 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Majority: Long-tail Imitation Learning for Robotic Manipulation
Feb 06, 2026While generalist robot policies hold significant promise for learning diverse manipulation skills through imitation, their performance is often hindered by the long-tail distribution of training demonstrations. Policies learned on such data, which is heavily skewed towards a few data-rich head tasks, frequently exhibit poor generalization when confronted with the vast number of data-scarce tail tasks. In this work, we conduct a comprehensive analysis of the pervasive long-tail challenge inherent in policy learning. Our analysis begins by demonstrating the inefficacy of conventional long-tail learning strategies (e.g., re-sampling) for improving the policy's performance on tail tasks. We then uncover the underlying mechanism for this failure, revealing that data scarcity on tail tasks directly impairs the policy's spatial reasoning capability. To overcome this, we introduce Approaching-Phase Augmentation (APA), a simple yet effective scheme that transfers knowledge from data-rich head tasks to data-scarce tail tasks without requiring external demonstrations. Extensive experiments in both simulation and real-world manipulation tasks demonstrate the effectiveness of APA. Our code and demos are publicly available at: https://mldxy.github.io/Project-VLA-long-tail/.
Learning More from Less: Unlocking Internal Representations for Benchmark Compression
Feb 03, 2026The prohibitive cost of evaluating Large Language Models (LLMs) necessitates efficient alternatives to full-scale benchmarking. Prevalent approaches address this by identifying a small coreset of items to approximate full-benchmark performance. However, existing methods must estimate a reliable item profile from response patterns across many source models, which becomes statistically unstable when the source pool is small. This dependency is particularly limiting for newly released benchmarks with minimal historical evaluation data. We argue that discrete correctness labels are a lossy view of the model's decision process and fail to capture information encoded in hidden states. To address this, we introduce REPCORE, which aligns heterogeneous hidden states into a unified latent space to construct representative coresets. Using these subsets for performance extrapolation, REPCORE achieves precise estimation accuracy with as few as ten source models. Experiments on five benchmarks and over 200 models show consistent gains over output-based baselines in ranking correlation and estimation accuracy. Spectral analysis further indicates that the aligned representations contain separable components reflecting broad response tendencies and task-specific reasoning patterns.
Do Not Waste Your Rollouts: Recycling Search Experience for Efficient Test-Time Scaling
Jan 29, 2026Test-Time Scaling enhances the reasoning capabilities of Large Language Models by allocating additional inference compute to broaden the exploration of the solution space. However, existing search strategies typically treat rollouts as disposable samples, where valuable intermediate insights are effectively discarded after each trial. This systemic memorylessness leads to massive computational redundancy, as models repeatedly re-derive discovered conclusions and revisit known dead ends across extensive attempts. To bridge this gap, we propose \textbf{Recycling Search Experience (RSE)}, a self-guided, training-free strategy that turns test-time search from a series of isolated trials into a cumulative process. By actively distilling raw trajectories into a shared experience bank, RSE enables positive recycling of intermediate conclusions to shortcut redundant derivations and negative recycling of failure patterns to prune encountered dead ends. Theoretically, we provide an analysis that formalizes the efficiency gains of RSE, validating its advantage over independent sampling in solving complex reasoning tasks. Empirically, extensive experiments on HMMT24, HMMT25, IMO-Bench, and HLE show that RSE consistently outperforms strong baselines with comparable computational cost, achieving state-of-the-art scaling efficiency.
Sim-and-Human Co-training for Data-Efficient and Generalizable Robotic Manipulation
Jan 27, 2026Synthetic simulation data and real-world human data provide scalable alternatives to circumvent the prohibitive costs of robot data collection. However, these sources suffer from the sim-to-real visual gap and the human-to-robot embodiment gap, respectively, which limits the policy's generalization to real-world scenarios. In this work, we identify a natural yet underexplored complementarity between these sources: simulation offers the robot action that human data lacks, while human data provides the real-world observation that simulation struggles to render. Motivated by this insight, we present SimHum, a co-training framework to simultaneously extract kinematic prior from simulated robot actions and visual prior from real-world human observations. Based on the two complementary priors, we achieve data-efficient and generalizable robotic manipulation in real-world tasks. Empirically, SimHum outperforms the baseline by up to $\mathbf{40\%}$ under the same data collection budget, and achieves a $\mathbf{62.5\%}$ OOD success with only 80 real data, outperforming the real only baseline by $7.1\times$. Videos and additional information can be found at \href{https://kaipengfang.github.io/sim-and-human}{project website}.
RPT*: Global Planning with Probabilistic Terminals for Target Search in Complex Environments
Jan 19, 2026Routing problems such as Hamiltonian Path Problem (HPP), seeks a path to visit all the vertices in a graph while minimizing the path cost. This paper studies a variant, HPP with Probabilistic Terminals (HPP-PT), where each vertex has a probability representing the likelihood that the robot's path terminates there, and the objective is to minimize the expected path cost. HPP-PT arises in target object search, where a mobile robot must visit all candidate locations to find an object, and prior knowledge of the object's location is expressed as vertex probabilities. While routing problems have been studied for decades, few of them consider uncertainty as required in this work. The challenge lies not only in optimally ordering the vertices, as in standard HPP, but also in handling history dependency: the expected path cost depends on the order in which vertices were previously visited. This makes many existing methods inefficient or inapplicable. To address the challenge, we propose a search-based approach RPT* with solution optimality guarantees, which leverages dynamic programming in a new state space to bypass the history dependency and novel heuristics to speed up the computation. Building on RPT*, we design a Hierarchical Autonomous Target Search (HATS) system that combines RPT* with either Bayesian filtering for lifelong target search with noisy sensors, or autonomous exploration to find targets in unknown environments. Experiments in both simulation and real robot show that our approach can naturally balance between exploitation and exploration, thereby finding targets more quickly on average than baseline methods.
From Failure to Mastery: Generating Hard Samples for Tool-use Agents
Jan 04, 2026The advancement of LLM agents with tool-use capabilities requires diverse and complex training corpora. Existing data generation methods, which predominantly follow a paradigm of random sampling and shallow generation, often yield simple and homogeneous trajectories that fail to capture complex, implicit logical dependencies. To bridge this gap, we introduce HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning. Firstly, HardGen establishes a dynamic API Graph built upon agent failure cases, from which it samples to synthesize hard traces. Secondly, these traces serve as conditional priors to guide the instantiation of modular, abstract advanced tools, which are subsequently leveraged to formulate hard queries. Finally, the advanced tools and hard queries enable the generation of verifiable complex Chain-of-Thought (CoT), with a closed-loop evaluation feedback steering the continuous refinement of the process. Extensive evaluations demonstrate that a 4B parameter model trained with our curated dataset achieves superior performance compared to several leading open-source and closed-source competitors (e.g., GPT-5.2, Gemini-3-Pro and Claude-Opus-4.5). Our code, models, and dataset will be open-sourced to facilitate future research.
Error Estimate and Convergence Analysis for Data Valuation
Nov 09, 2025Data valuation quantifies data importance, but existing methods cannot ensure validity in a single training process. The neural dynamic data valuation (NDDV) method [3] addresses this limitation. Based on NDDV, we are the first to explore error estimation and convergence analysis in data valuation. Under Lipschitz and smoothness assumptions, we derive quadratic error bounds for loss differences that scale inversely with time steps and quadratically with control variations, ensuring stability. We also prove that the expected squared gradient norm for the training loss vanishes asymptotically, and that the meta loss converges sublinearly over iterations. In particular, NDDV achieves sublinear convergence.
Federated Unlearning in the Wild: Rethinking Fairness and Data Discrepancy
Oct 08, 2025Machine unlearning is critical for enforcing data deletion rights like the "right to be forgotten." As a decentralized paradigm, Federated Learning (FL) also requires unlearning, but realistic implementations face two major challenges. First, fairness in Federated Unlearning (FU) is often overlooked. Exact unlearning methods typically force all clients into costly retraining, even those uninvolved. Approximate approaches, using gradient ascent or distillation, make coarse interventions that can unfairly degrade performance for clients with only retained data. Second, most FU evaluations rely on synthetic data assumptions (IID/non-IID) that ignore real-world heterogeneity. These unrealistic benchmarks obscure the true impact of unlearning and limit the applicability of current methods. We first conduct a comprehensive benchmark of existing FU methods under realistic data heterogeneity and fairness conditions. We then propose a novel, fairness-aware FU approach, Federated Cross-Client-Constrains Unlearning (FedCCCU), to explicitly address both challenges. FedCCCU offers a practical and scalable solution for real-world FU. Experimental results show that existing methods perform poorly in realistic settings, while our approach consistently outperforms them.
FEAT: A Multi-Agent Forensic AI System with Domain-Adapted Large Language Model for Automated Cause-of-Death Analysis
Aug 11, 2025Forensic cause-of-death determination faces systemic challenges, including workforce shortages and diagnostic variability, particularly in high-volume systems like China's medicolegal infrastructure. We introduce FEAT (ForEnsic AgenT), a multi-agent AI framework that automates and standardizes death investigations through a domain-adapted large language model. FEAT's application-oriented architecture integrates: (i) a central Planner for task decomposition, (ii) specialized Local Solvers for evidence analysis, (iii) a Memory & Reflection module for iterative refinement, and (iv) a Global Solver for conclusion synthesis. The system employs tool-augmented reasoning, hierarchical retrieval-augmented generation, forensic-tuned LLMs, and human-in-the-loop feedback to ensure legal and medical validity. In evaluations across diverse Chinese case cohorts, FEAT outperformed state-of-the-art AI systems in both long-form autopsy analyses and concise cause-of-death conclusions. It demonstrated robust generalization across six geographic regions and achieved high expert concordance in blinded validations. Senior pathologists validated FEAT's outputs as comparable to those of human experts, with improved detection of subtle evidentiary nuances. To our knowledge, FEAT is the first LLM-based AI agent system dedicated to forensic medicine, offering scalable, consistent death certification while maintaining expert-level rigor. By integrating AI efficiency with human oversight, this work could advance equitable access to reliable medicolegal services while addressing critical capacity constraints in forensic systems.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025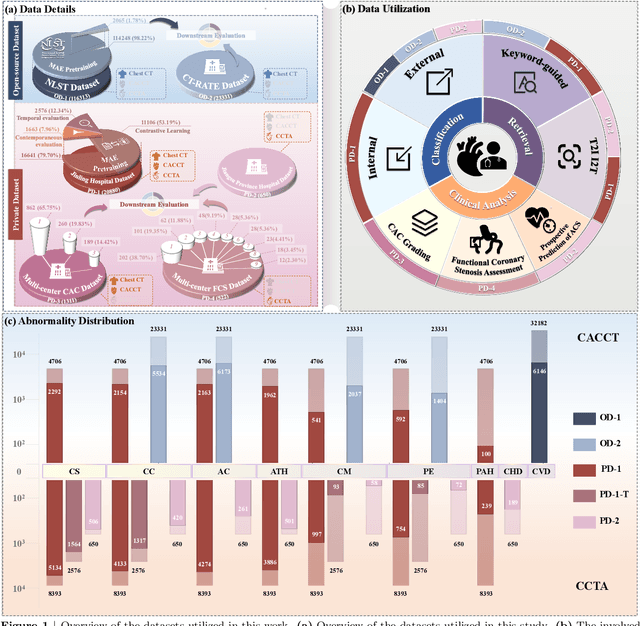
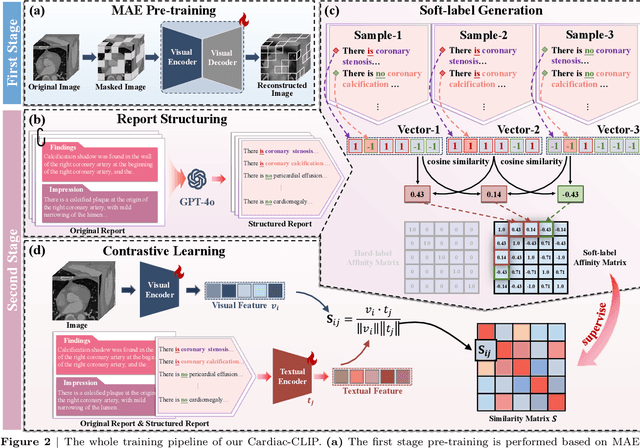
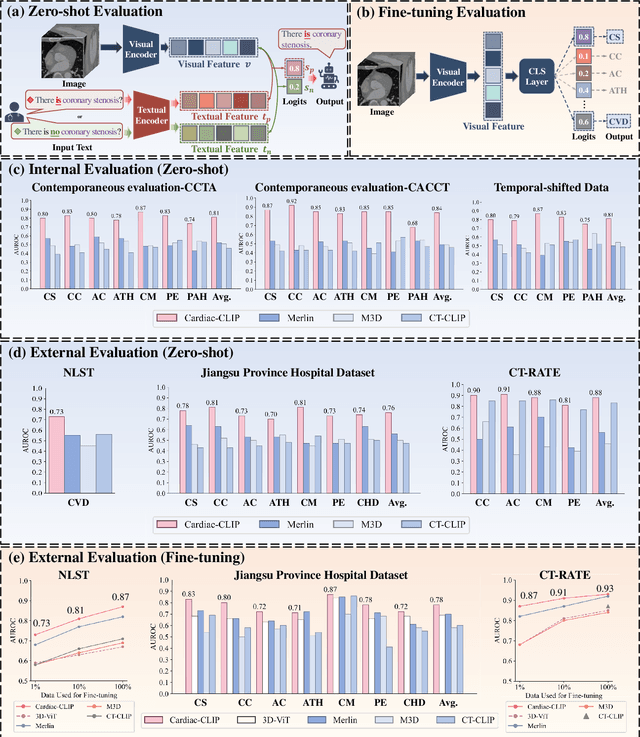
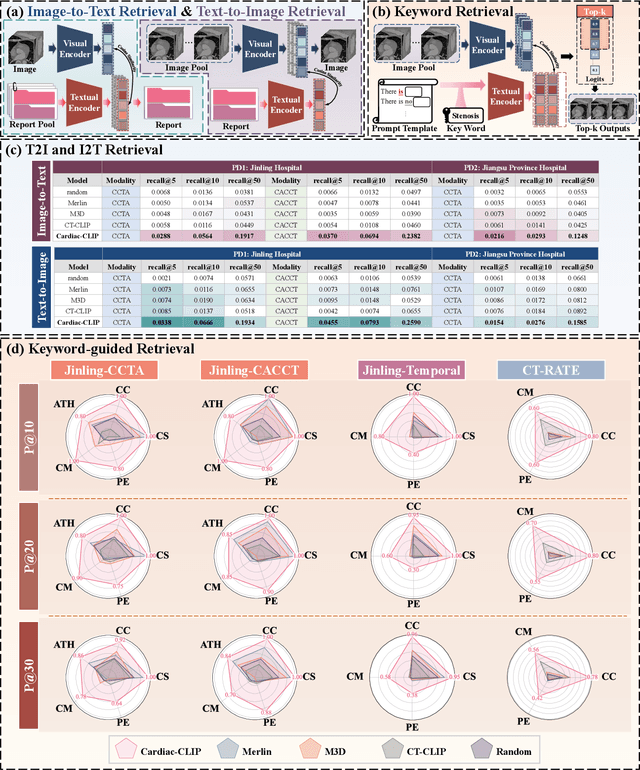
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.