 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Optimization with Bayesian Anchored Latent Trust Regions for Structural Design under High-Dimensional Uncertainty
Apr 28, 2026Categorical structural optimization under aleatoric uncertainty is challenging because each design variable must be selected from a finite catalog of admissible instances, while each candidate design may require expensive stochastic finite-element evaluations. Existing latent-space optimization strategies can reduce the dimensionality of catalog attributes, but they often treat the reduced space as a continuous search domain. The resulting continuous optimum must then be rounded off to a nearby catalog instance, which may alter the objective value, constraint status, or physical interpretation of the design. To address this issue, this paper proposes the \textbf{C}ategorical \textbf{O}ptimization with \textbf{B}ayesian \textbf{A}nchored \textbf{L}atent \textbf{T}rust Regions (\textbf{COBALT}) framework for high-dimensional categorical Optimization Under Uncertainty. COBALT first embeds the physical catalog into a low-dimensional latent representation and locks the mapped instances as a discrete anchored graph. A data-independent random tree decomposition is then used to provide bounded-complexity additive modeling over high-dimensional categorical variables. On this anchored domain, an additive SAAS-GP surrogate is fitted to heteroscedastic MC-FEA observations, and a trust-region discrete graph acquisition search selects the next admissible catalog configuration without continuous relaxation or rounding-off. The proposed strategy is applied to robust design optimization of complex bar structures, considering structural weight, strain energy, and local buckling performance. By evaluating only valid catalog designs through the MC-FEA oracle, COBALT preserves physical admissibility throughout the active learning loop and improves the efficiency of robust categorical structural optimization.
Constitutive parameterized deep energy method for solid mechanics problems with random material parameters
Mar 27, 2026In practical structural design and solid mechanics simulations, material properties inherently exhibit random variations within bounded intervals. However, evaluating mechanical responses under continuous material uncertainty remains a persistent challenge. Traditional numerical approaches, such as the Finite Element Method (FEM), incur prohibitive computational costs as they require repeated mesh discretization and equation solving for every parametric realization. Similarly, data-driven surrogate models depend heavily on massive, high-fidelity datasets, while standard physics-informed frameworks (e.g., the Deep Energy Method) strictly demand complete retraining from scratch whenever material parameters change. To bridge this critical gap, we propose the Constitutive Parameterized Deep Energy Method (CPDEM). In this purely physics-driven framework, the strain energy density functional is reformulated by encoding a latent representation of stochastic constitutive parameters. By embedding material parameters directly into the neural network alongside spatial coordinates, CPDEM transforms conventional spatial collocation points into parameter-aware material points. Trained in an unsupervised manner via expected energy minimization over the parameter domain, the pre-trained model continuously learns the solution manifold. Consequently, it enables zero-shot, real-time inference of displacement fields for unknown material parameters without requiring any dataset generation or model retraining. The proposed method is rigorously validated across diverse benchmarks, including linear elasticity, finite-strain hyperelasticity, and complex highly nonlinear contact mechanics. To the best of our knowledge, CPDEM represents the first purely physics-driven deep learning paradigm capable of simultaneously and efficiently handling continuous multi-parameter variations in solid mechanics.
Error Estimate and Convergence Analysis for Data Valuation
Nov 09, 2025Data valuation quantifies data importance, but existing methods cannot ensure validity in a single training process. The neural dynamic data valuation (NDDV) method [3] addresses this limitation. Based on NDDV, we are the first to explore error estimation and convergence analysis in data valuation. Under Lipschitz and smoothness assumptions, we derive quadratic error bounds for loss differences that scale inversely with time steps and quadratically with control variations, ensuring stability. We also prove that the expected squared gradient norm for the training loss vanishes asymptotically, and that the meta loss converges sublinearly over iterations. In particular, NDDV achieves sublinear convergence.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Neural Dynamic Data Valuation
Apr 30, 2024



Data constitute the foundational component of the data economy and its marketplaces. Efficient and fair data valuation has emerged as a topic of significant interest.\ Many approaches based on marginal contribution have shown promising results in various downstream tasks. However, they are well known to be computationally expensive as they require training a large number of utility functions, which are used to evaluate the usefulness or value of a given dataset for a specific purpose. As a result, it has been recognized as infeasible to apply these methods to a data marketplace involving large-scale datasets. Consequently, a critical issue arises: how can the re-training of the utility function be avoided? To address this issue, we propose a novel data valuation method from the perspective of optimal control, named the neural dynamic data valuation (NDDV). Our method has solid theoretical interpretations to accurately identify the data valuation via the sensitivity of the data optimal control state. In addition, we implement a data re-weighting strategy to capture the unique features of data points, ensuring fairness through the interaction between data points and the mean-field states. Notably, our method requires only training once to estimate the value of all data points, significantly improving the computational efficiency. We conduct comprehensive experiments using different datasets and tasks. The results demonstrate that the proposed NDDV method outperforms the existing state-of-the-art data valuation methods in accurately identifying data points with either high or low values and is more computationally efficient.
Temporal-wise Attention Spiking Neural Networks for Event Streams Classification
Jul 25, 2021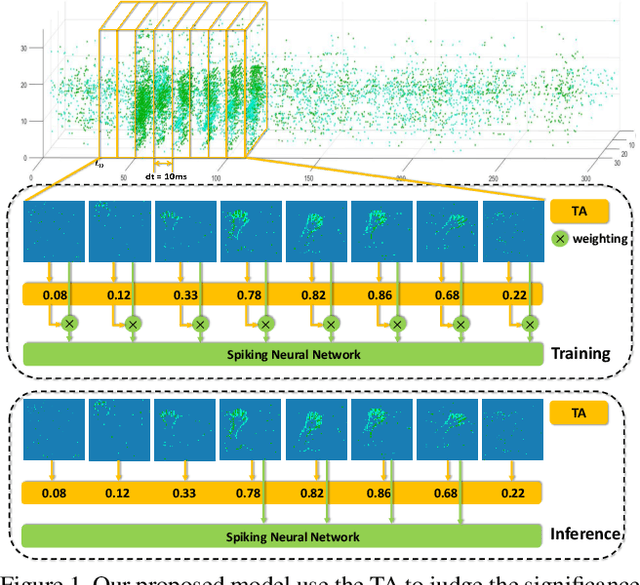

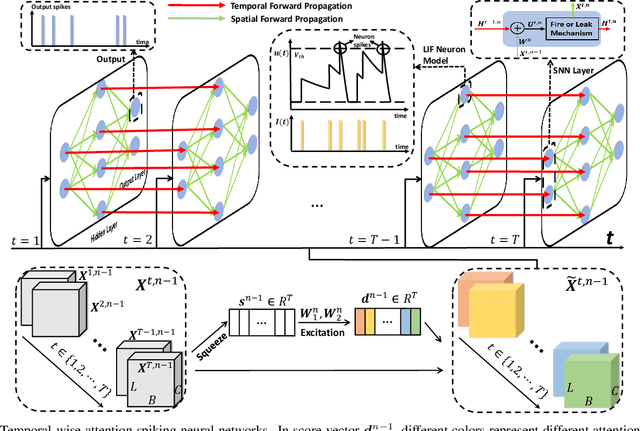

How to effectively and efficiently deal with spatio-temporal event streams, where the events are generally sparse and non-uniform and have the microsecond temporal resolution, is of great value and has various real-life applications. Spiking neural network (SNN), as one of the brain-inspired event-triggered computing models, has the potential to extract effective spatio-temporal features from the event streams. However, when aggregating individual events into frames with a new higher temporal resolution, existing SNN models do not attach importance to that the serial frames have different signal-to-noise ratios since event streams are sparse and non-uniform. This situation interferes with the performance of existing SNNs. In this work, we propose a temporal-wise attention SNN (TA-SNN) model to learn frame-based representation for processing event streams. Concretely, we extend the attention concept to temporal-wise input to judge the significance of frames for the final decision at the training stage, and discard the irrelevant frames at the inference stage. We demonstrate that TA-SNN models improve the accuracy of event streams classification tasks. We also study the impact of multiple-scale temporal resolutions for frame-based representation. Our approach is tested on three different classification tasks: gesture recognition, image classification, and spoken digit recognition. We report the state-of-the-art results on these tasks, and get the essential improvement of accuracy (almost 19\%) for gesture recognition with only 60 ms.