 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Dialog Policy Learning without Adversarial Learning in the Loop
Paper and Code
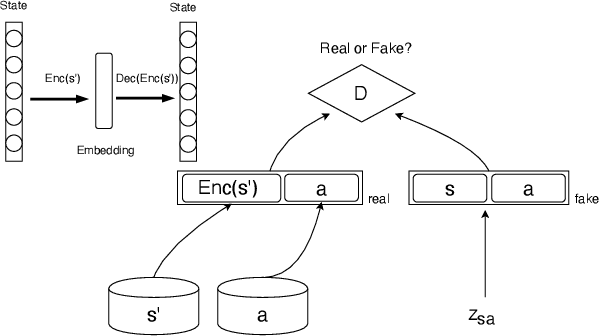
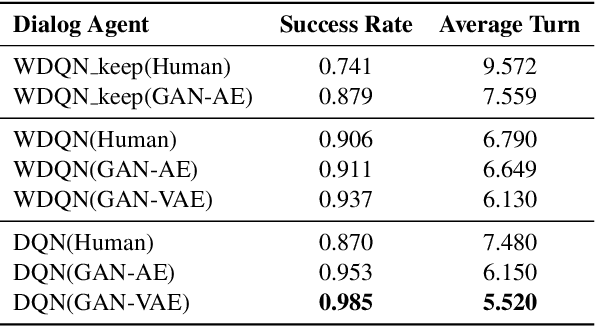
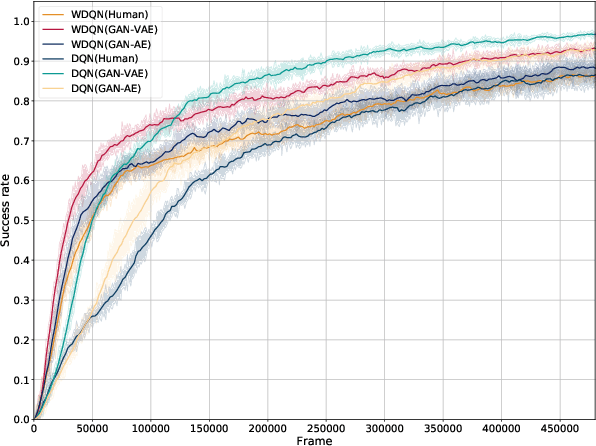
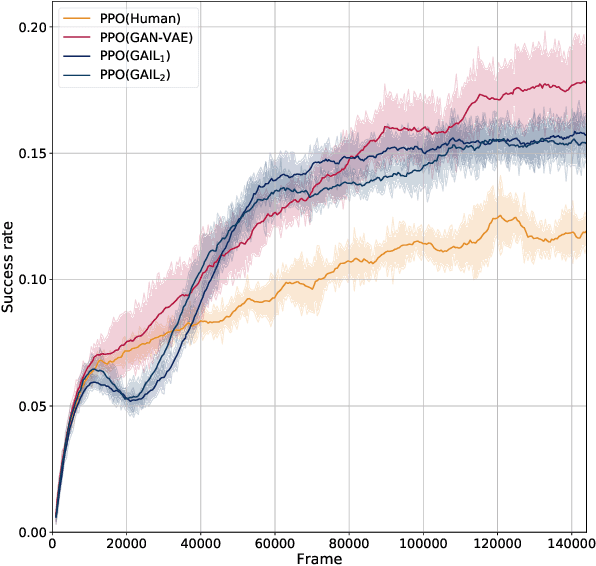
Reinforcement-based training methods have emerged as the most popular choice to train an efficient and effective dialog policy. However, these methods are suffering from sparse and unstable reward signals usually returned from the user simulator at the end of the dialog. Besides, the reward signal is manually designed by human experts which requires domain knowledge. A number of adversarial learning methods have been proposed to learn the reward function together with the dialog policy. However, to alternatively update the dialog policy and the reward model on the fly, the algorithms to update the dialog policy are limited to policy gradient-based algorithms, such as REINFORCE and PPO. Besides, the alternative training of the dialog agent and the reward model can easily get stuck in local optimum or result in mode collapse. In this work, we propose to decompose the previous adversarial training into two different steps. We first train the discriminator with an auxiliary dialog generator and then incorporate this trained reward model to a common reinforcement learning method to train a high-quality dialog agent. This approach is applicable to both on-policy and off-policy reinforcement learning methods. By conducting several experiments, we show the proposed methods can achieve remarkable task success and its potential to transfer knowledge from existing domains to a new domain.