 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThrough the Lens of Contrast: Self-Improving Visual Reasoning in VLMs
Mar 03, 2026Reasoning has emerged as a key capability of large language models. In linguistic tasks, this capability can be enhanced by self-improving techniques that refine reasoning paths for subsequent finetuning. However, extending these language-based self-improving approaches to vision language models (VLMs) presents a unique challenge:~visual hallucinations in reasoning paths cannot be effectively verified or rectified. Our solution starts with a key observation about visual contrast: when presented with a contrastive VQA pair, i.e., two visually similar images with synonymous questions, VLMs identify relevant visual cues more precisely. Motivated by this observation, we propose Visual Contrastive Self-Taught Reasoner (VC-STaR), a novel self-improving framework that leverages visual contrast to mitigate hallucinations in model-generated rationales. We collect a diverse suite of VQA datasets, curate contrastive pairs according to multi-modal similarity, and generate rationales using VC-STaR. Consequently, we obtain a new visual reasoning dataset, VisCoR-55K, which is then used to boost the reasoning capability of various VLMs through supervised finetuning. Extensive experiments show that VC-STaR not only outperforms existing self-improving approaches but also surpasses models finetuned on the SoTA visual reasoning datasets, demonstrating that the inherent contrastive ability of VLMs can bootstrap their own visual reasoning. Project at: https://github.com/zhiyupan42/VC-STaR.
Enhancing Weakly Supervised Multimodal Video Anomaly Detection through Text Guidance
Feb 11, 2026Weakly supervised multimodal video anomaly detection has gained significant attention, yet the potential of the text modality remains under-explored. Text provides explicit semantic information that can enhance anomaly characterization and reduce false alarms. However, extracting effective text features is challenging due to the inability of general-purpose language models to capture anomaly-specific nuances and the scarcity of relevant descriptions. Furthermore, multimodal fusion often suffers from redundancy and imbalance. To address these issues, we propose a novel text-guided framework. First, we introduce an in-context learning-based multi-stage text augmentation mechanism to generate high-quality anomaly text samples for fine-tuning the text feature extractor. Second, we design a multi-scale bottleneck Transformer fusion module that uses compressed bottleneck tokens to progressively integrate information across modalities, mitigating redundancy and imbalance. Experiments on UCF-Crime and XD-Violence demonstrate state-of-the-art performance.
Online Convolutional Re-parameterization
Apr 02, 2022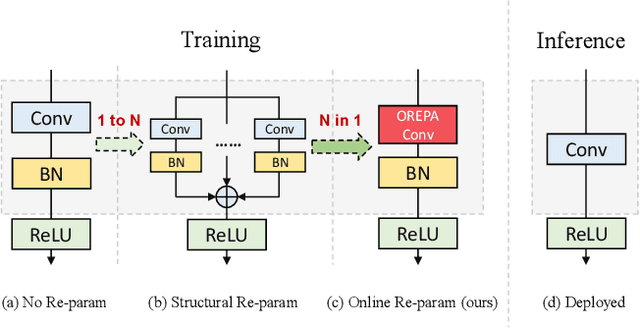
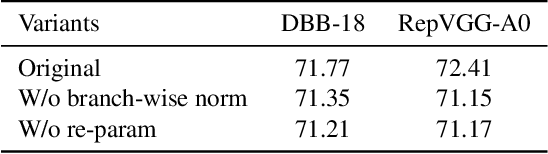
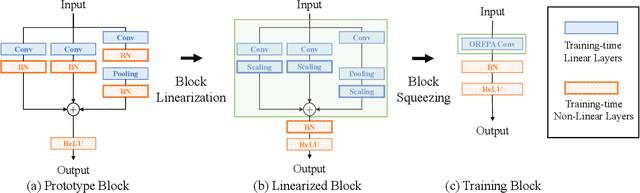
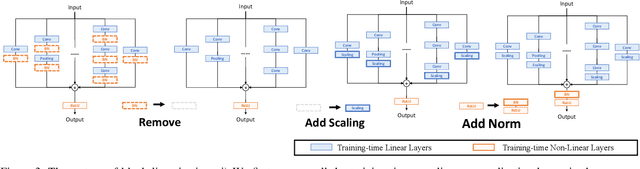
Structural re-parameterization has drawn increasing attention in various computer vision tasks. It aims at improving the performance of deep models without introducing any inference-time cost. Though efficient during inference, such models rely heavily on the complicated training-time blocks to achieve high accuracy, leading to large extra training cost. In this paper, we present online convolutional re-parameterization (OREPA), a two-stage pipeline, aiming to reduce the huge training overhead by squeezing the complex training-time block into a single convolution. To achieve this goal, we introduce a linear scaling layer for better optimizing the online blocks. Assisted with the reduced training cost, we also explore some more effective re-param components. Compared with the state-of-the-art re-param models, OREPA is able to save the training-time memory cost by about 70% and accelerate the training speed by around 2x. Meanwhile, equipped with OREPA, the models outperform previous methods on ImageNet by up to +0.6%.We also conduct experiments on object detection and semantic segmentation and show consistent improvements on the downstream tasks. Codes are available at https://github.com/JUGGHM/OREPA_CVPR2022 .
Learning to Generate Content-Aware Dynamic Detectors
Dec 08, 2020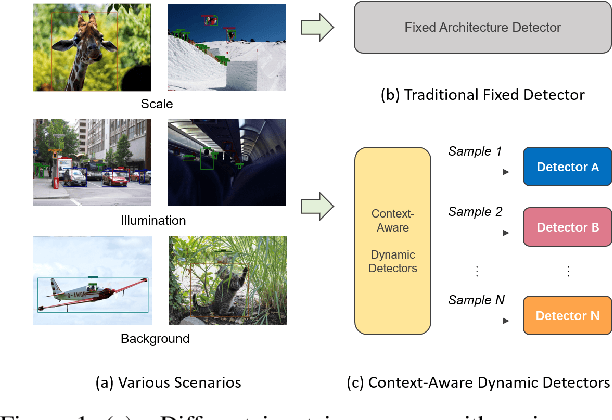
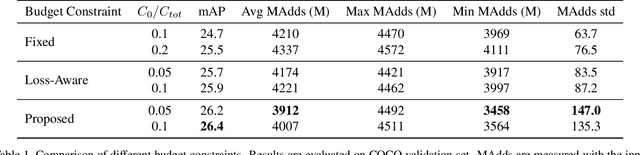
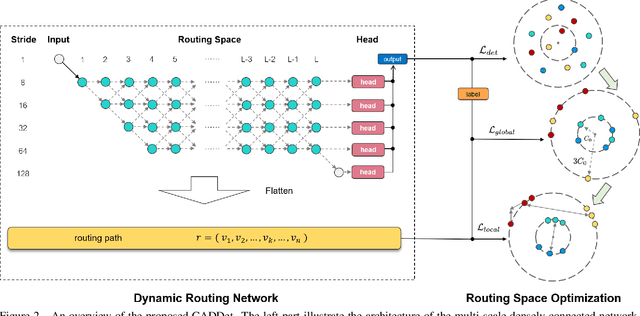
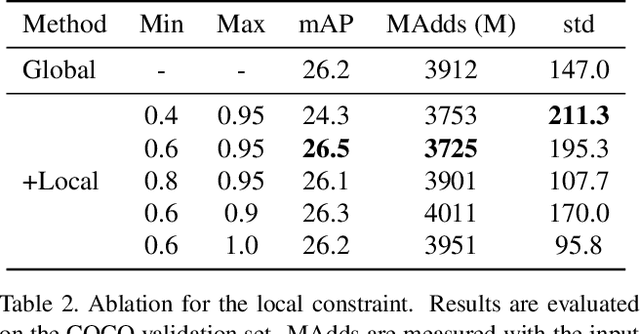
Model efficiency is crucial for object detection. Mostprevious works rely on either hand-crafted design or auto-search methods to obtain a static architecture, regardless ofthe difference of inputs. In this paper, we introduce a newperspective of designing efficient detectors, which is automatically generating sample-adaptive model architectureon the fly. The proposed method is named content-aware dynamic detectors (CADDet). It first applies a multi-scale densely connected network with dynamic routing as the supernet. Furthermore, we introduce a course-to-fine strat-egy tailored for object detection to guide the learning of dynamic routing, which contains two metrics: 1) dynamic global budget constraint assigns data-dependent expectedbudgets for individual samples; 2) local path similarity regularization aims to generate more diverse routing paths. With these, our method achieves higher computational efficiency while maintaining good performance. To the best of our knowledge, our CADDet is the first work to introduce dynamic routing mechanism in object detection. Experiments on MS-COCO dataset demonstrate that CADDet achieves 1.8 higher mAP with 10% fewer FLOPs compared with vanilla routing strategy. Compared with the models based upon similar building blocks, CADDet achieves a 42% FLOPs reduction with a competitive mAP.
How to Train Your Dragon: Tamed Warping Network for Semantic Video Segmentation
May 04, 2020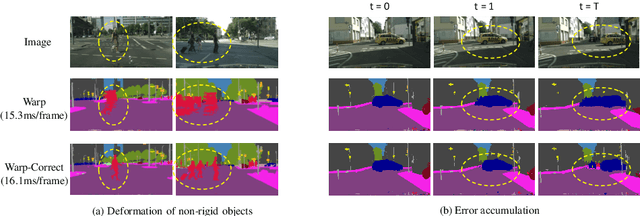
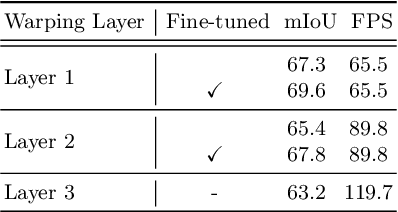
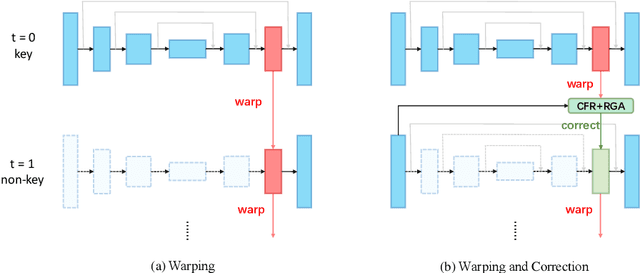
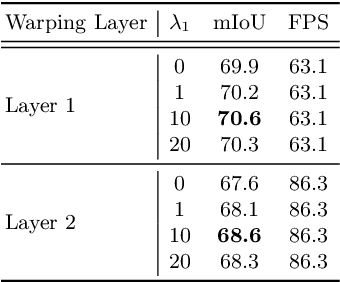
Real-time semantic segmentation on high-resolution videos is challenging due to the strict requirements of speed. Recent approaches have utilized the inter-frame continuity to reduce redundant computation by warping the feature maps across adjacent frames, greatly speeding up the inference phase. However, their accuracy drops significantly owing to the imprecise motion estimation and error accumulation. In this paper, we propose to introduce a simple and effective correction stage right after the warping stage to form a framework named Tamed Warping Network (TWNet), aiming to improve the accuracy and robustness of warping-based models. The experimental results on the Cityscapes dataset show that with the correction, the accuracy (mIoU) significantly increases from 67.3% to 71.6%, and the speed edges down from 65.5 FPS to 61.8 FPS. For non-rigid categories such as "human" and "object", the improvements of IoU are even higher than 18 percentage points.
BANet: Bidirectional Aggregation Network with Occlusion Handling for Panoptic Segmentation
Mar 31, 2020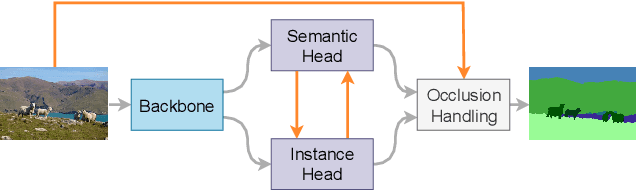
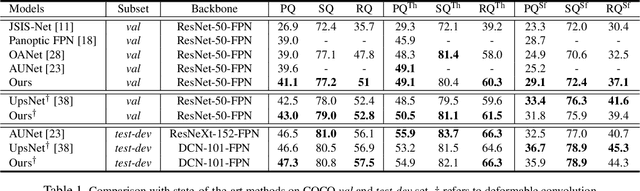
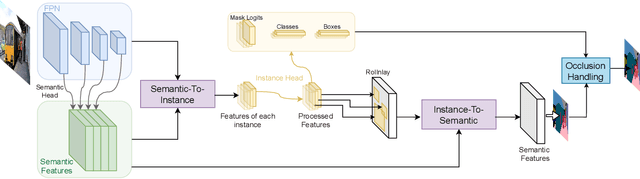

Panoptic segmentation aims to perform instance segmentation for foreground instances and semantic segmentation for background stuff simultaneously. The typical top-down pipeline concentrates on two key issues: 1) how to effectively model the intrinsic interaction between semantic segmentation and instance segmentation, and 2) how to properly handle occlusion for panoptic segmentation. Intuitively, the complementarity between semantic segmentation and instance segmentation can be leveraged to improve the performance. Besides, we notice that using detection/mask scores is insufficient for resolving the occlusion problem. Motivated by these observations, we propose a novel deep panoptic segmentation scheme based on a bidirectional learning pipeline. Moreover, we introduce a plug-and-play occlusion handling algorithm to deal with the occlusion between different object instances. The experimental results on COCO panoptic benchmark validate the effectiveness of our proposed method. Codes will be released soon at https://github.com/Mooonside/BANet.
TapLab: A Fast Framework for Semantic Video Segmentation Tapping into Compressed-Domain Knowledge
Mar 30, 2020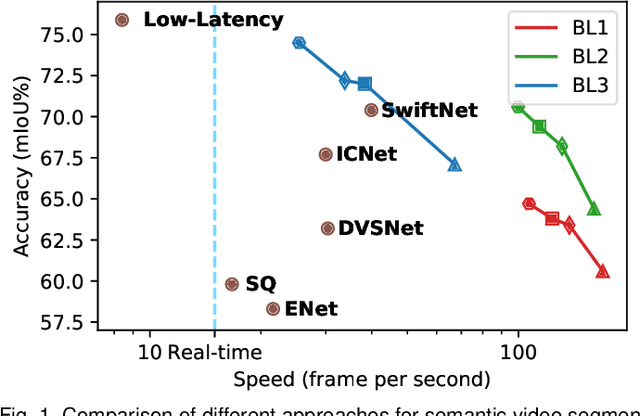
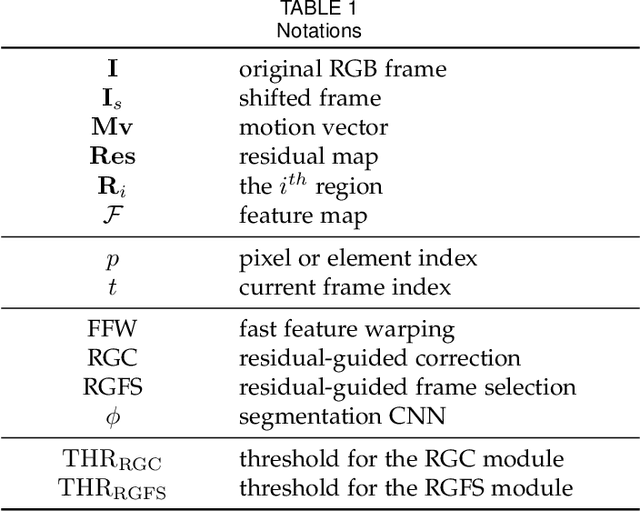
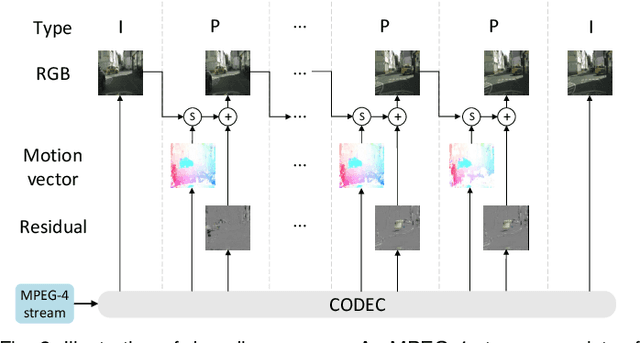

Real-time semantic video segmentation is a challenging task due to the strict requirements of inference speed. Recent approaches mainly devote great efforts to reducing the model size for high efficiency. In this paper, we rethink this problem from a different viewpoint: using knowledge contained in compressed videos. We propose a simple and effective framework, dubbed TapLab, to tap into resources from the compressed domain. Specifically, we design a fast feature warping module using motion vectors for acceleration. To reduce the noise introduced by motion vectors, we design a residual-guided correction module and a residual-guided frame selection module using residuals. Compared with the state-of-the-art fast semantic image segmentation models, our proposed TapLab significantly reduces redundant computations, running around 3 times faster with comparable accuracy for 1024x2048 video. The experimental results show that TapLab achieves 70.6% mIoU on the Cityscapes dataset at 99.8 FPS with a single GPU card. A high-speed version even reaches the speed of 160+ FPS.
Deep Q Learning Driven CT Pancreas Segmentation with Geometry-Aware U-Net
Apr 19, 2019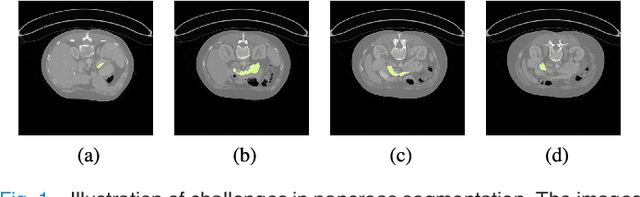
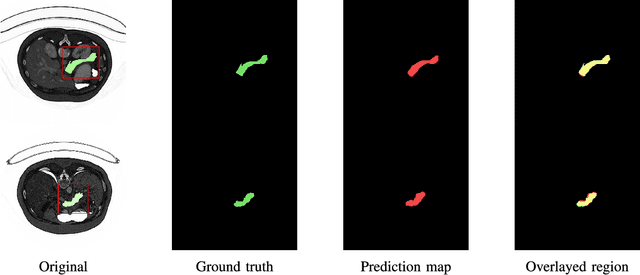
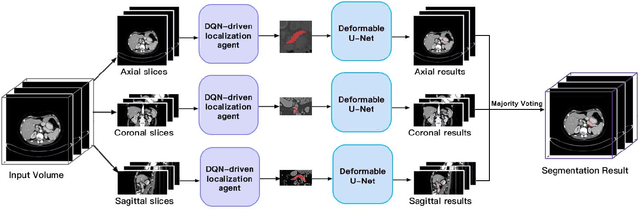
Segmentation of pancreas is important for medical image analysis, yet it faces great challenges of class imbalance, background distractions and non-rigid geometrical features. To address these difficulties, we introduce a Deep Q Network(DQN) driven approach with deformable U-Net to accurately segment the pancreas by explicitly interacting with contextual information and extract anisotropic features from pancreas. The DQN based model learns a context-adaptive localization policy to produce a visually tightened and precise localization bounding box of the pancreas. Furthermore, deformable U-Net captures geometry-aware information of pancreas by learning geometrically deformable filters for feature extraction. Experiments on NIH dataset validate the effectiveness of the proposed framework in pancreas segmentation.