 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForge-and-Quench: Enhancing Image Generation for Higher Fidelity in Unified Multimodal Models
Jan 08, 2026Integrating image generation and understanding into a single framework has become a pivotal goal in the multimodal domain. However, how understanding can effectively assist generation has not been fully explored. Unlike previous works that focus on leveraging reasoning abilities and world knowledge from understanding models, this paper introduces a novel perspective: leveraging understanding to enhance the fidelity and detail richness of generated images. To this end, we propose Forge-and-Quench, a new unified framework that puts this principle into practice. In the generation process of our framework, an MLLM first reasons over the entire conversational context, including text instructions, to produce an enhanced text instruction. This refined instruction is then mapped to a virtual visual representation, termed the Bridge Feature, via a novel Bridge Adapter. This feature acts as a crucial link, forging insights from the understanding model to quench and refine the generation process. It is subsequently injected into the T2I backbone as a visual guidance signal, alongside the enhanced text instruction that replaces the original input. To validate this paradigm, we conduct comprehensive studies on the design of the Bridge Feature and Bridge Adapter. Our framework demonstrates exceptional extensibility and flexibility, enabling efficient migration across different MLLM and T2I models with significant savings in training overhead, all without compromising the MLLM's inherent multimodal understanding capabilities. Experiments show that Forge-and-Quench significantly improves image fidelity and detail across multiple models, while also maintaining instruction-following accuracy and enhancing world knowledge application. Models and codes are available at https://github.com/YanbingZeng/Forge-and-Quench.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Beyond Darkness: Thermal-Supervised 3D Gaussian Splatting for Low-Light Novel View Synthesis
Nov 17, 2025Under extremely low-light conditions, novel view synthesis (NVS) faces severe degradation in terms of geometry, color consistency, and radiometric stability. Standard 3D Gaussian Splatting (3DGS) pipelines fail when applied directly to underexposed inputs, as independent enhancement across views causes illumination inconsistencies and geometric distortion. To address this, we present DTGS, a unified framework that tightly couples Retinex-inspired illumination decomposition with thermal-guided 3D Gaussian Splatting for illumination-invariant reconstruction. Unlike prior approaches that treat enhancement as a pre-processing step, DTGS performs joint optimization across enhancement, geometry, and thermal supervision through a cyclic enhancement-reconstruction mechanism. A thermal supervisory branch stabilizes both color restoration and geometry learning by dynamically balancing enhancement, structural, and thermal losses. Moreover, a Retinex-based decomposition module embedded within the 3DGS loop provides physically interpretable reflectance-illumination separation, ensuring consistent color and texture across viewpoints. To evaluate our method, we construct RGBT-LOW, a new multi-view low-light thermal dataset capturing severe illumination degradation. Extensive experiments show that DTGS significantly outperforms existing low-light enhancement and 3D reconstruction baselines, achieving superior radiometric consistency, geometric fidelity, and color stability under extreme illumination.
From IDs to Semantics: A Generative Framework for Cross-Domain Recommendation with Adaptive Semantic Tokenization
Nov 16, 2025Cross-domain recommendation (CDR) is crucial for improving recommendation accuracy and generalization, yet traditional methods are often hindered by the reliance on shared user/item IDs, which are unavailable in most real-world scenarios. Consequently, many efforts have focused on learning disentangled representations through multi-domain joint training to bridge the domain gaps. Recent Large Language Model (LLM)-based approaches show promise, they still face critical challenges, including: (1) the \textbf{item ID tokenization dilemma}, which leads to vocabulary explosion and fails to capture high-order collaborative knowledge; and (2) \textbf{insufficient domain-specific modeling} for the complex evolution of user interests and item semantics. To address these limitations, we propose \textbf{GenCDR}, a novel \textbf{Gen}erative \textbf{C}ross-\textbf{D}omain \textbf{R}ecommendation framework. GenCDR first employs a \textbf{Domain-adaptive Tokenization} module, which generates disentangled semantic IDs for items by dynamically routing between a universal encoder and domain-specific adapters. Symmetrically, a \textbf{Cross-domain Autoregressive Recommendation} module models user preferences by fusing universal and domain-specific interests. Finally, a \textbf{Domain-aware Prefix-tree} enables efficient and accurate generation. Extensive experiments on multiple real-world datasets demonstrate that GenCDR significantly outperforms state-of-the-art baselines. Our code is available in the supplementary materials.
Data Assessment for Embodied Intelligence
Nov 12, 2025In embodied intelligence, datasets play a pivotal role, serving as both a knowledge repository and a conduit for information transfer. The two most critical attributes of a dataset are the amount of information it provides and how easily this information can be learned by models. However, the multimodal nature of embodied data makes evaluating these properties particularly challenging. Prior work has largely focused on diversity, typically counting tasks and scenes or evaluating isolated modalities, which fails to provide a comprehensive picture of dataset diversity. On the other hand, the learnability of datasets has received little attention and is usually assessed post-hoc through model training, an expensive, time-consuming process that also lacks interpretability, offering little guidance on how to improve a dataset. In this work, we address both challenges by introducing two principled, data-driven tools. First, we construct a unified multimodal representation for each data sample and, based on it, propose diversity entropy, a continuous measure that characterizes the amount of information contained in a dataset. Second, we introduce the first interpretable, data-driven algorithm to efficiently quantify dataset learnability without training, enabling researchers to assess a dataset's learnability immediately upon its release. We validate our algorithm on both simulated and real-world embodied datasets, demonstrating that it yields faithful, actionable insights that enable researchers to jointly improve diversity and learnability. We hope this work provides a foundation for designing higher-quality datasets that advance the development of embodied intelligence.
Uncertainty-Aware Semantic Decoding for LLM-Based Sequential Recommendation
Aug 10, 2025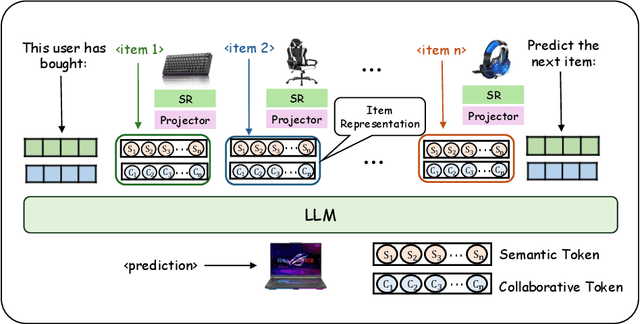
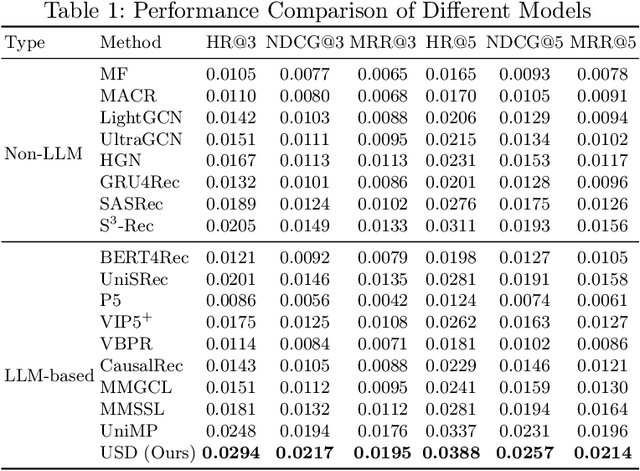
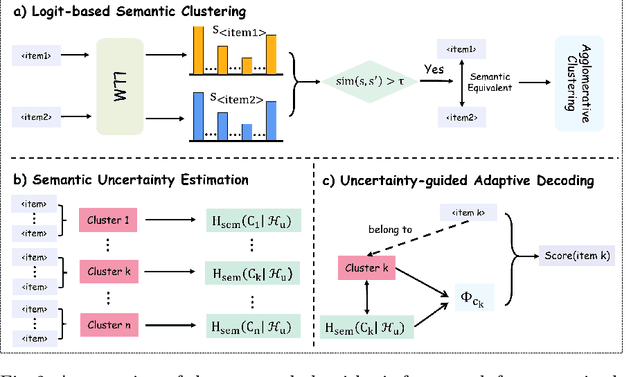

Large language models have been widely applied to sequential recommendation tasks, yet during inference, they continue to rely on decoding strategies developed for natural language processing. This creates a mismatch between text-generation objectives and recommendation next item selection objectives. This paper addresses this limitation by proposing an Uncertainty-aware Semantic Decoding (USD) framework that combines logit-based clustering with adaptive scoring to improve next-item predictions. Our approach clusters items with similar logit vectors into semantic equivalence groups, then redistributes probability mass within these clusters and computes entropy across them to control item scoring and sampling temperature during recommendation inference. Experiments on Amazon Product datasets (six domains) gains of 18.5\% in HR@3, 11.9\% in NDCG@3, and 10.8\% in MRR@3 compared to state-of-the-art baselines. Hyperparameter analysis confirms the optimal parameters among various settings, and experiments on H\&M, and Netflix datasets indicate that the framework can adapt to differing recommendation domains. The experimental results confirm that integrating semantic clustering and uncertainty assessment yields more reliable and accurate recommendations.
TableDreamer: Progressive and Weakness-guided Data Synthesis from Scratch for Table Instruction Tuning
Jun 10, 2025Despite the commendable progress of recent LLM-based data synthesis methods, they face two limitations in generating table instruction tuning data. First, they can not thoroughly explore the vast input space of table understanding tasks, leading to limited data diversity. Second, they ignore the weaknesses in table understanding ability of the target LLM and blindly pursue the increase of data quantity, resulting in suboptimal data efficiency. In this paper, we introduce a progressive and weakness-guided data synthesis framework tailored for table instruction tuning, named TableDreamer, to mitigate the above issues. Specifically, we first synthesize diverse tables and related instructions as seed data, and then perform an iterative exploration of the input space under the guidance of the newly identified weakness data, which eventually serve as the final training data for fine-tuning the target LLM. Extensive experiments on 10 tabular benchmarks demonstrate the effectiveness of the proposed framework, which boosts the average accuracy of Llama3.1-8B-instruct by 11.62% (49.07% to 60.69%) with 27K GPT-4o synthetic data and outperforms state-of-the-art data synthesis baselines which use more training data. The code and data is available at https://github.com/SpursGoZmy/TableDreamer
Exploring bidirectional bounds for minimax-training of Energy-based models
Jun 05, 2025Energy-based models (EBMs) estimate unnormalized densities in an elegant framework, but they are generally difficult to train. Recent work has linked EBMs to generative adversarial networks, by noting that they can be trained through a minimax game using a variational lower bound. To avoid the instabilities caused by minimizing a lower bound, we propose to instead work with bidirectional bounds, meaning that we maximize a lower bound and minimize an upper bound when training the EBM. We investigate four different bounds on the log-likelihood derived from different perspectives. We derive lower bounds based on the singular values of the generator Jacobian and on mutual information. To upper bound the negative log-likelihood, we consider a gradient penalty-like bound, as well as one based on diffusion processes. In all cases, we provide algorithms for evaluating the bounds. We compare the different bounds to investigate, the pros and cons of the different approaches. Finally, we demonstrate that the use of bidirectional bounds stabilizes EBM training and yields high-quality density estimation and sample generation.
* accepted to IJCV
Beyond Face Swapping: A Diffusion-Based Digital Human Benchmark for Multimodal Deepfake Detection
May 22, 2025In recent years, the rapid development of deepfake technology has given rise to an emerging and serious threat to public security: diffusion model-based digital human generation. Unlike traditional face manipulation methods, such models can generate highly realistic videos with consistency through multimodal control signals. Their flexibility and covertness pose severe challenges to existing detection strategies. To bridge this gap, we introduce DigiFakeAV, the first large-scale multimodal digital human forgery dataset based on diffusion models. Employing five latest digital human generation methods (Sonic, Hallo, etc.) and voice cloning method, we systematically produce a dataset comprising 60,000 videos (8.4 million frames), covering multiple nationalities, skin tones, genders, and real-world scenarios, significantly enhancing data diversity and realism. User studies show that the confusion rate between forged and real videos reaches 68%, and existing state-of-the-art (SOTA) detection models exhibit large drops in AUC values on DigiFakeAV, highlighting the challenge of the dataset. To address this problem, we further propose DigiShield, a detection baseline based on spatiotemporal and cross-modal fusion. By jointly modeling the 3D spatiotemporal features of videos and the semantic-acoustic features of audio, DigiShield achieves SOTA performance on both the DigiFakeAV and DF-TIMIT datasets. Experiments show that this method effectively identifies covert artifacts through fine-grained analysis of the temporal evolution of facial features in synthetic videos.
SAM-Guided Robust Representation Learning for One-Shot 3D Medical Image Segmentation
Apr 29, 2025



One-shot medical image segmentation (MIS) is crucial for medical analysis due to the burden of medical experts on manual annotation. The recent emergence of the segment anything model (SAM) has demonstrated remarkable adaptation in MIS but cannot be directly applied to one-shot medical image segmentation (MIS) due to its reliance on labor-intensive user interactions and the high computational cost. To cope with these limitations, we propose a novel SAM-guided robust representation learning framework, named RRL-MedSAM, to adapt SAM to one-shot 3D MIS, which exploits the strong generalization capabilities of the SAM encoder to learn better feature representation. We devise a dual-stage knowledge distillation (DSKD) strategy to distill general knowledge between natural and medical images from the foundation model to train a lightweight encoder, and then adopt a mutual exponential moving average (mutual-EMA) to update the weights of the general lightweight encoder and medical-specific encoder. Specifically, pseudo labels from the registration network are used to perform mutual supervision for such two encoders. Moreover, we introduce an auto-prompting (AP) segmentation decoder which adopts the mask generated from the general lightweight model as a prompt to assist the medical-specific model in boosting the final segmentation performance. Extensive experiments conducted on three public datasets, i.e., OASIS, CT-lung demonstrate that the proposed RRL-MedSAM outperforms state-of-the-art one-shot MIS methods for both segmentation and registration tasks. Especially, our lightweight encoder uses only 3\% of the parameters compared to the encoder of SAM-Base.