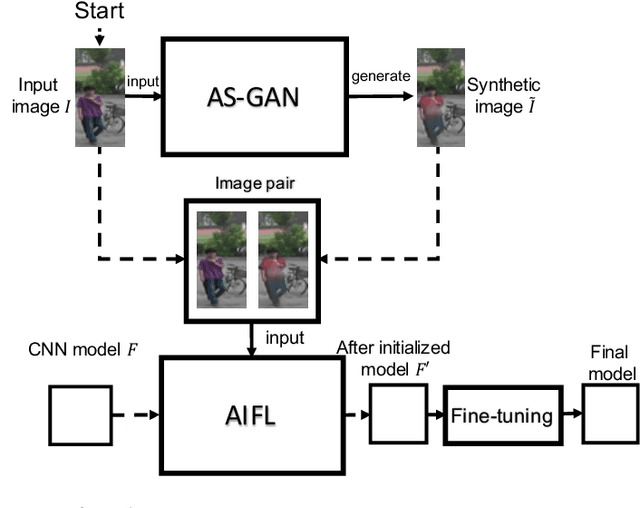
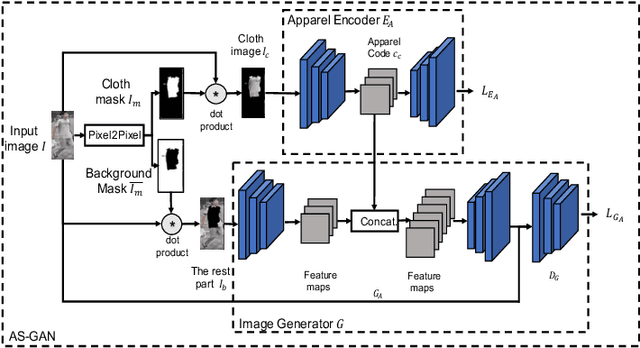

With the rise of deep learning methods, person Re-Identification (ReID) performance has been improved tremendously in many public datasets. However, most public ReID datasets are collected in a short time window in which persons' appearance rarely changes. In real-world applications such as in a shopping mall, the same person's clothing may change, and different persons may wearing similar clothes. All these cases can result in an inconsistent ReID performance, revealing a critical problem that current ReID models heavily rely on person's apparels. Therefore, it is critical to learn an apparel-invariant person representation under cases like cloth changing or several persons wearing similar clothes. In this work, we tackle this problem from the viewpoint of invariant feature representation learning. The main contributions of this work are as follows. (1) We propose the semi-supervised Apparel-invariant Feature Learning (AIFL) framework to learn an apparel-invariant pedestrian representation using images of the same person wearing different clothes. (2) To obtain images of the same person wearing different clothes, we propose an unsupervised apparel-simulation GAN (AS-GAN) to synthesize cloth changing images according to the target cloth embedding. It's worth noting that the images used in ReID tasks were cropped from real-world low-quality CCTV videos, making it more challenging to synthesize cloth changing images. We conduct extensive experiments on several datasets comparing with several baselines. Experimental results demonstrate that our proposal can improve the ReID performance of the baseline models.