 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Abstractive Query-Focused Multi-Document Summarization
Mar 02, 2021
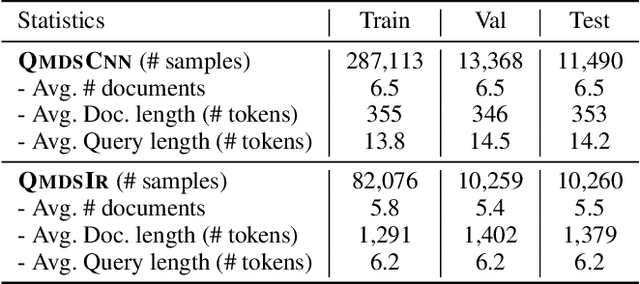
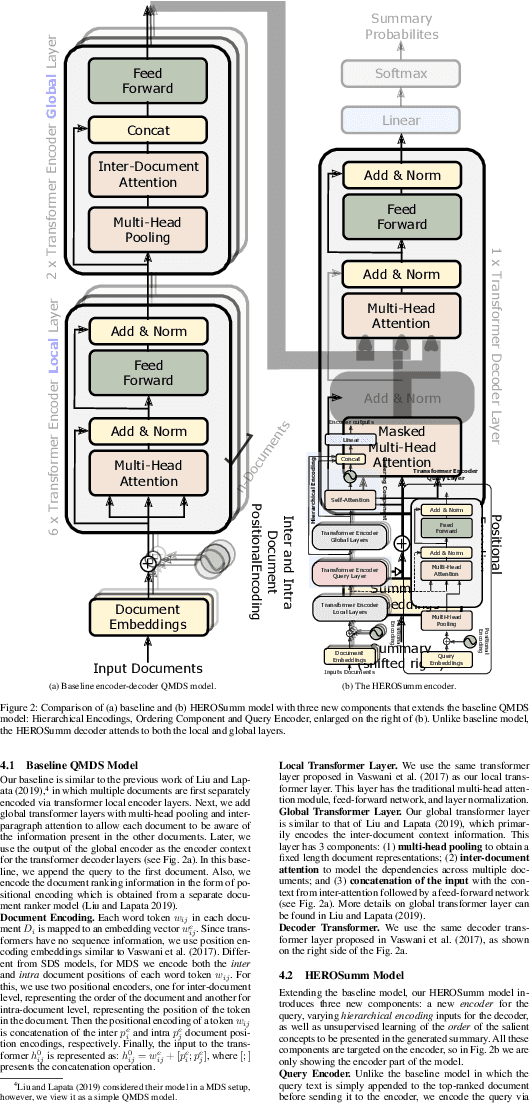
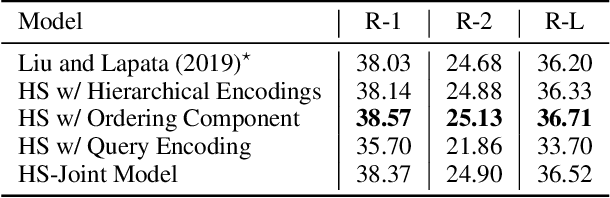
The progress in Query-focused Multi-Document Summarization (QMDS) has been limited by the lack of sufficient largescale high-quality training datasets. We present two QMDS training datasets, which we construct using two data augmentation methods: (1) transferring the commonly used single-document CNN/Daily Mail summarization dataset to create the QMDSCNN dataset, and (2) mining search-query logs to create the QMDSIR dataset. These two datasets have complementary properties, i.e., QMDSCNN has real summaries but queries are simulated, while QMDSIR has real queries but simulated summaries. To cover both these real summary and query aspects, we build abstractive end-to-end neural network models on the combined datasets that yield new state-of-the-art transfer results on DUC datasets. We also introduce new hierarchical encoders that enable a more efficient encoding of the query together with multiple documents. Empirical results demonstrate that our data augmentation and encoding methods outperform baseline models on automatic metrics, as well as on human evaluations along multiple attributes.
Learning to Shift Attention for Motion Generation
Feb 24, 2021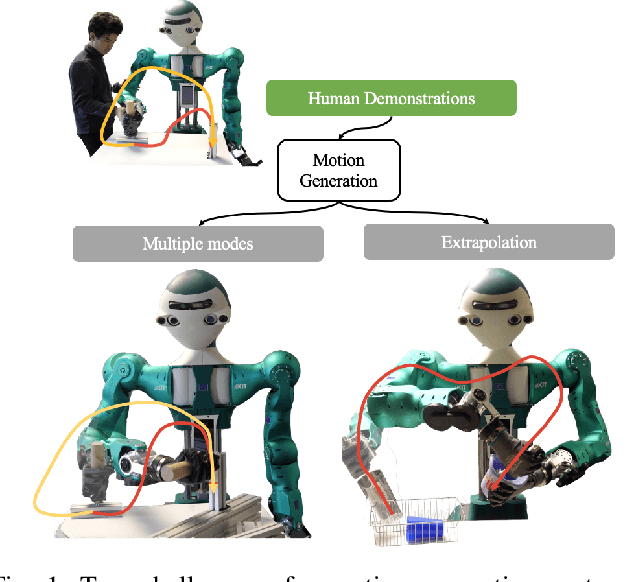
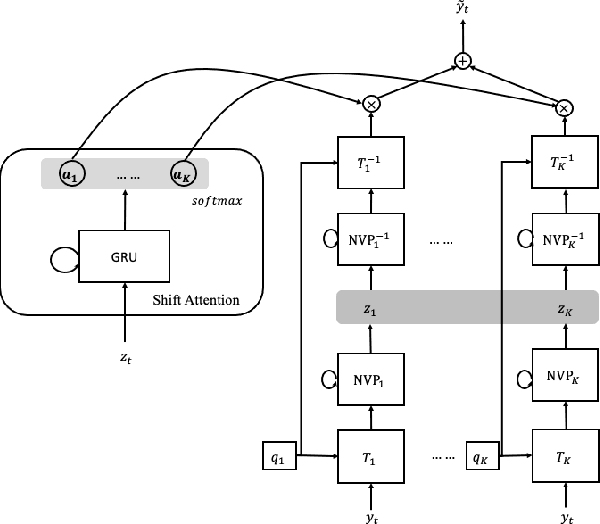
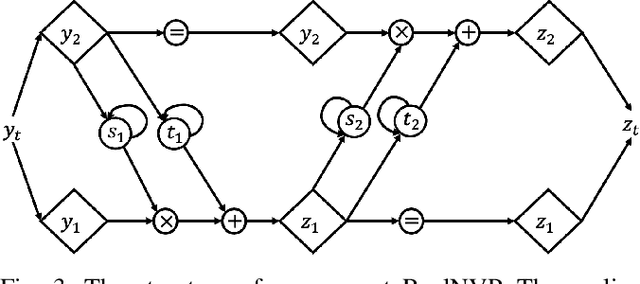
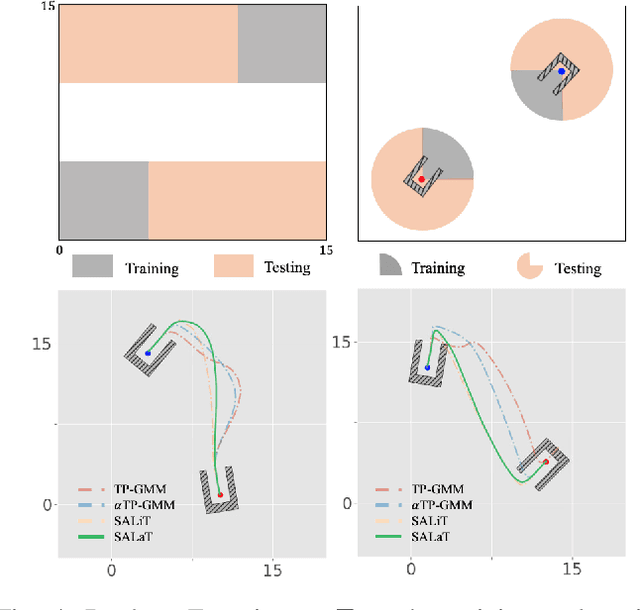
One challenge of motion generation using robot learning from demonstration techniques is that human demonstrations follow a distribution with multiple modes for one task query. Previous approaches fail to capture all modes or tend to average modes of the demonstrations and thus generate invalid trajectories. The other difficulty is the small number of demonstrations that cannot cover the entire working space. To overcome this problem, a motion generation model with extrapolation ability is needed. Previous works restrict task queries as local frames and learn representations in local frames. We propose a model to solve both problems. For multiple modes, we suggest to learn local latent representations of motion trajectories with a density estimation method based on real-valued non-volume preserving (RealNVP) transformations that provides a set of powerful, stably invertible, and learnable transformations. To improve the extrapolation ability, we propose to shift the attention of the robot from one local frame to another during the task execution. In experiments, we consider the docking problem used also in previous works where a trajectory has to be generated to connect two dockers without collision. We increase complexity of the task and show that the proposed method outperforms other approaches. In addition, we evaluate the approach in real robot experiments.
Self-supervised Pre-training with Hard Examples Improves Visual Representations
Jan 04, 2021
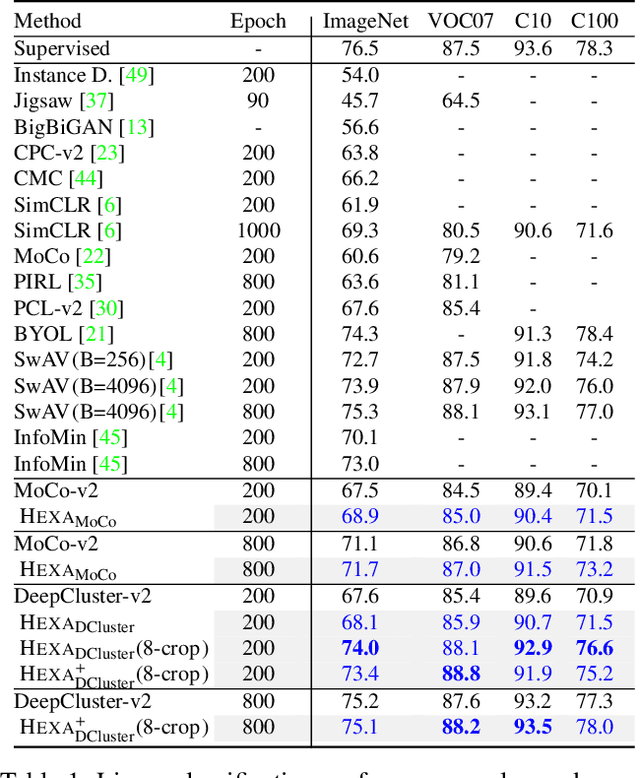
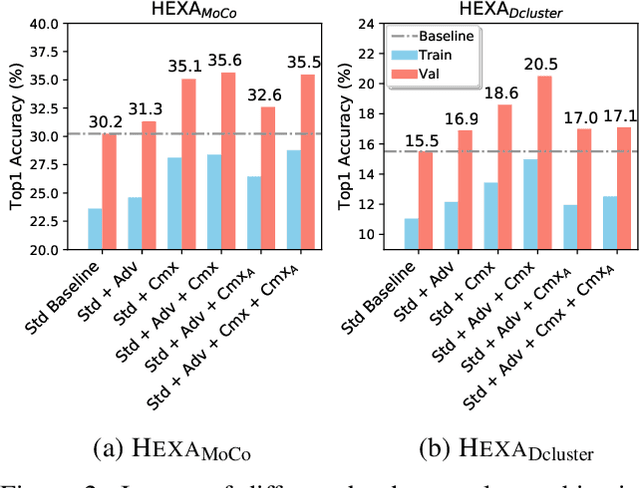
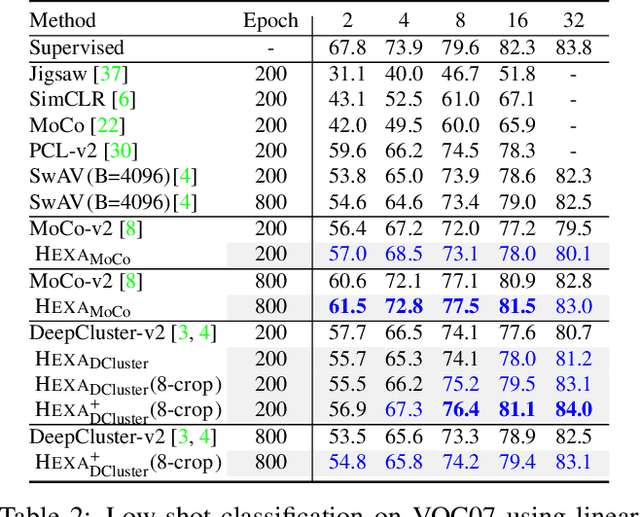
Self-supervised pre-training (SSP) employs random image transformations to generate training data for visual representation learning. In this paper, we first present a modeling framework that unifies existing SSP methods as learning to predict pseudo-labels. Then, we propose new data augmentation methods of generating training examples whose pseudo-labels are harder to predict than those generated via random image transformations. Specifically, we use adversarial training and CutMix to create hard examples (HEXA) to be used as augmented views for MoCo-v2 and DeepCluster-v2, leading to two variants HEXA_{MoCo} and HEXA_{DCluster}, respectively. In our experiments, we pre-train models on ImageNet and evaluate them on multiple public benchmarks. Our evaluation shows that the two new algorithm variants outperform their original counterparts, and achieve new state-of-the-art on a wide range of tasks where limited task supervision is available for fine-tuning. These results verify that hard examples are instrumental in improving the generalization of the pre-trained models.
VinVL: Making Visual Representations Matter in Vision-Language Models
Jan 02, 2021


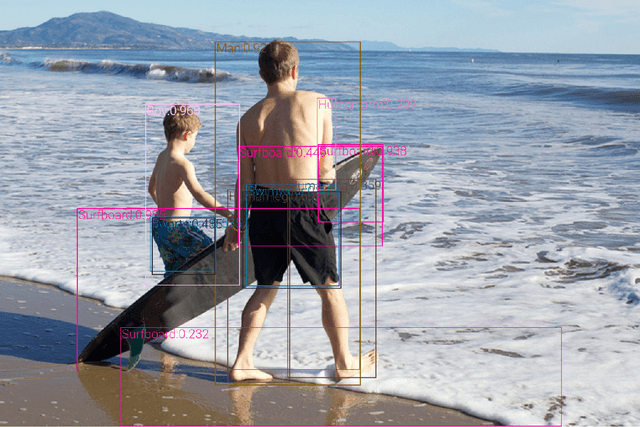
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used \emph{bottom-up and top-down} model \cite{anderson2018bottom}, the new model is bigger, better-designed for VL tasks, and pre-trained on much larger training corpora that combine multiple public annotated object detection datasets. Therefore, it can generate representations of a richer collection of visual objects and concepts. While previous VL research focuses mainly on improving the vision-language fusion model and leaves the object detection model improvement untouched, we show that visual features matter significantly in VL models. In our experiments we feed the visual features generated by the new object detection model into a Transformer-based VL fusion model \oscar \cite{li2020oscar}, and utilize an improved approach \short\ to pre-train the VL model and fine-tune it on a wide range of downstream VL tasks. Our results show that the new visual features significantly improve the performance across all VL tasks, creating new state-of-the-art results on seven public benchmarks. We will release the new object detection model to public.
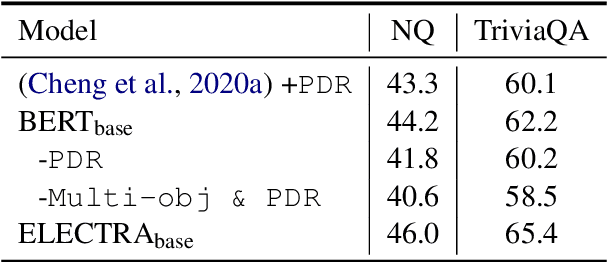
Reader-Guided Passage Reranking for Open-Domain Question Answering
Jan 01, 2021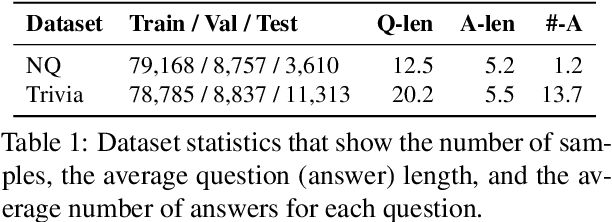
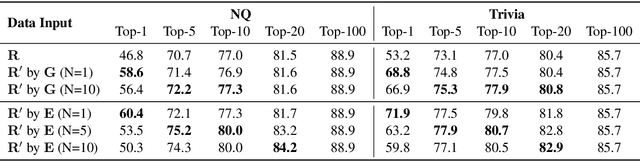
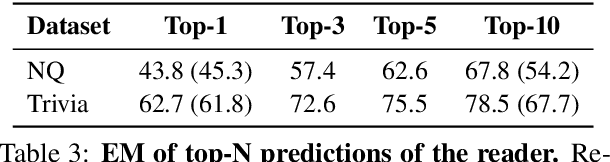
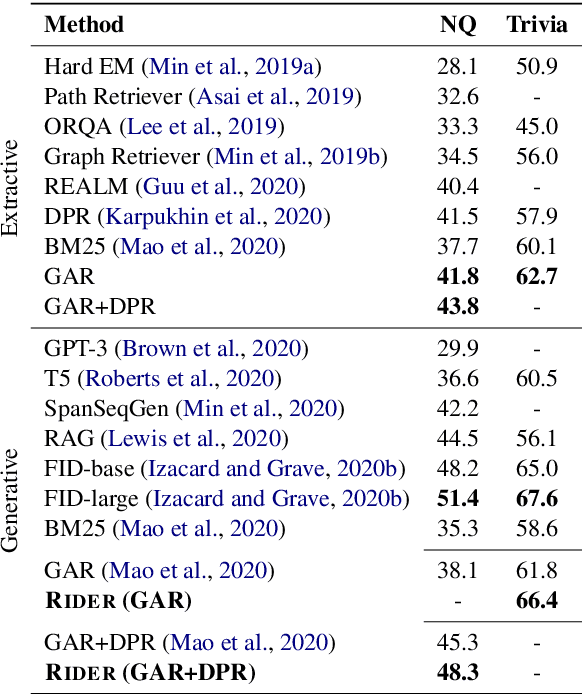
Current open-domain question answering (QA) systems often follow a Retriever-Reader (R2) architecture, where the retriever first retrieves relevant passages and the reader then reads the retrieved passages to form an answer. In this paper, we propose a simple and effective passage reranking method, Reader-guIDEd Reranker (Rider), which does not involve any training and reranks the retrieved passages solely based on the top predictions of the reader before reranking. We show that Rider, despite its simplicity, achieves 10 to 20 absolute gains in top-1 retrieval accuracy and 1 to 4 Exact Match (EM) score gains without refining the retriever or reader. In particular, Rider achieves 48.3 EM on the Natural Questions dataset and 66.4 on the TriviaQA dataset when only 1,024 tokens (7.8 passages on average) are used as the reader input.
UnitedQA: A Hybrid Approach for Open Domain Question Answering
Jan 01, 2021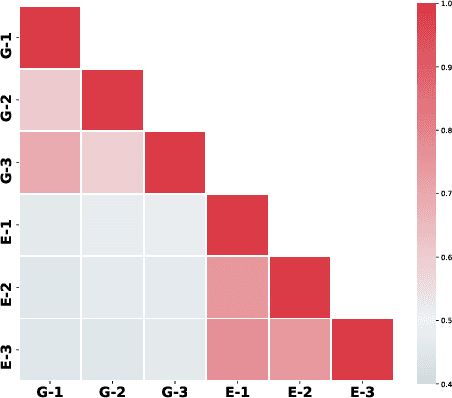
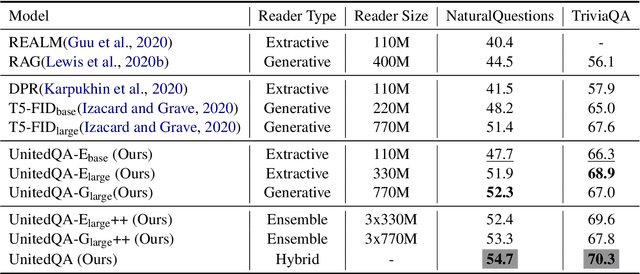
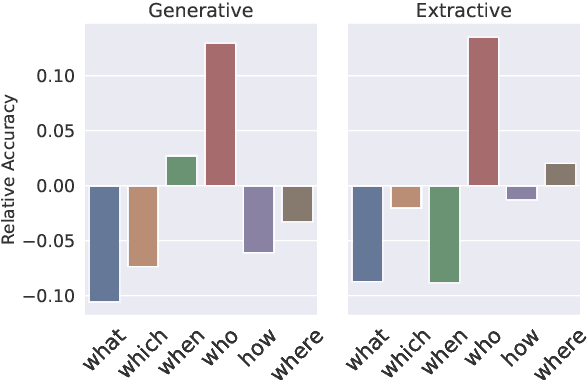
To date, most of recent work under the retrieval-reader framework for open-domain QA focuses on either extractive or generative reader exclusively. In this paper, we study a hybrid approach for leveraging the strengths of both models. We apply novel techniques to enhance both extractive and generative readers built upon recent pretrained neural language models, and find that proper training methods can provide large improvement over previous state-of-the-art models. We demonstrate that a simple hybrid approach by combining answers from both readers can efficiently take advantages of extractive and generative answer inference strategies and outperforms single models as well as homogeneous ensembles. Our approach outperforms previous state-of-the-art models by 3.3 and 2.7 points in exact match on NaturalQuestions and TriviaQA respectively.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021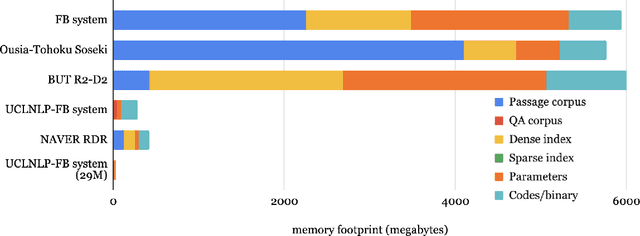
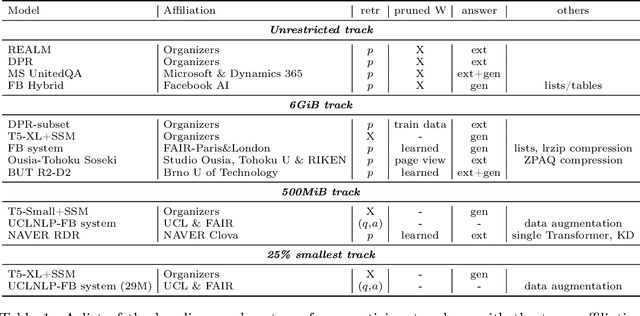
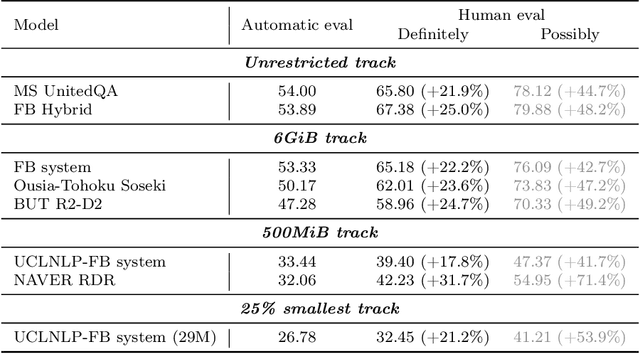
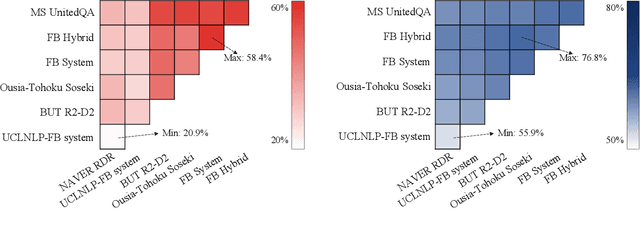
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Few-Shot Named Entity Recognition: A Comprehensive Study
Dec 29, 2020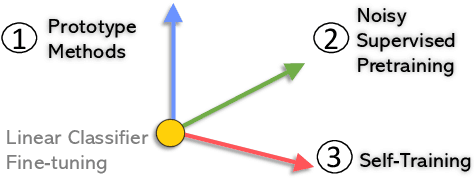

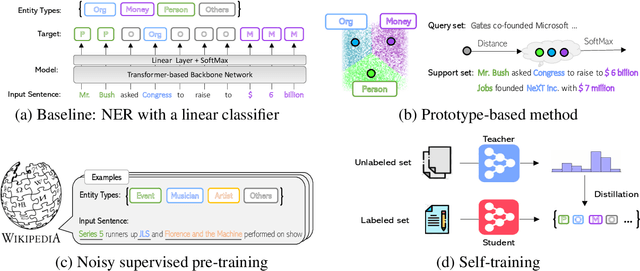
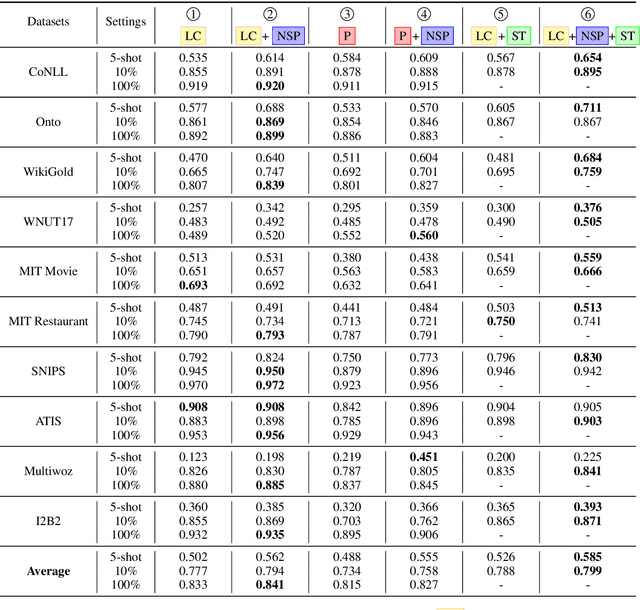
This paper presents a comprehensive study to efficiently build named entity recognition (NER) systems when a small number of in-domain labeled data is available. Based upon recent Transformer-based self-supervised pre-trained language models (PLMs), we investigate three orthogonal schemes to improve the model generalization ability for few-shot settings: (1) meta-learning to construct prototypes for different entity types, (2) supervised pre-training on noisy web data to extract entity-related generic representations and (3) self-training to leverage unlabeled in-domain data. Different combinations of these schemes are also considered. We perform extensive empirical comparisons on 10 public NER datasets with various proportions of labeled data, suggesting useful insights for future research. Our experiments show that (i) in the few-shot learning setting, the proposed NER schemes significantly improve or outperform the commonly used baseline, a PLM-based linear classifier fine-tuned on domain labels; (ii) We create new state-of-the-art results on both few-shot and training-free settings compared with existing methods. We will release our code and pre-trained models for reproducible research.
RADDLE: An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Systems
Dec 29, 2020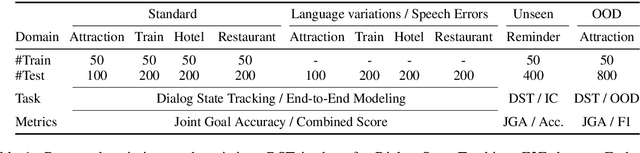
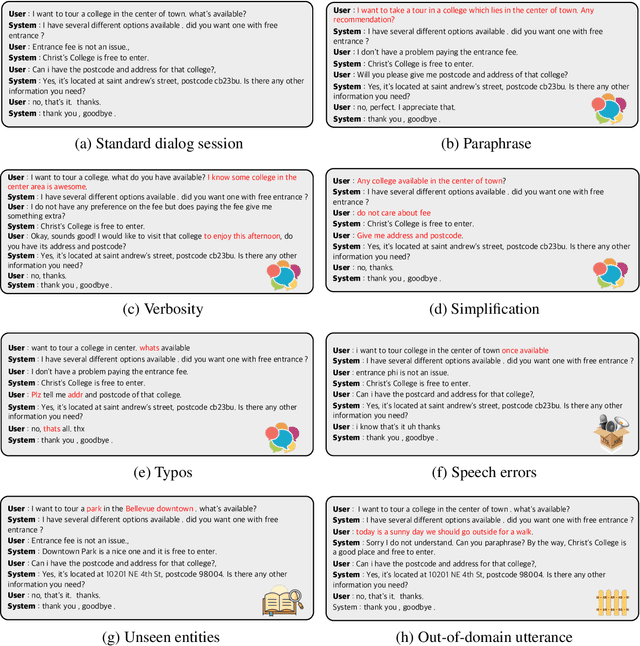

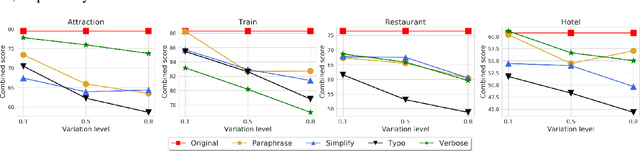
For task-oriented dialog systems to be maximally useful, it must be able to process conversations in a way that is (1) generalizable with a small number of training examples for new task domains, and (2) robust to user input in various styles, modalities or domains. In pursuit of these goals, we introduce the RADDLE benchmark, a collection of corpora and tools for evaluating the performance of models across a diverse set of domains. By including tasks with limited training data, RADDLE is designed to favor and encourage models with a strong generalization ability. RADDLE also includes a diagnostic checklist that facilitates detailed robustness analysis in aspects such as language variations, speech errors, unseen entities, and out-of-domain utterances. We evaluate recent state-of-the-art systems based on pre-training and fine-tuning, and find that grounded pre-training on heterogeneous dialog corpora performs better than training a separate model per domain. Overall, existing models are less than satisfactory in robustness evaluation, which suggests opportunities for future improvement.
MiniVLM: A Smaller and Faster Vision-Language Model
Dec 13, 2020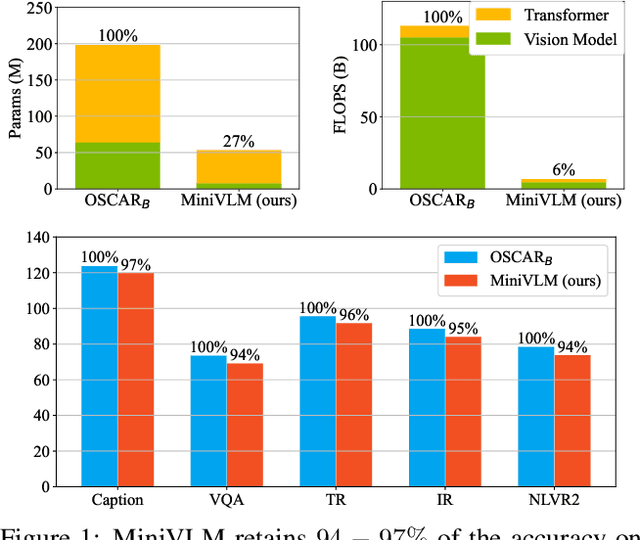
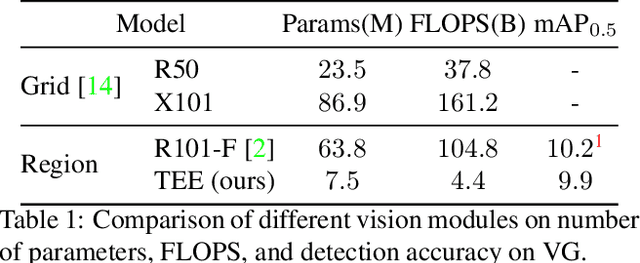
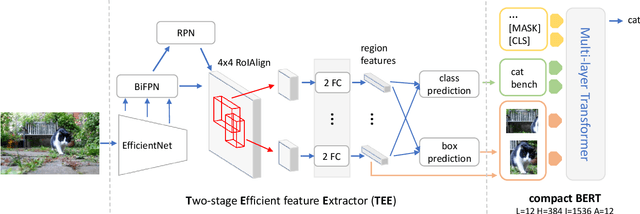
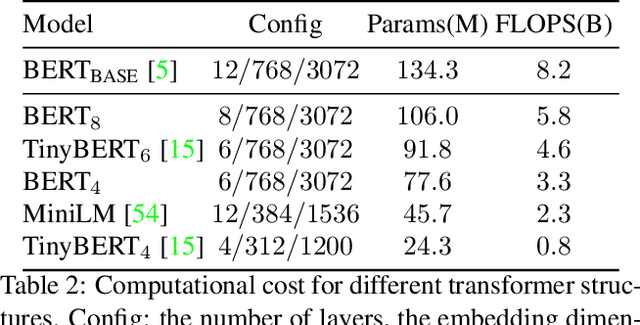
Recent vision-language (VL) studies have shown remarkable progress by learning generic representations from massive image-text pairs with transformer models and then fine-tuning on downstream VL tasks. While existing research has been focused on achieving high accuracy with large pre-trained models, building a lightweight model is of great value in practice but is less explored. In this paper, we propose a smaller and faster VL model, MiniVLM, which can be finetuned with good performance on various downstream tasks like its larger counterpart. MiniVLM consists of two modules, a vision feature extractor and a transformer-based vision-language fusion module. We design a Two-stage Efficient feature Extractor (TEE), inspired by the one-stage EfficientDet network, to significantly reduce the time cost of visual feature extraction by $95\%$, compared to a baseline model. We adopt the MiniLM structure to reduce the computation cost of the transformer module after comparing different compact BERT models. In addition, we improve the MiniVLM pre-training by adding $7M$ Open Images data, which are pseudo-labeled by a state-of-the-art captioning model. We also pre-train with high-quality image tags obtained from a strong tagging model to enhance cross-modality alignment. The large models are used offline without adding any overhead in fine-tuning and inference. With the above design choices, our MiniVLM reduces the model size by $73\%$ and the inference time cost by $94\%$ while being able to retain $94-97\%$ of the accuracy on multiple VL tasks. We hope that MiniVLM helps ease the use of the state-of-the-art VL research for on-the-edge applications.