 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogDual: Enhancing Dual Cognition of LLMs via Reinforcement Learning with Implicit Rule-Based Rewards
Jul 23, 2025



Role-Playing Language Agents (RPLAs) have emerged as a significant application direction for Large Language Models (LLMs). Existing approaches typically rely on prompt engineering or supervised fine-tuning to enable models to imitate character behaviors in specific scenarios, but often neglect the underlying \emph{cognitive} mechanisms driving these behaviors. Inspired by cognitive psychology, we introduce \textbf{CogDual}, a novel RPLA adopting a \textit{cognize-then-respond } reasoning paradigm. By jointly modeling external situational awareness and internal self-awareness, CogDual generates responses with improved character consistency and contextual alignment. To further optimize the performance, we employ reinforcement learning with two general-purpose reward schemes designed for open-domain text generation. Extensive experiments on the CoSER benchmark, as well as Cross-MR and LifeChoice, demonstrate that CogDual consistently outperforms existing baselines and generalizes effectively across diverse role-playing tasks.
Frequency-responsive RCS characteristics and scaling implications for ISAC development
Jul 16, 2025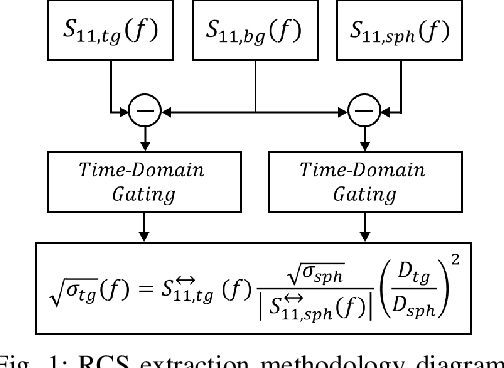
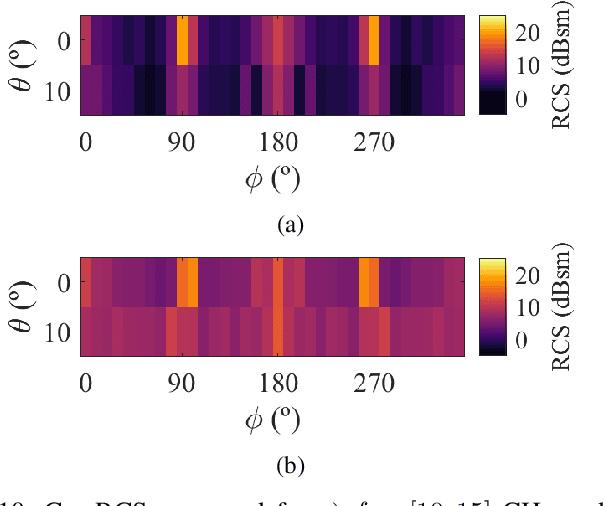
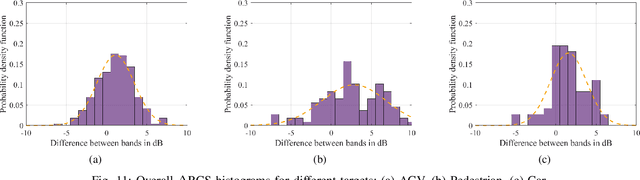
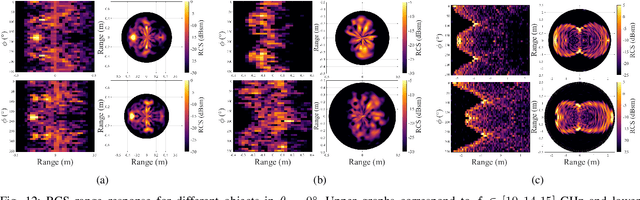
This paper presents an investigation on the Radar Cross-Section (RCS) of various targets, with the objective of analysing how RCS properties vary with frequency. Targets such as an Automated Guided Vehicle (AGV), a pedestrian, and a full-scale car were measured in the frequency bands referred to in industry standards as FR2 and FR3. Measurements were taken in diverse environments, indoors and outdoors, to ensure comprehensive scenario coverage. The methodology employed in RCS extraction performs background subtraction, followed by time-domain gating to isolate the influence of the target. This analysis compares the RCS values and how the points of greatest contribution are distributed across different bands based on the range response of the RCS. Analysis of the results demonstrated how RCS values change with frequency and target shape, providing insights into the electromagnetic behaviour of these targets. Key findings highlight how much scaling RCS values based on frequency and geometry is complex and varies among different types of materials and shapes. These insights are instrumental for advancing sensing systems and enhancing 3GPP channel models, particularly for Integrated Sensing and Communications (ISAC) techniques proposed for 6G standards.
* 6 pages, 12 figures, 3 tables. Accepted for publication at the 2024 IEEE Global Communications Conference (GLOBECOM), WS-02: Workshop on Propagation Channel Models and Evaluation Methodologies for 6G
Dissecting the Impact of Mobile DVFS Governors on LLM Inference Performance and Energy Efficiency
Jul 02, 2025Large Language Models (LLMs) are increasingly being integrated into various applications and services running on billions of mobile devices. However, deploying LLMs on resource-limited mobile devices faces a significant challenge due to their high demand for computation, memory, and ultimately energy. While current LLM frameworks for mobile use three power-hungry components-CPU, GPU, and Memory-even when running primarily-GPU LLM models, optimized DVFS governors for CPU, GPU, and memory featured in modern mobile devices operate independently and are oblivious of each other. Motivated by the above observation, in this work, we first measure the energy-efficiency of a SOTA LLM framework consisting of various LLM models on mobile phones which showed the triplet mobile governors result in up to 40.4% longer prefilling and decoding latency compared to optimal combinations of CPU, GPU, and memory frequencies with the same energy consumption for sampled prefill and decode lengths. Second, we conduct an in-depth measurement study to uncover how the intricate interplay (or lack of) among the mobile governors cause the above inefficiency in LLM inference. Finally, based on these insights, we design FUSE - a unified energy-aware governor for optimizing the energy efficiency of LLM inference on mobile devices. Our evaluation using a ShareGPT dataset shows FUSE reduces the time-to-first-token and time-per-output-token latencies by 7.0%-16.9% and 25.4%-36.8% on average with the same energy-per-token for various mobile LLM models.
SlotPi: Physics-informed Object-centric Reasoning Models
Jun 12, 2025Understanding and reasoning about dynamics governed by physical laws through visual observation, akin to human capabilities in the real world, poses significant challenges. Currently, object-centric dynamic simulation methods, which emulate human behavior, have achieved notable progress but overlook two critical aspects: 1) the integration of physical knowledge into models. Humans gain physical insights by observing the world and apply this knowledge to accurately reason about various dynamic scenarios; 2) the validation of model adaptability across diverse scenarios. Real-world dynamics, especially those involving fluids and objects, demand models that not only capture object interactions but also simulate fluid flow characteristics. To address these gaps, we introduce SlotPi, a slot-based physics-informed object-centric reasoning model. SlotPi integrates a physical module based on Hamiltonian principles with a spatio-temporal prediction module for dynamic forecasting. Our experiments highlight the model's strengths in tasks such as prediction and Visual Question Answering (VQA) on benchmark and fluid datasets. Furthermore, we have created a real-world dataset encompassing object interactions, fluid dynamics, and fluid-object interactions, on which we validated our model's capabilities. The model's robust performance across all datasets underscores its strong adaptability, laying a foundation for developing more advanced world models.
CogniBench: A Legal-inspired Framework and Dataset for Assessing Cognitive Faithfulness of Large Language Models
May 28, 2025Faithfulness hallucination are claims generated by a Large Language Model (LLM) not supported by contexts provided to the LLM. Lacking assessment standard, existing benchmarks only contain "factual statements" that rephrase source materials without marking "cognitive statements" that make inference from the given context, making the consistency evaluation and optimization of cognitive statements difficult. Inspired by how an evidence is assessed in the legislative domain, we design a rigorous framework to assess different levels of faithfulness of cognitive statements and create a benchmark dataset where we reveal insightful statistics. We design an annotation pipeline to create larger benchmarks for different LLMs automatically, and the resulting larger-scale CogniBench-L dataset can be used to train accurate cognitive hallucination detection model. We release our model and dataset at: https://github.com/FUTUREEEEEE/CogniBench
Effective climate policies for major emission reductions of ozone precursors: Global evidence from two decades
May 20, 2025Despite policymakers deploying various tools to mitigate emissions of ozone (O\textsubscript{3}) precursors, such as nitrogen oxides (NO\textsubscript{x}), carbon monoxide (CO), and volatile organic compounds (VOCs), the effectiveness of policy combinations remains uncertain. We employ an integrated framework that couples structural break detection with machine learning to pinpoint effective interventions across the building, electricity, industrial, and transport sectors, identifying treatment effects as abrupt changes without prior assumptions about policy treatment assignment and timing. Applied to two decades of global O\textsubscript{3} precursor emissions data, we detect 78, 77, and 78 structural breaks for NO\textsubscript{x}, CO, and VOCs, corresponding to cumulative emission reductions of 0.96-0.97 Gt, 2.84-2.88 Gt, and 0.47-0.48 Gt, respectively. Sector-level analysis shows that electricity sector structural policies cut NO\textsubscript{x} by up to 32.4\%, while in buildings, developed countries combined adoption subsidies with carbon taxes to achieve 42.7\% CO reductions and developing countries used financing plus fuel taxes to secure 52.3\%. VOCs abatement peaked at 38.5\% when fossil-fuel subsidy reforms were paired with financial incentives. Finally, hybrid strategies merging non-price measures (subsidies, bans, mandates) with pricing instruments delivered up to an additional 10\% co-benefit. These findings guide the sequencing and complementarity of context-specific policy portfolios for O\textsubscript{3} precursor mitigation.
Swin DiT: Diffusion Transformer using Pseudo Shifted Windows
May 19, 2025Diffusion Transformers (DiTs) achieve remarkable performance within the domain of image generation through the incorporation of the transformer architecture. Conventionally, DiTs are constructed by stacking serial isotropic global information modeling transformers, which face significant computational cost when processing high-resolution images. We empirically analyze that latent space image generation does not exhibit a strong dependence on global information as traditionally assumed. Most of the layers in the model demonstrate redundancy in global computation. In addition, conventional attention mechanisms exhibit low-frequency inertia issues. To address these issues, we propose \textbf{P}seudo \textbf{S}hifted \textbf{W}indow \textbf{A}ttention (PSWA), which fundamentally mitigates global model redundancy. PSWA achieves intermediate global-local information interaction through window attention, while employing a high-frequency bridging branch to simulate shifted window operations, supplementing appropriate global and high-frequency information. Furthermore, we propose the Progressive Coverage Channel Allocation(PCCA) strategy that captures high-order attention similarity without additional computational cost. Building upon all of them, we propose a series of Pseudo \textbf{S}hifted \textbf{Win}dow DiTs (\textbf{Swin DiT}), accompanied by extensive experiments demonstrating their superior performance. For example, our proposed Swin-DiT-L achieves a 54%$\uparrow$ FID improvement over DiT-XL/2 while requiring less computational. https://github.com/wujiafu007/Swin-DiT
Navigating the Alpha Jungle: An LLM-Powered MCTS Framework for Formulaic Factor Mining
May 16, 2025Alpha factor mining is pivotal in quantitative investment for identifying predictive signals from complex financial data. While traditional formulaic alpha mining relies on human expertise, contemporary automated methods, such as those based on genetic programming or reinforcement learning, often suffer from search inefficiency or yield poorly interpretable alpha factors. This paper introduces a novel framework that integrates Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS) to overcome these limitations. Our approach leverages the LLM's instruction-following and reasoning capability to iteratively generate and refine symbolic alpha formulas within an MCTS-driven exploration. A key innovation is the guidance of MCTS exploration by rich, quantitative feedback from financial backtesting of each candidate factor, enabling efficient navigation of the vast search space. Furthermore, a frequent subtree avoidance mechanism is introduced to bolster search efficiency and alpha factor performance. Experimental results on real-world stock market data demonstrate that our LLM-based framework outperforms existing methods by mining alphas with superior predictive accuracy, trading performance, and improved interpretability, while offering a more efficient solution for formulaic alpha mining.
Generative Discovery of Partial Differential Equations by Learning from Math Handbooks
May 09, 2025Data driven discovery of partial differential equations (PDEs) is a promising approach for uncovering the underlying laws governing complex systems. However, purely data driven techniques face the dilemma of balancing search space with optimization efficiency. This study introduces a knowledge guided approach that incorporates existing PDEs documented in a mathematical handbook to facilitate the discovery process. These PDEs are encoded as sentence like structures composed of operators and basic terms, and used to train a generative model, called EqGPT, which enables the generation of free form PDEs. A loop of generation evaluation optimization is constructed to autonomously identify the most suitable PDE. Experimental results demonstrate that this framework can recover a variety of PDE forms with high accuracy and computational efficiency, particularly in cases involving complex temporal derivatives or intricate spatial terms, which are often beyond the reach of conventional methods. The approach also exhibits generalizability to irregular spatial domains and higher dimensional settings. Notably, it succeeds in discovering a previously unreported PDE governing strongly nonlinear surface gravity waves propagating toward breaking, based on real world experimental data, highlighting its applicability to practical scenarios and its potential to support scientific discovery.
VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
May 06, 2025With the growing requirement for natural human-computer interaction, speech-based systems receive increasing attention as speech is one of the most common forms of daily communication. However, the existing speech models still experience high latency when generating the first audio token during streaming, which poses a significant bottleneck for deployment. To address this issue, we propose VITA-Audio, an end-to-end large speech model with fast audio-text token generation. Specifically, we introduce a lightweight Multiple Cross-modal Token Prediction (MCTP) module that efficiently generates multiple audio tokens within a single model forward pass, which not only accelerates the inference but also significantly reduces the latency for generating the first audio in streaming scenarios. In addition, a four-stage progressive training strategy is explored to achieve model acceleration with minimal loss of speech quality. To our knowledge, VITA-Audio is the first multi-modal large language model capable of generating audio output during the first forward pass, enabling real-time conversational capabilities with minimal latency. VITA-Audio is fully reproducible and is trained on open-source data only. Experimental results demonstrate that our model achieves an inference speedup of 3~5x at the 7B parameter scale, but also significantly outperforms open-source models of similar model size on multiple benchmarks for automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA) tasks.