 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Over-smoothing for Unsupervised Sentence Representation
May 09, 2023



Currently, learning better unsupervised sentence representations is the pursuit of many natural language processing communities. Lots of approaches based on pre-trained language models (PLMs) and contrastive learning have achieved promising results on this task. Experimentally, we observe that the over-smoothing problem reduces the capacity of these powerful PLMs, leading to sub-optimal sentence representations. In this paper, we present a Simple method named Self-Contrastive Learning (SSCL) to alleviate this issue, which samples negatives from PLMs intermediate layers, improving the quality of the sentence representation. Our proposed method is quite simple and can be easily extended to various state-of-the-art models for performance boosting, which can be seen as a plug-and-play contrastive framework for learning unsupervised sentence representation. Extensive results prove that SSCL brings the superior performance improvements of different strong baselines (e.g., BERT and SimCSE) on Semantic Textual Similarity and Transfer datasets. Our codes are available at https://github.com/nuochenpku/SSCL.
* 13 pages
Bridge the Gap between Language models and Tabular Understanding
Feb 16, 2023Table pretrain-then-finetune paradigm has been proposed and employed at a rapid pace after the success of pre-training in the natural language domain. Despite the promising findings in tabular pre-trained language models (TPLMs), there is an input gap between pre-training and fine-tuning phases. For instance, TPLMs jointly pre-trained with table and text input could be effective for tasks also with table-text joint input like table question answering, but it may fail for tasks with only tables or text as input such as table retrieval. To this end, we propose UTP, an approach that dynamically supports three types of multi-modal inputs: table-text, table, and text. Specifically, UTP is pre-trained with two strategies: (1) We first utilize a universal mask language modeling objective on each kind of input, enforcing the model to adapt various inputs. (2) We then present Cross-Modal Contrastive Regularization (CMCR), which utilizes contrastive learning to encourage the consistency between table-text cross-modality representations via unsupervised instance-wise training signals during pre-training. By these means, the resulting model not only bridges the input gap between pre-training and fine-tuning but also advances in the alignment of table and text. Extensive results show UTP achieves superior results on uni-modal input tasks (e.g., table retrieval) and cross-modal input tasks (e.g., table question answering).
Thousand to One: Semantic Prior Modeling for Conceptual Coding
Mar 16, 2021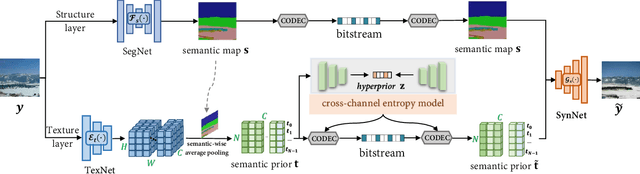
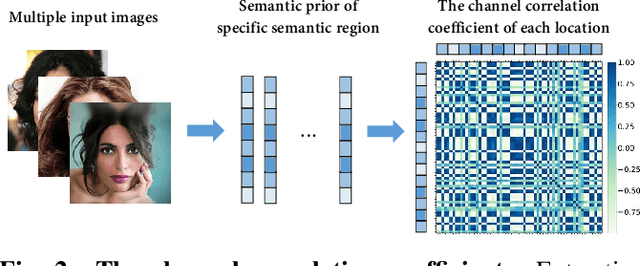

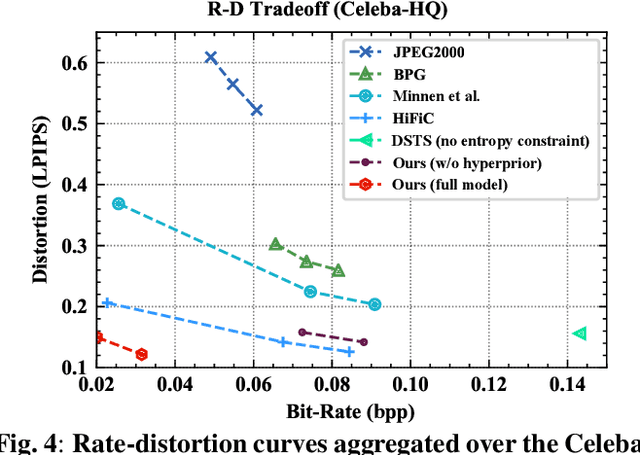
Conceptual coding has been an emerging research topic recently, which encodes natural images into disentangled conceptual representations for compression. However, the compression performance of the existing methods is still sub-optimal due to the lack of comprehensive consideration of rate constraint and reconstruction quality. To this end, we propose a novel end-to-end semantic prior modeling-based conceptual coding scheme towards extremely low bitrate image compression, which leverages semantic-wise deep representations as a unified prior for entropy estimation and texture synthesis. Specifically, we employ semantic segmentation maps as structural guidance for extracting deep semantic prior, which provides fine-grained texture distribution modeling for better detail construction and higher flexibility in subsequent high-level vision tasks. Moreover, a cross-channel entropy model is proposed to further exploit the inter-channel correlation of the spatially independent semantic prior, leading to more accurate entropy estimation for rate-constrained training. The proposed scheme achieves an ultra-high 1000x compression ratio, while still enjoying high visual reconstruction quality and versatility towards visual processing and analysis tasks.
Conceptual Compression via Deep Structure and Texture Synthesis
Nov 10, 2020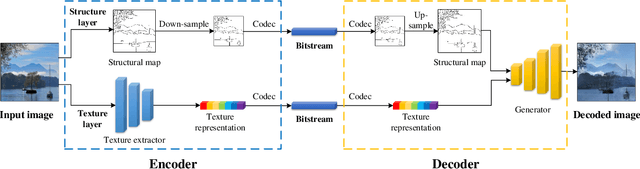
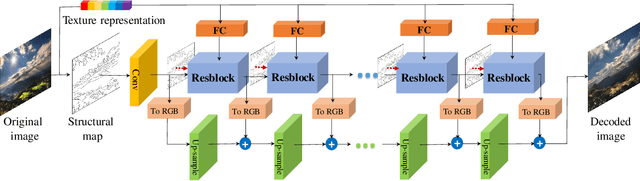
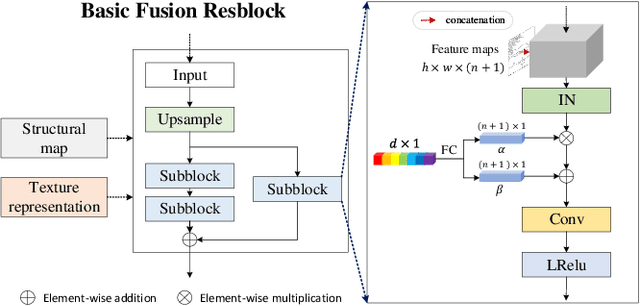
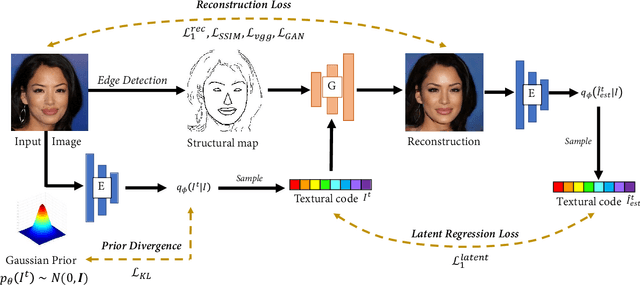
Existing compression methods typically focus on the removal of signal-level redundancies, while the potential and versatility of decomposing visual data into compact conceptual components still lack further study. To this end, we propose a novel conceptual compression framework that encodes visual data into compact structure and texture representations, then decodes in a deep synthesis fashion, aiming to achieve better visual reconstruction quality, flexible content manipulation, and potential support for various vision tasks. In particular, we propose to compress images by a dual-layered model consisting of two complementary visual features: 1) structure layer represented by structural maps and 2) texture layer characterized by low-dimensional deep representations. At the encoder side, the structural maps and texture representations are individually extracted and compressed, generating the compact, interpretable, inter-operable bitstreams. During the decoding stage, a hierarchical fusion GAN (HF-GAN) is proposed to learn the synthesis paradigm where the textures are rendered into the decoded structural maps, leading to high-quality reconstruction with remarkable visual realism. Extensive experiments on diverse images have demonstrated the superiority of our framework with lower bitrates, higher reconstruction quality, and increased versatility towards visual analysis and content manipulation tasks.