 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvReal: Adversarial Patch Generation Framework with Application to Adversarial Safety Evaluation of Object Detection Systems
May 22, 2025



Autonomous vehicles are typical complex intelligent systems with artificial intelligence at their core. However, perception methods based on deep learning are extremely vulnerable to adversarial samples, resulting in safety accidents. How to generate effective adversarial examples in the physical world and evaluate object detection systems is a huge challenge. In this study, we propose a unified joint adversarial training framework for both 2D and 3D samples to address the challenges of intra-class diversity and environmental variations in real-world scenarios. Building upon this framework, we introduce an adversarial sample reality enhancement approach that incorporates non-rigid surface modeling and a realistic 3D matching mechanism. We compare with 5 advanced adversarial patches and evaluate their attack performance on 8 object detecotrs, including single-stage, two-stage, and transformer-based models. Extensive experiment results in digital and physical environments demonstrate that the adversarial textures generated by our method can effectively mislead the target detection model. Moreover, proposed method demonstrates excellent robustness and transferability under multi-angle attacks, varying lighting conditions, and different distance in the physical world. The demo video and code can be obtained at https://github.com/Huangyh98/AdvReal.git.
Tree-Based Hard Attention with Self-Motivation for Large Language Models
Feb 14, 2024



While large language models (LLMs) excel at understanding and generating plain text, they are not specifically tailored to handle hierarchical text structures. Extracting the task-desired property from their natural language responses typically necessitates additional processing steps. In fact, selectively comprehending the hierarchical structure of large-scale text is pivotal to understanding its substance. Aligning LLMs more closely with the classification or regression values of specific task through prompting also remains challenging. To this end, we propose a novel framework called Tree-Based Hard Attention with Self-Motivation for Large Language Models (TEAROOM). TEAROOM incorporates a tree-based hard attention mechanism for LLMs to process hierarchically structured text inputs. By leveraging prompting, it enables a frozen LLM to selectively focus on relevant leaves in relation to the root, generating a tailored symbolic representation of their relationship. Moreover, TEAROOM comprises a self-motivation strategy for another LLM equipped with a trainable adapter and a linear layer. The selected symbolic outcomes are integrated into another prompt, along with the predictive value of the task. We iteratively feed output values back into the prompt, enabling the trainable LLM to progressively approximate the golden truth. TEAROOM outperforms existing state-of-the-art methods in experimental evaluations across three benchmark datasets, showing its effectiveness in estimating task-specific properties. Through comprehensive experiments and analysis, we have validated the ability of TEAROOM to gradually approach the underlying golden truth through multiple inferences.
Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection
Jul 19, 2022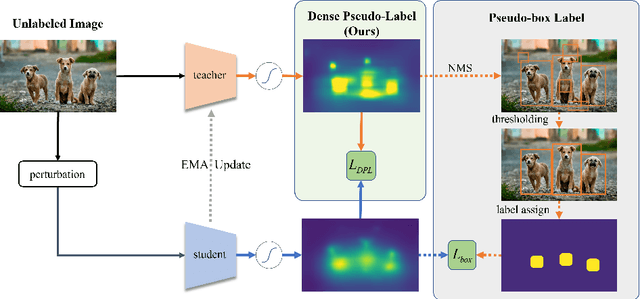
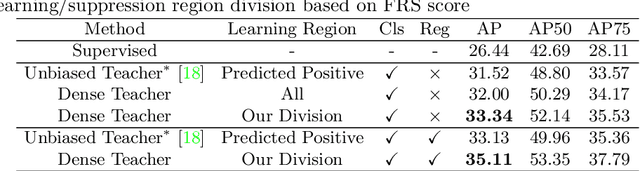
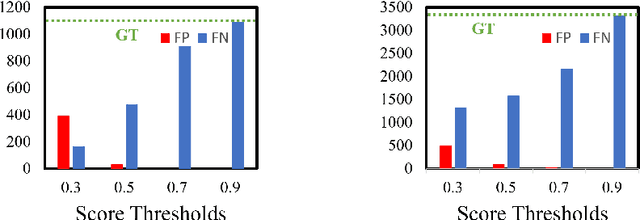
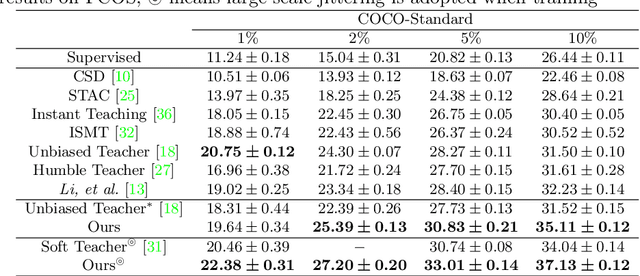
To date, the most powerful semi-supervised object detectors (SS-OD) are based on pseudo-boxes, which need a sequence of post-processing with fine-tuned hyper-parameters. In this work, we propose replacing the sparse pseudo-boxes with the dense prediction as a united and straightforward form of pseudo-label. Compared to the pseudo-boxes, our Dense Pseudo-Label (DPL) does not involve any post-processing method, thus retaining richer information. We also introduce a region selection technique to highlight the key information while suppressing the noise carried by dense labels. We name our proposed SS-OD algorithm that leverages the DPL as Dense Teacher. On COCO and VOC, Dense Teacher shows superior performance under various settings compared with the pseudo-box-based methods.