 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJian Sun
YOLOX: Exceeding YOLO Series in 2021
Aug 06, 2021
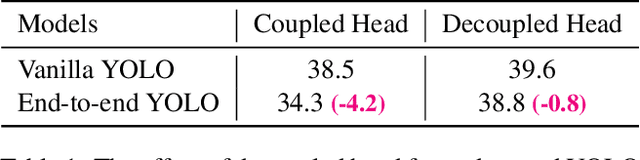
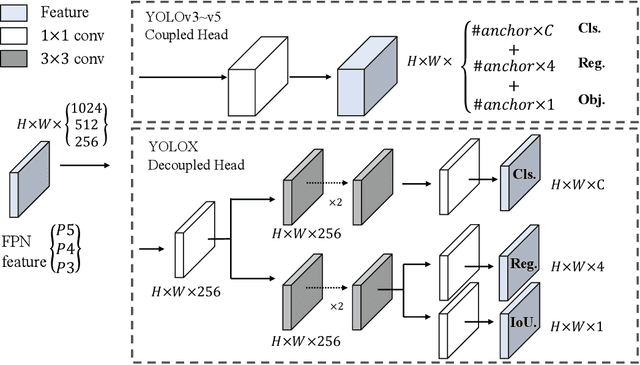
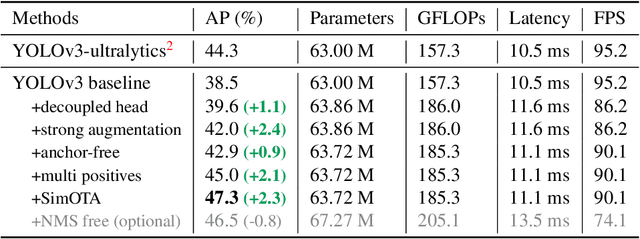
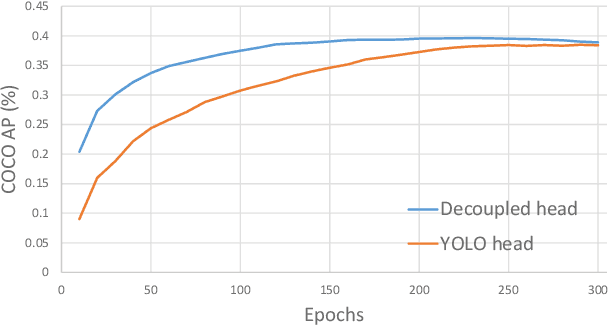
In this report, we present some experienced improvements to YOLO series, forming a new high-performance detector -- YOLOX. We switch the YOLO detector to an anchor-free manner and conduct other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA to achieve state-of-the-art results across a large scale range of models: For YOLO-Nano with only 0.91M parameters and 1.08G FLOPs, we get 25.3% AP on COCO, surpassing NanoDet by 1.8% AP; for YOLOv3, one of the most widely used detectors in industry, we boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP; for YOLOX-L with roughly the same amount of parameters as YOLOv4-CSP, YOLOv5-L, we achieve 50.0% AP on COCO at a speed of 68.9 FPS on Tesla V100, exceeding YOLOv5-L by 1.8% AP. Further, we won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model. We hope this report can provide useful experience for developers and researchers in practical scenes, and we also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported. Source code is at https://github.com/Megvii-BaseDetection/YOLOX.
Workshop on Autonomous Driving at CVPR 2021: Technical Report for Streaming Perception Challenge
Jul 27, 2021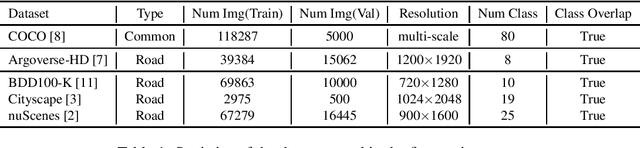
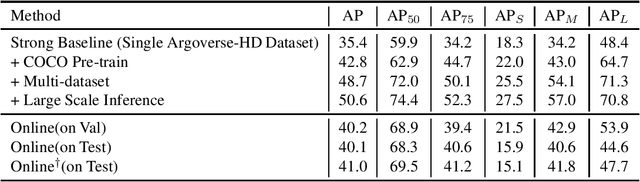
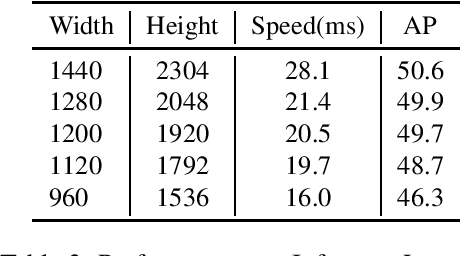
In this report, we introduce our real-time 2D object detection system for the realistic autonomous driving scenario. Our detector is built on a newly designed YOLO model, called YOLOX. On the Argoverse-HD dataset, our system achieves 41.0 streaming AP, which surpassed second place by 7.8/6.1 on detection-only track/fully track, respectively. Moreover, equipped with TensorRT, our model achieves the 30FPS inference speed with a high-resolution input size (e.g., 1440-2304). Code and models will be available at https://github.com/Megvii-BaseDetection/YOLOX
A Unified Hyper-GAN Model for Unpaired Multi-contrast MR Image Translation
Jul 26, 2021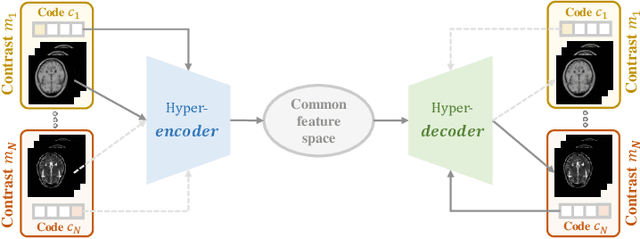
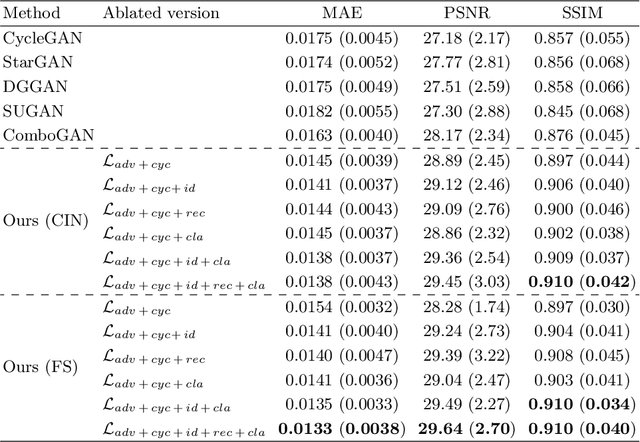
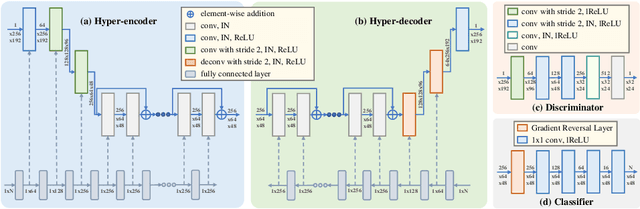
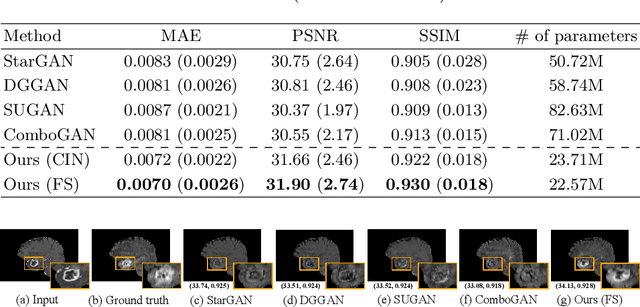
Cross-contrast image translation is an important task for completing missing contrasts in clinical diagnosis. However, most existing methods learn separate translator for each pair of contrasts, which is inefficient due to many possible contrast pairs in real scenarios. In this work, we propose a unified Hyper-GAN model for effectively and efficiently translating between different contrast pairs. Hyper-GAN consists of a pair of hyper-encoder and hyper-decoder to first map from the source contrast to a common feature space, and then further map to the target contrast image. To facilitate the translation between different contrast pairs, contrast-modulators are designed to tune the hyper-encoder and hyper-decoder adaptive to different contrasts. We also design a common space loss to enforce that multi-contrast images of a subject share a common feature space, implicitly modeling the shared underlying anatomical structures. Experiments on two datasets of IXI and BraTS 2019 show that our Hyper-GAN achieves state-of-the-art results in both accuracy and efficiency, e.g., improving more than 1.47 and 1.09 dB in PSNR on two datasets with less than half the amount of parameters.
Ill-posed Surface Emissivity Retrieval from Multi-Geometry Hyperspectral Images using a Hybrid Deep Neural Network
Jul 17, 2021
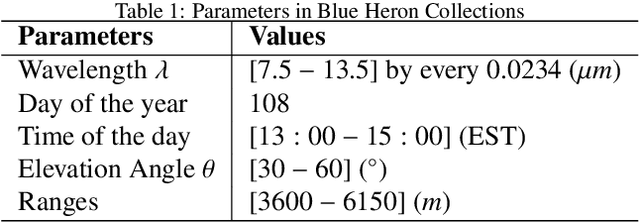
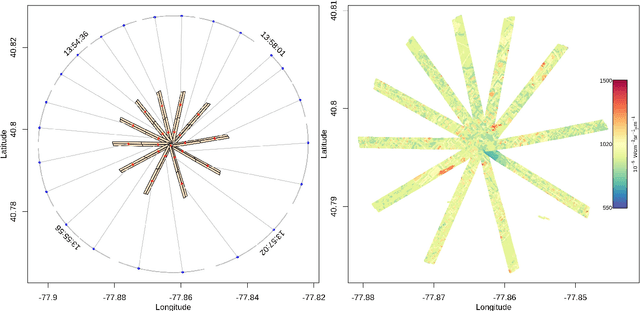
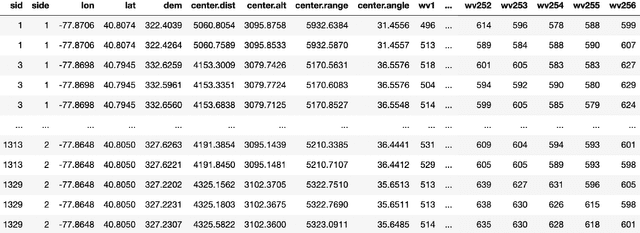
Atmospheric correction is a fundamental task in remote sensing because observations are taken either of the atmosphere or looking through the atmosphere. Atmospheric correction errors can significantly alter the spectral signature of the observations, and lead to invalid classifications or target detection. This is even more crucial when working with hyperspectral data, where a precise measurement of spectral properties is required. State-of-the-art physics-based atmospheric correction approaches require extensive prior knowledge about sensor characteristics, collection geometry, and environmental characteristics of the scene being collected. These approaches are computationally expensive, prone to inaccuracy due to lack of sufficient environmental and collection information, and often impossible for real-time applications. In this paper, a geometry-dependent hybrid neural network is proposed for automatic atmospheric correction using multi-scan hyperspectral data collected from different geometries. The proposed network can characterize the atmosphere without any additional meteorological data. A grid-search method is also proposed to solve the temperature emissivity separation problem. Results show that the proposed network has the capacity to accurately characterize the atmosphere and estimate target emissivity spectra with a Mean Absolute Error (MAE) under 0.02 for 29 different materials. This solution can lead to accurate atmospheric correction to improve target detection for real time applications.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021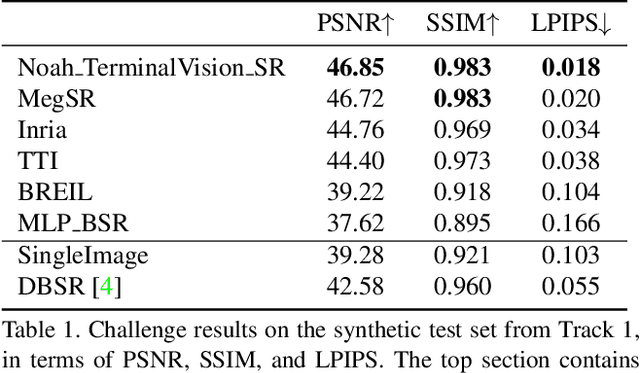

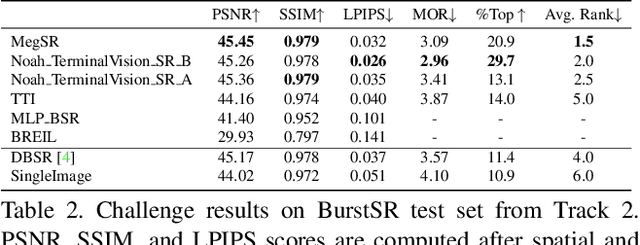

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
Preview, Attend and Review: Schema-Aware Curriculum Learning for Multi-Domain Dialog State Tracking
Jun 01, 2021
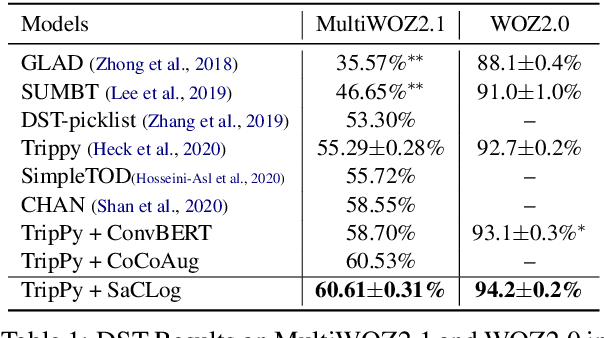
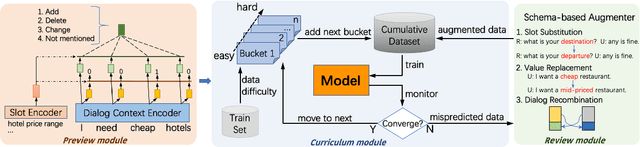
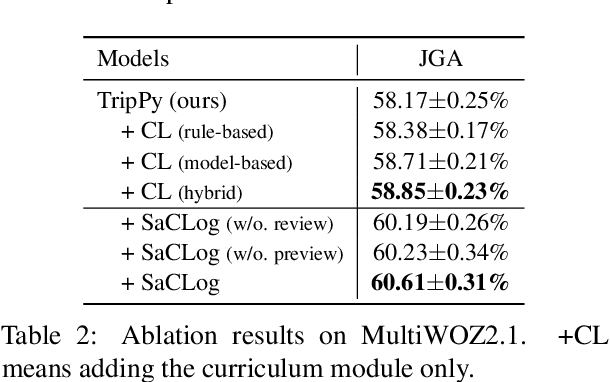
Existing dialog state tracking (DST) models are trained with dialog data in a random order, neglecting rich structural information in a dataset. In this paper, we propose to use curriculum learning (CL) to better leverage both the curriculum structure and schema structure for task-oriented dialogs. Specifically, we propose a model-agnostic framework called Schema-aware Curriculum Learning for Dialog State Tracking (SaCLog), which consists of a preview module that pre-trains a DST model with schema information, a curriculum module that optimizes the model with CL, and a review module that augments mispredicted data to reinforce the CL training. We show that our proposed approach improves DST performance over both a transformer-based and RNN-based DST model (TripPy and TRADE) and achieves new state-of-the-art results on WOZ2.0 and MultiWOZ2.1.
ADNet: Attention-guided Deformable Convolutional Network for High Dynamic Range Imaging
May 22, 2021
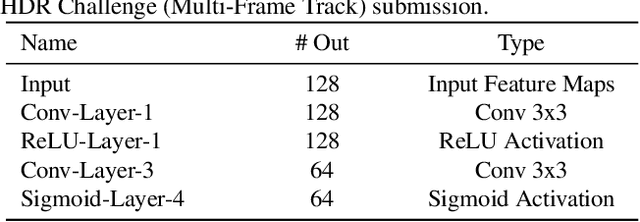
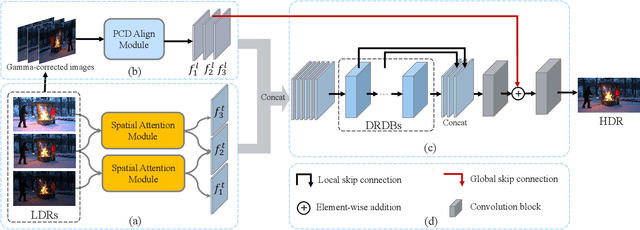
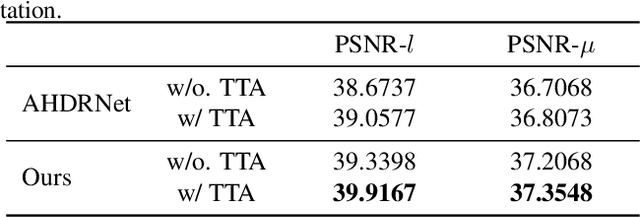
In this paper, we present an attention-guided deformable convolutional network for hand-held multi-frame high dynamic range (HDR) imaging, namely ADNet. This problem comprises two intractable challenges of how to handle saturation and noise properly and how to tackle misalignments caused by object motion or camera jittering. To address the former, we adopt a spatial attention module to adaptively select the most appropriate regions of various exposure low dynamic range (LDR) images for fusion. For the latter one, we propose to align the gamma-corrected images in the feature-level with a Pyramid, Cascading and Deformable (PCD) alignment module. The proposed ADNet shows state-of-the-art performance compared with previous methods, achieving a PSNR-$l$ of 39.4471 and a PSNR-$\mu$ of 37.6359 in NTIRE 2021 Multi-Frame HDR Challenge.
Generalized Few-Shot Object Detection without Forgetting
May 20, 2021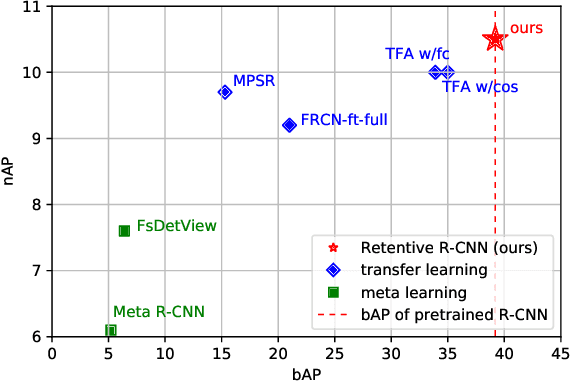
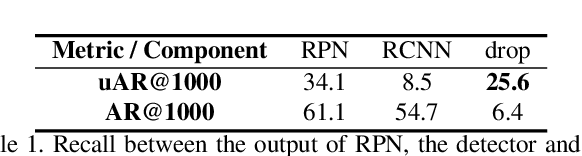
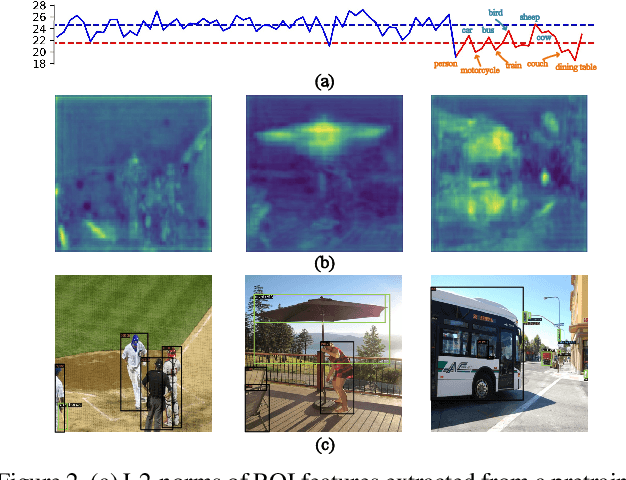

Recently few-shot object detection is widely adopted to deal with data-limited situations. While most previous works merely focus on the performance on few-shot categories, we claim that detecting all classes is crucial as test samples may contain any instances in realistic applications, which requires the few-shot detector to learn new concepts without forgetting. Through analysis on transfer learning based methods, some neglected but beneficial properties are utilized to design a simple yet effective few-shot detector, Retentive R-CNN. It consists of Bias-Balanced RPN to debias the pretrained RPN and Re-detector to find few-shot class objects without forgetting previous knowledge. Extensive experiments on few-shot detection benchmarks show that Retentive R-CNN significantly outperforms state-of-the-art methods on overall performance among all settings as it can achieve competitive results on few-shot classes and does not degrade the base class performance at all. Our approach has demonstrated that the long desired never-forgetting learner is available in object detection.
Fast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

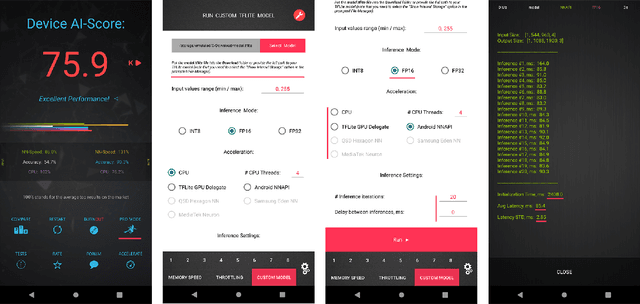
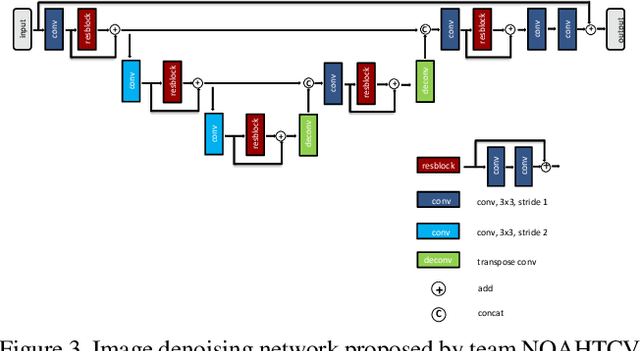
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.