 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Guided Image Completion with Image-level and Object-level Semantic Discriminators
Dec 13, 2022Structure-guided image completion aims to inpaint a local region of an image according to an input guidance map from users. While such a task enables many practical applications for interactive editing, existing methods often struggle to hallucinate realistic object instances in complex natural scenes. Such a limitation is partially due to the lack of semantic-level constraints inside the hole region as well as the lack of a mechanism to enforce realistic object generation. In this work, we propose a learning paradigm that consists of semantic discriminators and object-level discriminators for improving the generation of complex semantics and objects. Specifically, the semantic discriminators leverage pretrained visual features to improve the realism of the generated visual concepts. Moreover, the object-level discriminators take aligned instances as inputs to enforce the realism of individual objects. Our proposed scheme significantly improves the generation quality and achieves state-of-the-art results on various tasks, including segmentation-guided completion, edge-guided manipulation and panoptically-guided manipulation on Places2 datasets. Furthermore, our trained model is flexible and can support multiple editing use cases, such as object insertion, replacement, removal and standard inpainting. In particular, our trained model combined with a novel automatic image completion pipeline achieves state-of-the-art results on the standard inpainting task.
Perspective Fields for Single Image Camera Calibration
Dec 06, 2022



Geometric camera calibration is often required for applications that understand the perspective of the image. We propose perspective fields as a representation that models the local perspective properties of an image. Perspective Fields contain per-pixel information about the camera view, parameterized as an up vector and a latitude value. This representation has a number of advantages as it makes minimal assumptions about the camera model and is invariant or equivariant to common image editing operations like cropping, warping, and rotation. It is also more interpretable and aligned with human perception. We train a neural network to predict Perspective Fields and the predicted Perspective Fields can be converted to calibration parameters easily. We demonstrate the robustness of our approach under various scenarios compared with camera calibration-based methods and show example applications in image compositing.
ObjectStitch: Generative Object Compositing
Dec 05, 2022



Object compositing based on 2D images is a challenging problem since it typically involves multiple processing stages such as color harmonization, geometry correction and shadow generation to generate realistic results. Furthermore, annotating training data pairs for compositing requires substantial manual effort from professionals, and is hardly scalable. Thus, with the recent advances in generative models, in this work, we propose a self-supervised framework for object compositing by leveraging the power of conditional diffusion models. Our framework can hollistically address the object compositing task in a unified model, transforming the viewpoint, geometry, color and shadow of the generated object while requiring no manual labeling. To preserve the input object's characteristics, we introduce a content adaptor that helps to maintain categorical semantics and object appearance. A data augmentation method is further adopted to improve the fidelity of the generator. Our method outperforms relevant baselines in both realism and faithfulness of the synthesized result images in a user study on various real-world images.
SceneComposer: Any-Level Semantic Image Synthesis
Nov 21, 2022



We propose a new framework for conditional image synthesis from semantic layouts of any precision levels, ranging from pure text to a 2D semantic canvas with precise shapes. More specifically, the input layout consists of one or more semantic regions with free-form text descriptions and adjustable precision levels, which can be set based on the desired controllability. The framework naturally reduces to text-to-image (T2I) at the lowest level with no shape information, and it becomes segmentation-to-image (S2I) at the highest level. By supporting the levels in-between, our framework is flexible in assisting users of different drawing expertise and at different stages of their creative workflow. We introduce several novel techniques to address the challenges coming with this new setup, including a pipeline for collecting training data; a precision-encoded mask pyramid and a text feature map representation to jointly encode precision level, semantics, and composition information; and a multi-scale guided diffusion model to synthesize images. To evaluate the proposed method, we collect a test dataset containing user-drawn layouts with diverse scenes and styles. Experimental results show that the proposed method can generate high-quality images following the layout at given precision, and compares favorably against existing methods. Project page \url{https://zengxianyu.github.io/scenec/}
Distributed Multi-Robot Obstacle Avoidance via Logarithmic Map-based Deep Reinforcement Learning
Sep 14, 2022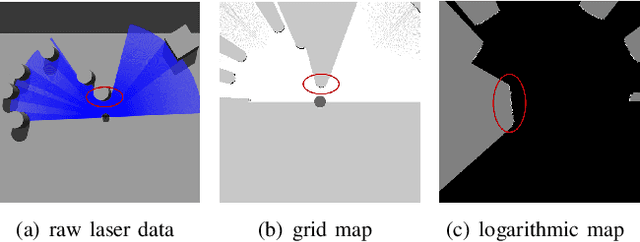

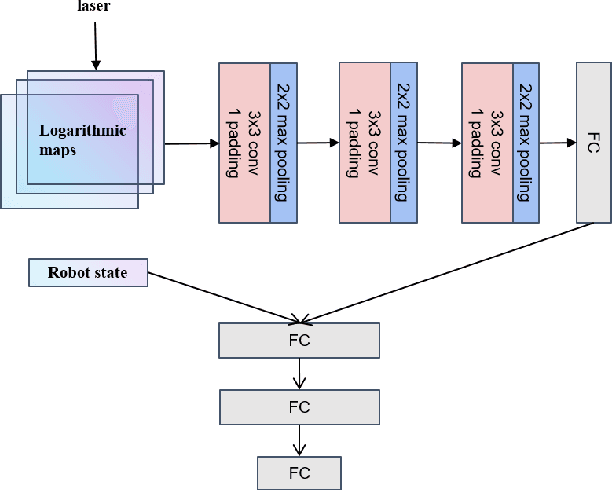
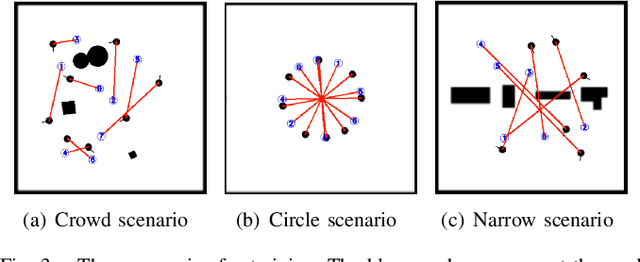
Developing a safe, stable, and efficient obstacle avoidance policy in crowded and narrow scenarios for multiple robots is challenging. Most existing studies either use centralized control or need communication with other robots. In this paper, we propose a novel logarithmic map-based deep reinforcement learning method for obstacle avoidance in complex and communication-free multi-robot scenarios. In particular, our method converts laser information into a logarithmic map. As a step toward improving training speed and generalization performance, our policies will be trained in two specially designed multi-robot scenarios. Compared to other methods, the logarithmic map can represent obstacles more accurately and improve the success rate of obstacle avoidance. We finally evaluate our approach under a variety of simulation and real-world scenarios. The results show that our method provides a more stable and effective navigation solution for robots in complex multi-robot scenarios and pedestrian scenarios. Videos are available at https://youtu.be/r0EsUXe6MZE.
Towards Accurate Reconstruction of 3D Scene Shape from A Single Monocular Image
Aug 28, 2022

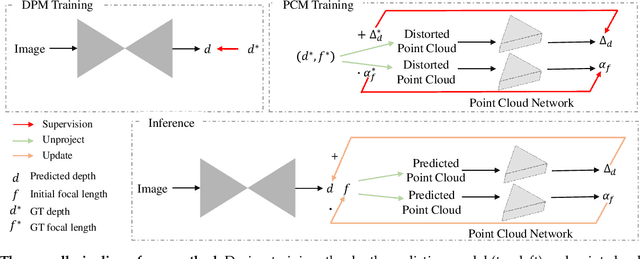

Despite significant progress made in the past few years, challenges remain for depth estimation using a single monocular image. First, it is nontrivial to train a metric-depth prediction model that can generalize well to diverse scenes mainly due to limited training data. Thus, researchers have built large-scale relative depth datasets that are much easier to collect. However, existing relative depth estimation models often fail to recover accurate 3D scene shapes due to the unknown depth shift caused by training with the relative depth data. We tackle this problem here and attempt to estimate accurate scene shapes by training on large-scale relative depth data, and estimating the depth shift. To do so, we propose a two-stage framework that first predicts depth up to an unknown scale and shift from a single monocular image, and then exploits 3D point cloud data to predict the depth shift and the camera's focal length that allow us to recover 3D scene shapes. As the two modules are trained separately, we do not need strictly paired training data. In addition, we propose an image-level normalized regression loss and a normal-based geometry loss to improve training with relative depth annotation. We test our depth model on nine unseen datasets and achieve state-of-the-art performance on zero-shot evaluation. Code is available at: https://git.io/Depth
Text-to-Image Generation via Implicit Visual Guidance and Hypernetwork
Aug 17, 2022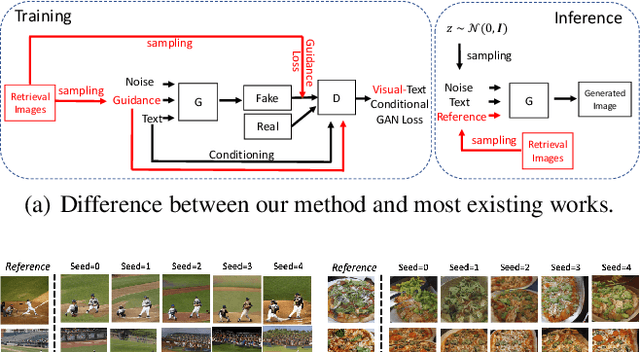
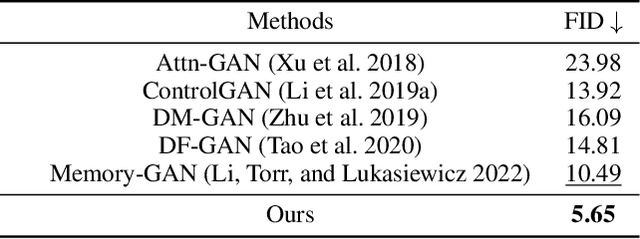
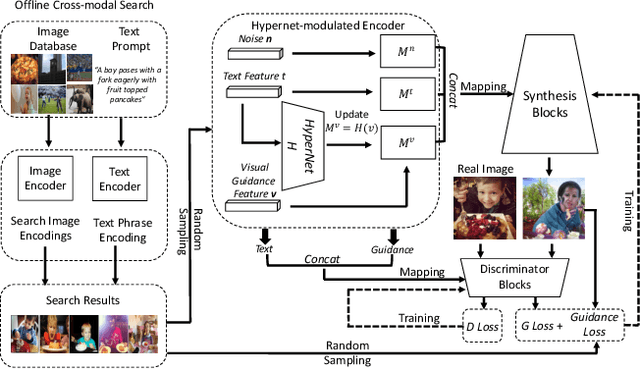
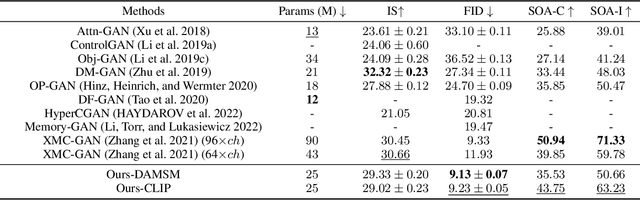
We develop an approach for text-to-image generation that embraces additional retrieval images, driven by a combination of implicit visual guidance loss and generative objectives. Unlike most existing text-to-image generation methods which merely take the text as input, our method dynamically feeds cross-modal search results into a unified training stage, hence improving the quality, controllability and diversity of generation results. We propose a novel hypernetwork modulated visual-text encoding scheme to predict the weight update of the encoding layer, enabling effective transfer from visual information (e.g. layout, content) into the corresponding latent domain. Experimental results show that our model guided with additional retrieval visual data outperforms existing GAN-based models. On COCO dataset, we achieve better FID of $9.13$ with up to $3.5 \times$ fewer generator parameters, compared with the state-of-the-art method.
Less is More: Consistent Video Depth Estimation with Masked Frames Modeling
Jul 31, 2022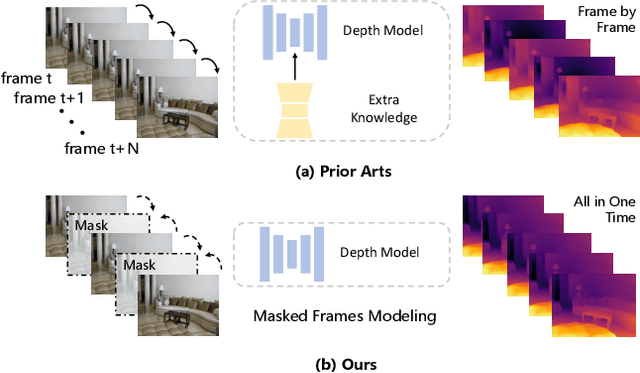
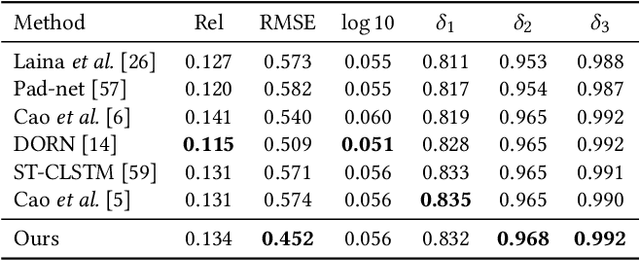
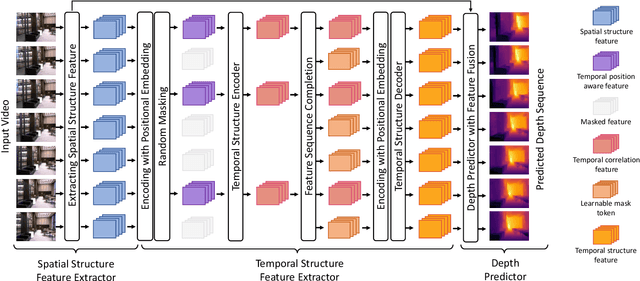
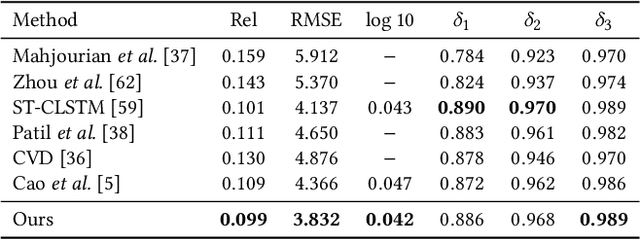
Temporal consistency is the key challenge of video depth estimation. Previous works are based on additional optical flow or camera poses, which is time-consuming. By contrast, we derive consistency with less information. Since videos inherently exist with heavy temporal redundancy, a missing frame could be recovered from neighboring ones. Inspired by this, we propose the frame masking network (FMNet), a spatial-temporal transformer network predicting the depth of masked frames based on their neighboring frames. By reconstructing masked temporal features, the FMNet can learn intrinsic inter-frame correlations, which leads to consistency. Compared with prior arts, experimental results demonstrate that our approach achieves comparable spatial accuracy and higher temporal consistency without any additional information. Our work provides a new perspective on consistent video depth estimation.
Towards Domain-agnostic Depth Completion
Jul 29, 2022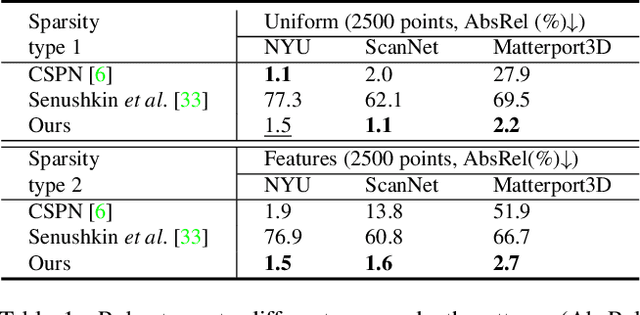

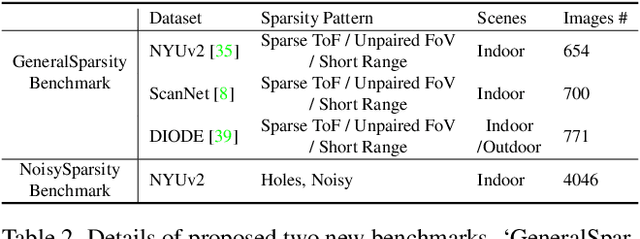

Existing depth completion methods are often targeted at a specific sparse depth type, and generalize poorly across task domains. We present a method to complete sparse/semi-dense, noisy, and potentially low-resolution depth maps obtained by various range sensors, including those in modern mobile phones, or by multi-view reconstruction algorithms. Our method leverages a data driven prior in the form of a single image depth prediction network trained on large-scale datasets, the output of which is used as an input to our model. We propose an effective training scheme where we simulate various sparsity patterns in typical task domains. In addition, we design two new benchmarks to evaluate the generalizability and the robustness of depth completion methods. Our simple method shows superior cross-domain generalization ability against state-of-the-art depth completion methods, introducing a practical solution to high quality depth capture on a mobile device. Code is available at: https://github.com/YvanYin/FillDepth.
MPIB: An MPI-Based Bokeh Rendering Framework for Realistic Partial Occlusion Effects
Jul 18, 2022
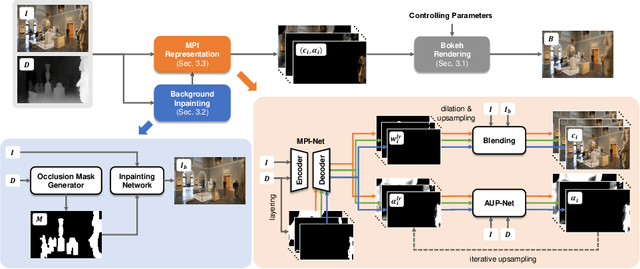

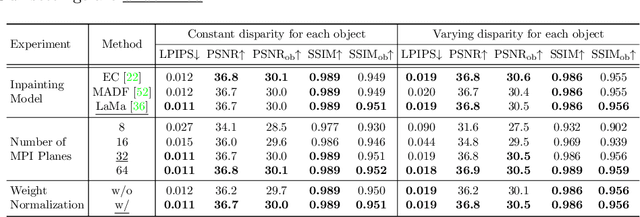
Partial occlusion effects are a phenomenon that blurry objects near a camera are semi-transparent, resulting in partial appearance of occluded background. However, it is challenging for existing bokeh rendering methods to simulate realistic partial occlusion effects due to the missing information of the occluded area in an all-in-focus image. Inspired by the learnable 3D scene representation, Multiplane Image (MPI), we attempt to address the partial occlusion by introducing a novel MPI-based high-resolution bokeh rendering framework, termed MPIB. To this end, we first present an analysis on how to apply the MPI representation to bokeh rendering. Based on this analysis, we propose an MPI representation module combined with a background inpainting module to implement high-resolution scene representation. This representation can then be reused to render various bokeh effects according to the controlling parameters. To train and test our model, we also design a ray-tracing-based bokeh generator for data generation. Extensive experiments on synthesized and real-world images validate the effectiveness and flexibility of this framework.