 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridge the Gap between Language models and Tabular Understanding
Feb 16, 2023Table pretrain-then-finetune paradigm has been proposed and employed at a rapid pace after the success of pre-training in the natural language domain. Despite the promising findings in tabular pre-trained language models (TPLMs), there is an input gap between pre-training and fine-tuning phases. For instance, TPLMs jointly pre-trained with table and text input could be effective for tasks also with table-text joint input like table question answering, but it may fail for tasks with only tables or text as input such as table retrieval. To this end, we propose UTP, an approach that dynamically supports three types of multi-modal inputs: table-text, table, and text. Specifically, UTP is pre-trained with two strategies: (1) We first utilize a universal mask language modeling objective on each kind of input, enforcing the model to adapt various inputs. (2) We then present Cross-Modal Contrastive Regularization (CMCR), which utilizes contrastive learning to encourage the consistency between table-text cross-modality representations via unsupervised instance-wise training signals during pre-training. By these means, the resulting model not only bridges the input gap between pre-training and fine-tuning but also advances in the alignment of table and text. Extensive results show UTP achieves superior results on uni-modal input tasks (e.g., table retrieval) and cross-modal input tasks (e.g., table question answering).
Knowledge-enhanced Neural Machine Reasoning: A Review
Feb 07, 2023


Knowledge-enhanced neural machine reasoning has garnered significant attention as a cutting-edge yet challenging research area with numerous practical applications. Over the past few years, plenty of studies have leveraged various forms of external knowledge to augment the reasoning capabilities of deep models, tackling challenges such as effective knowledge integration, implicit knowledge mining, and problems of tractability and optimization. However, there is a dearth of a comprehensive technical review of the existing knowledge-enhanced reasoning techniques across the diverse range of application domains. This survey provides an in-depth examination of recent advancements in the field, introducing a novel taxonomy that categorizes existing knowledge-enhanced methods into two primary categories and four subcategories. We systematically discuss these methods and highlight their correlations, strengths, and limitations. Finally, we elucidate the current application domains and provide insight into promising prospects for future research.
LazyGNN: Large-Scale Graph Neural Networks via Lazy Propagation
Feb 03, 2023Recent works have demonstrated the benefits of capturing long-distance dependency in graphs by deeper graph neural networks (GNNs). But deeper GNNs suffer from the long-lasting scalability challenge due to the neighborhood explosion problem in large-scale graphs. In this work, we propose to capture long-distance dependency in graphs by shallower models instead of deeper models, which leads to a much more efficient model, LazyGNN, for graph representation learning. Moreover, we demonstrate that LazyGNN is compatible with existing scalable approaches (such as sampling methods) for further accelerations through the development of mini-batch LazyGNN. Comprehensive experiments demonstrate its superior prediction performance and scalability on large-scale benchmarks. LazyGNN also achieves state-of-art performance on the OGB leaderboard.
Revisiting Graph Contrastive Learning from the Perspective of Graph Spectrum
Oct 05, 2022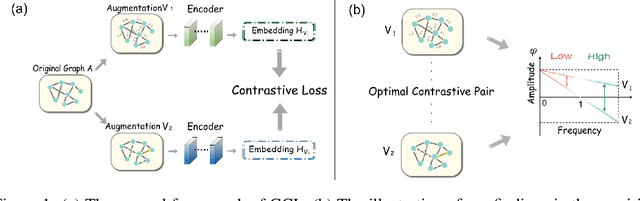

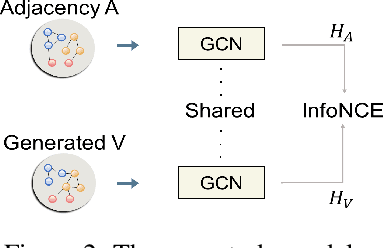
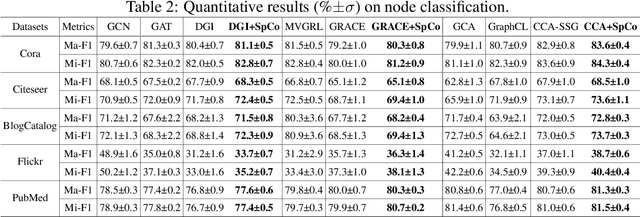
Graph Contrastive Learning (GCL), learning the node representations by augmenting graphs, has attracted considerable attentions. Despite the proliferation of various graph augmentation strategies, some fundamental questions still remain unclear: what information is essentially encoded into the learned representations by GCL? Are there some general graph augmentation rules behind different augmentations? If so, what are they and what insights can they bring? In this paper, we answer these questions by establishing the connection between GCL and graph spectrum. By an experimental investigation in spectral domain, we firstly find the General grAph augMEntation (GAME) rule for GCL, i.e., the difference of the high-frequency parts between two augmented graphs should be larger than that of low-frequency parts. This rule reveals the fundamental principle to revisit the current graph augmentations and design new effective graph augmentations. Then we theoretically prove that GCL is able to learn the invariance information by contrastive invariance theorem, together with our GAME rule, for the first time, we uncover that the learned representations by GCL essentially encode the low-frequency information, which explains why GCL works. Guided by this rule, we propose a spectral graph contrastive learning module (SpCo), which is a general and GCL-friendly plug-in. We combine it with different existing GCL models, and extensive experiments well demonstrate that it can further improve the performances of a wide variety of different GCL methods.
Knowledge-Injected Federated Learning
Aug 16, 2022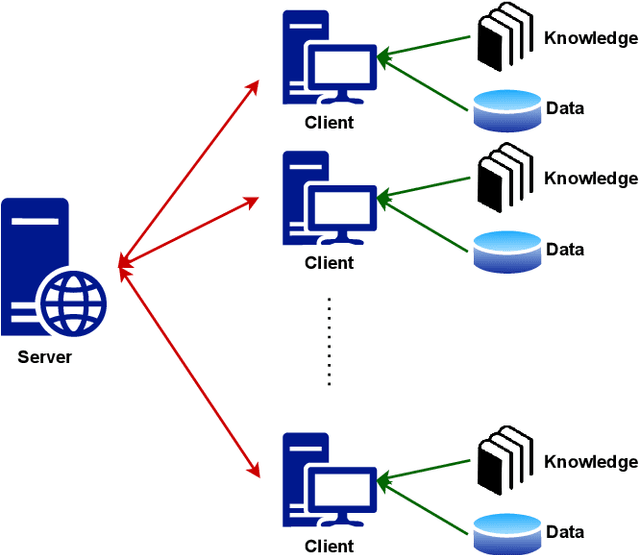

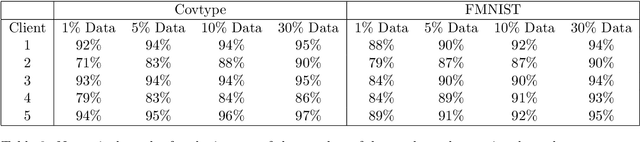
Federated learning is an emerging technique for training models from decentralized data sets. In many applications, data owners participating in the federated learning system hold not only the data but also a set of domain knowledge. Such knowledge includes human know-how and craftsmanship that can be extremely helpful to the federated learning task. In this work, we propose a federated learning framework that allows the injection of participants' domain knowledge, where the key idea is to refine the global model with knowledge locally. The scenario we consider is motivated by a real industry-level application, and we demonstrate the effectiveness of our approach to this application.
Revealing Unfair Models by Mining Interpretable Evidence
Jul 12, 2022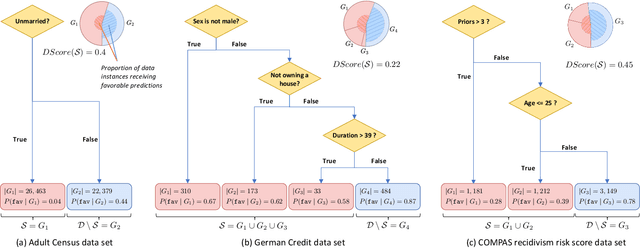
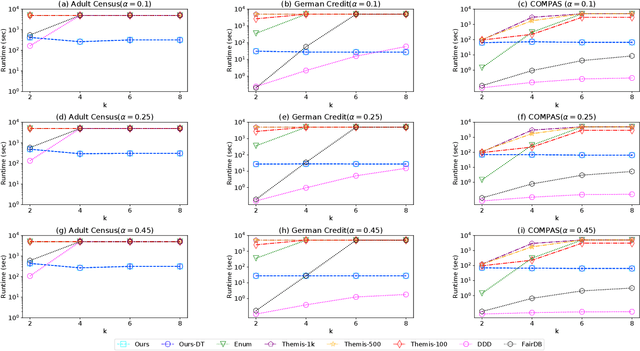
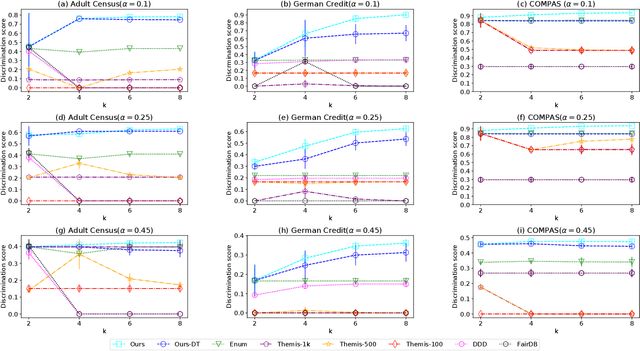
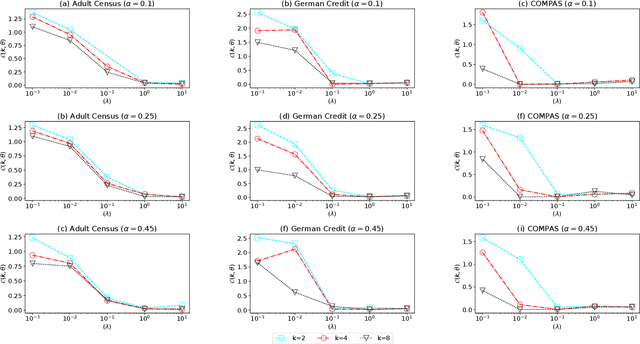
The popularity of machine learning has increased the risk of unfair models getting deployed in high-stake applications, such as justice system, drug/vaccination design, and medical diagnosis. Although there are effective methods to train fair models from scratch, how to automatically reveal and explain the unfairness of a trained model remains a challenging task. Revealing unfairness of machine learning models in interpretable fashion is a critical step towards fair and trustworthy AI. In this paper, we systematically tackle the novel task of revealing unfair models by mining interpretable evidence (RUMIE). The key idea is to find solid evidence in the form of a group of data instances discriminated most by the model. To make the evidence interpretable, we also find a set of human-understandable key attributes and decision rules that characterize the discriminated data instances and distinguish them from the other non-discriminated data. As demonstrated by extensive experiments on many real-world data sets, our method finds highly interpretable and solid evidence to effectively reveal the unfairness of trained models. Moreover, it is much more scalable than all of the baseline methods.
Bridging the Gap Between Indexing and Retrieval for Differentiable Search Index with Query Generation
Jun 21, 2022
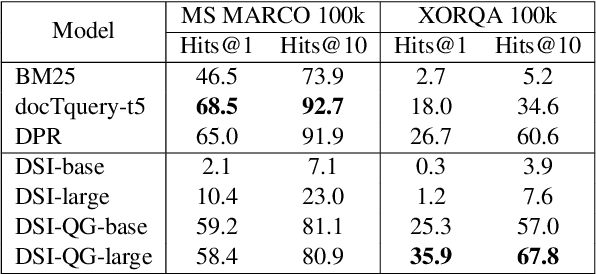
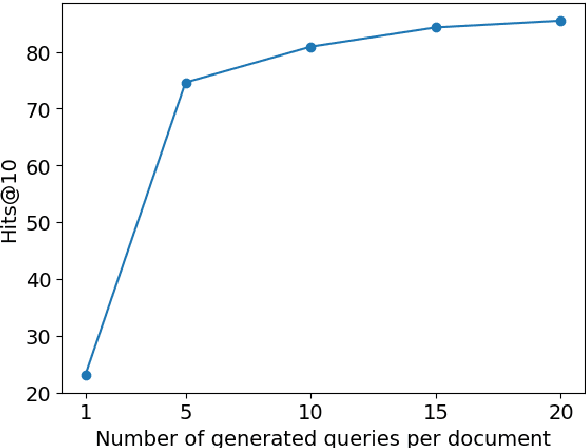
The Differentiable Search Index (DSI) is a new, emerging paradigm for information retrieval. Unlike traditional retrieval architectures where index and retrieval are two different and separate components, DSI uses a single transformer model to perform both indexing and retrieval. In this paper, we identify and tackle an important issue of current DSI models: the data distribution mismatch that occurs between the DSI indexing and retrieval processes. Specifically, we argue that, at indexing, current DSI methods learn to build connections between long document texts and their identifies, but then at retrieval, short query texts are provided to DSI models to perform the retrieval of the document identifiers. This problem is further exacerbated when using DSI for cross-lingual retrieval, where document text and query text are in different languages. To address this fundamental problem of current DSI models we propose a simple yet effective indexing framework for DSI called DSI-QG. In DSI-QG, documents are represented by a number of relevant queries generated by a query generation model at indexing time. This allows DSI models to connect a document identifier to a set of query texts when indexing, hence mitigating data distribution mismatches present between the indexing and the retrieval phases. Empirical results on popular mono-lingual and cross-lingual passage retrieval benchmark datasets show that DSI-QG significantly outperforms the original DSI model.
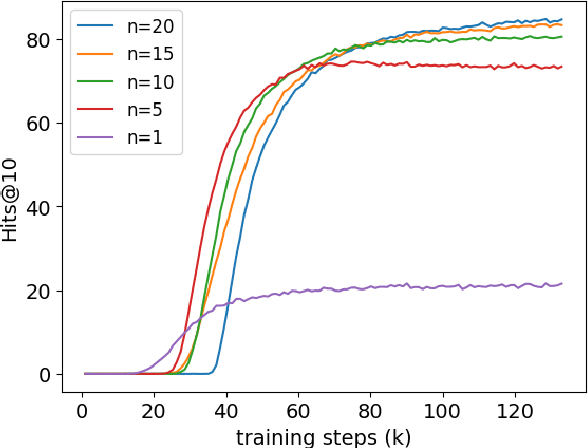
Communication-Efficient Robust Federated Learning with Noisy Labels
Jun 11, 2022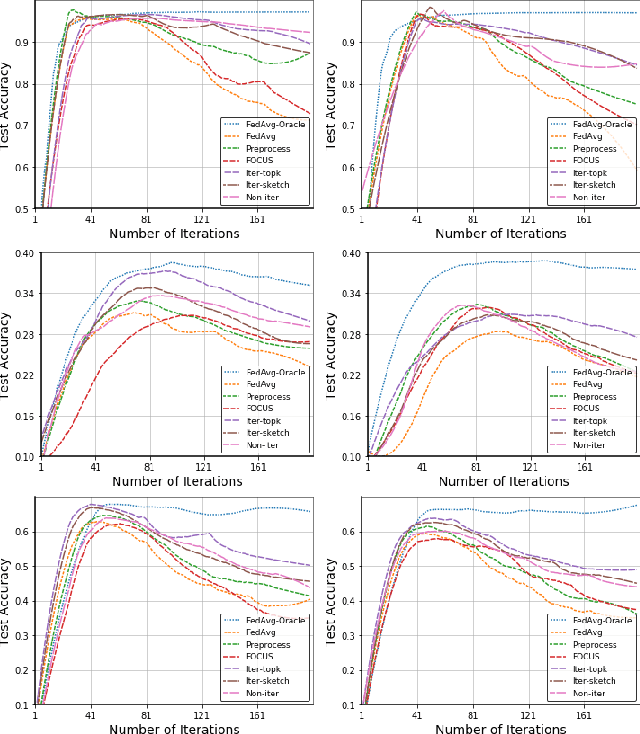
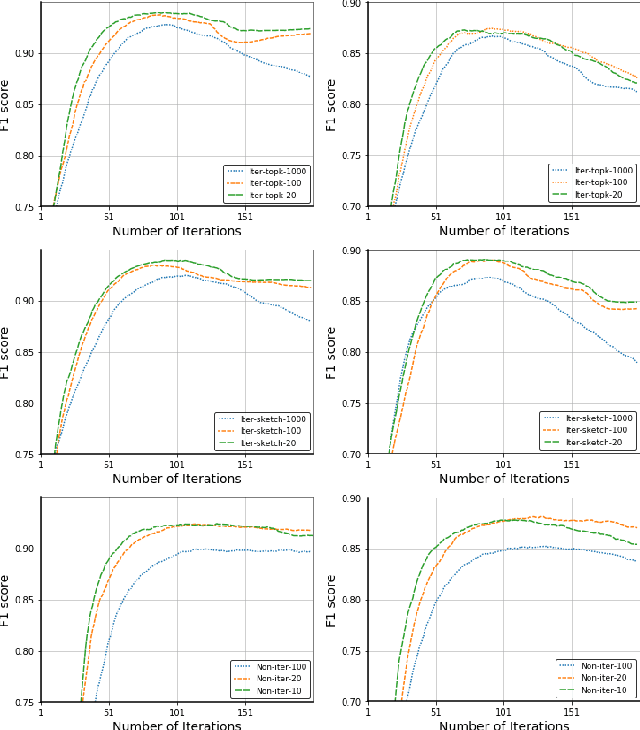
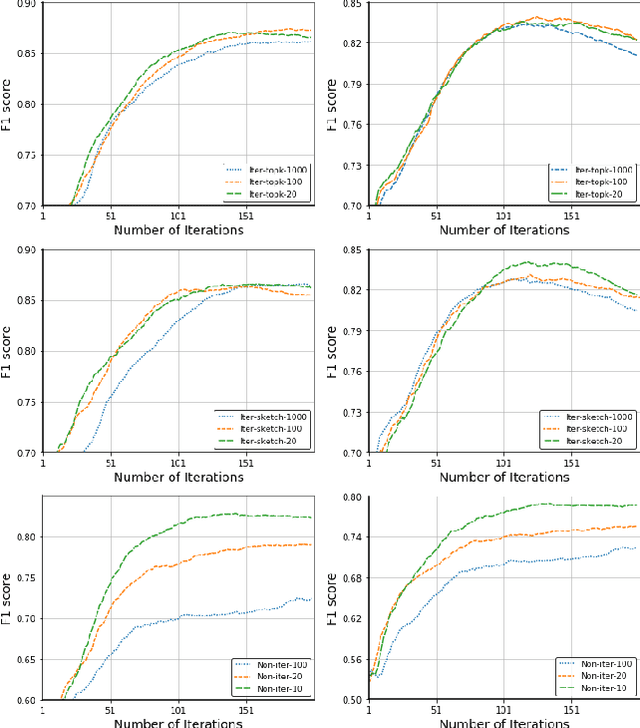
Federated learning (FL) is a promising privacy-preserving machine learning paradigm over distributed located data. In FL, the data is kept locally by each user. This protects the user privacy, but also makes the server difficult to verify data quality, especially if the data are correctly labeled. Training with corrupted labels is harmful to the federated learning task; however, little attention has been paid to FL in the case of label noise. In this paper, we focus on this problem and propose a learning-based reweighting approach to mitigate the effect of noisy labels in FL. More precisely, we tuned a weight for each training sample such that the learned model has optimal generalization performance over a validation set. More formally, the process can be formulated as a Federated Bilevel Optimization problem. Bilevel optimization problem is a type of optimization problem with two levels of entangled problems. The non-distributed bilevel problems have witnessed notable progress recently with new efficient algorithms. However, solving bilevel optimization problems under the Federated Learning setting is under-investigated. We identify that the high communication cost in hypergradient evaluation is the major bottleneck. So we propose \textit{Comm-FedBiO} to solve the general Federated Bilevel Optimization problems; more specifically, we propose two communication-efficient subroutines to estimate the hypergradient. Convergence analysis of the proposed algorithms is also provided. Finally, we apply the proposed algorithms to solve the noisy label problem. Our approach has shown superior performance on several real-world datasets compared to various baselines.
Multi-Behavior Sequential Recommendation with Temporal Graph Transformer
Jun 06, 2022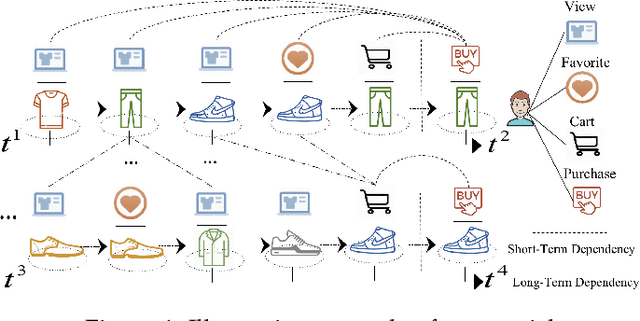

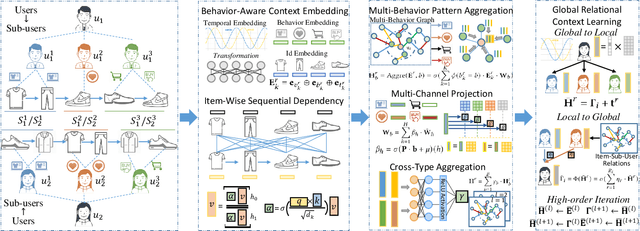

Modeling time-evolving preferences of users with their sequential item interactions, has attracted increasing attention in many online applications. Hence, sequential recommender systems have been developed to learn the dynamic user interests from the historical interactions for suggesting items. However, the interaction pattern encoding functions in most existing sequential recommender systems have focused on single type of user-item interactions. In many real-life online platforms, user-item interactive behaviors are often multi-typed (e.g., click, add-to-favorite, purchase) with complex cross-type behavior inter-dependencies. Learning from informative representations of users and items based on their multi-typed interaction data, is of great importance to accurately characterize the time-evolving user preference. In this work, we tackle the dynamic user-item relation learning with the awareness of multi-behavior interactive patterns. Towards this end, we propose a new Temporal Graph Transformer (TGT) recommendation framework to jointly capture dynamic short-term and long-range user-item interactive patterns, by exploring the evolving correlations across different types of behaviors. The new TGT method endows the sequential recommendation architecture to distill dedicated knowledge for type-specific behavior relational context and the implicit behavior dependencies. Experiments on the real-world datasets indicate that our method TGT consistently outperforms various state-of-the-art recommendation methods. Our model implementation codes are available at https://github.com/akaxlh/TGT.
Trustworthy Graph Neural Networks: Aspects, Methods and Trends
May 16, 2022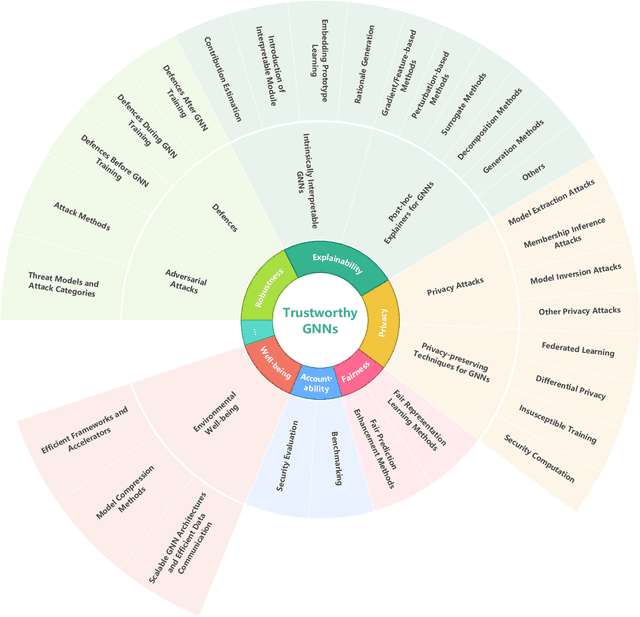
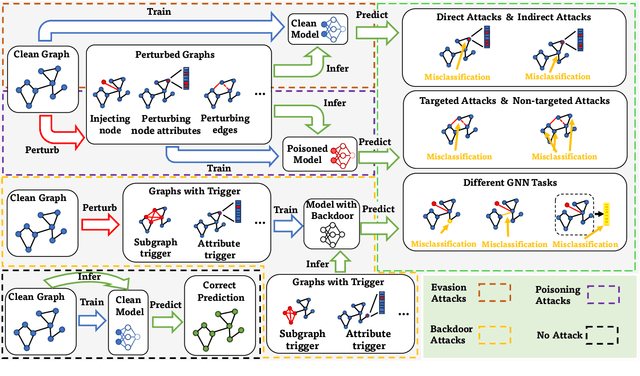
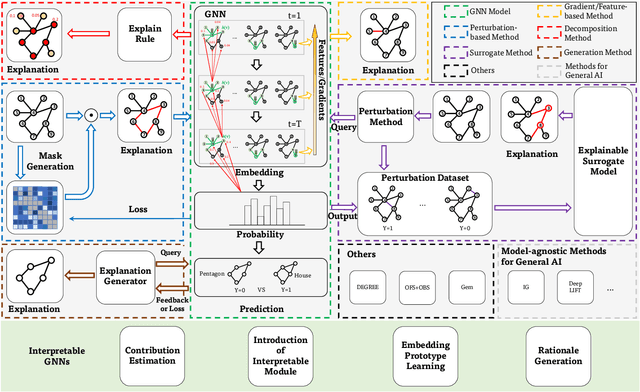
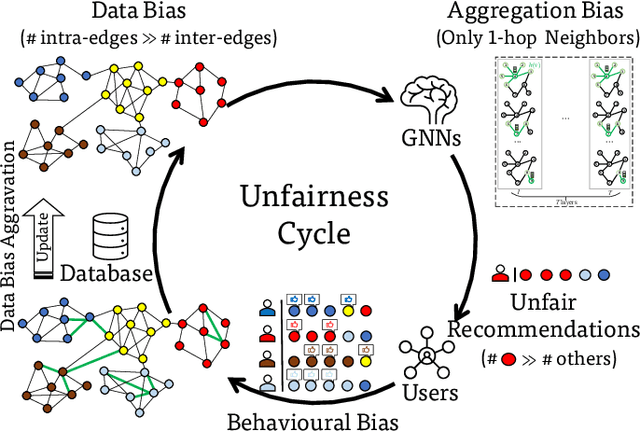
Graph neural networks (GNNs) have emerged as a series of competent graph learning methods for diverse real-world scenarios, ranging from daily applications like recommendation systems and question answering to cutting-edge technologies such as drug discovery in life sciences and n-body simulation in astrophysics. However, task performance is not the only requirement for GNNs. Performance-oriented GNNs have exhibited potential adverse effects like vulnerability to adversarial attacks, unexplainable discrimination against disadvantaged groups, or excessive resource consumption in edge computing environments. To avoid these unintentional harms, it is necessary to build competent GNNs characterised by trustworthiness. To this end, we propose a comprehensive roadmap to build trustworthy GNNs from the view of the various computing technologies involved. In this survey, we introduce basic concepts and comprehensively summarise existing efforts for trustworthy GNNs from six aspects, including robustness, explainability, privacy, fairness, accountability, and environmental well-being. Additionally, we highlight the intricate cross-aspect relations between the above six aspects of trustworthy GNNs. Finally, we present a thorough overview of trending directions for facilitating the research and industrialisation of trustworthy GNNs.