 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeography According to ChatGPT -- How Generative AI Represents and Reasons about Geography
Mar 19, 2026Understanding how AI will represent and reason about geography should be a key concern for all of us, as the broader public increasingly interacts with spaces and places through these systems. Similarly, in line with the nature of foundation models, our own research often relies on pre-trained models. Hence, understanding what world AI systems construct is as important as evaluating their accuracy, including factual recall. To motivate the need for such studies, we provide three illustrative vignettes, i.e., exploratory probes, in the hope that they will spark lively discussions and follow-up work: (1) Do models form strong defaults, and how brittle are model outputs to minute syntactic variations? (2) Can distributional shifts resurface from the composition of individually benign tasks, e.g., when using AI systems to create personas? (3) Do we overlook deeper questions of understanding when solely focusing on the ability of systems to recall facts such as geographic principles?
Federated Unlearning in the Wild: Rethinking Fairness and Data Discrepancy
Oct 08, 2025Machine unlearning is critical for enforcing data deletion rights like the "right to be forgotten." As a decentralized paradigm, Federated Learning (FL) also requires unlearning, but realistic implementations face two major challenges. First, fairness in Federated Unlearning (FU) is often overlooked. Exact unlearning methods typically force all clients into costly retraining, even those uninvolved. Approximate approaches, using gradient ascent or distillation, make coarse interventions that can unfairly degrade performance for clients with only retained data. Second, most FU evaluations rely on synthetic data assumptions (IID/non-IID) that ignore real-world heterogeneity. These unrealistic benchmarks obscure the true impact of unlearning and limit the applicability of current methods. We first conduct a comprehensive benchmark of existing FU methods under realistic data heterogeneity and fairness conditions. We then propose a novel, fairness-aware FU approach, Federated Cross-Client-Constrains Unlearning (FedCCCU), to explicitly address both challenges. FedCCCU offers a practical and scalable solution for real-world FU. Experimental results show that existing methods perform poorly in realistic settings, while our approach consistently outperforms them.
Constrained Factor Graph Optimization for Robust Networked Pedestrian Inertial Navigation
May 13, 2025This paper presents a novel constrained Factor Graph Optimization (FGO)-based approach for networked inertial navigation in pedestrian localization. To effectively mitigate the drift inherent in inertial navigation solutions, we incorporate kinematic constraints directly into the nonlinear optimization framework. Specifically, we utilize equality constraints, such as Zero-Velocity Updates (ZUPTs), and inequality constraints representing the maximum allowable distance between body-mounted Inertial Measurement Units (IMUs) based on human anatomical limitations. While equality constraints are straightforwardly integrated as error factors, inequality constraints cannot be explicitly represented in standard FGO formulations. To address this, we introduce a differentiable softmax-based penalty term in the FGO cost function to enforce inequality constraints smoothly and robustly. The proposed constrained FGO approach leverages temporal correlations across multiple epochs, resulting in optimal state trajectory estimates while consistently maintaining constraint satisfaction. Experimental results confirm that our method outperforms conventional Kalman filter approaches, demonstrating its effectiveness and robustness for pedestrian navigation.
PyGRF: An improved Python Geographical Random Forest model and case studies in public health and natural disasters
Sep 20, 2024Geographical random forest (GRF) is a recently developed and spatially explicit machine learning model. With the ability to provide more accurate predictions and local interpretations, GRF has already been used in many studies. The current GRF model, however, has limitations in its determination of the local model weight and bandwidth hyperparameters, potentially insufficient numbers of local training samples, and sometimes high local prediction errors. Also, implemented as an R package, GRF currently does not have a Python version which limits its adoption among machine learning practitioners who prefer Python. This work addresses these limitations by introducing theory-informed hyperparameter determination, local training sample expansion, and spatially-weighted local prediction. We also develop a Python-based GRF model and package, PyGRF, to facilitate the use of the model. We evaluate the performance of PyGRF on an example dataset and further demonstrate its use in two case studies in public health and natural disasters.
Optimization-Based Outlier Accommodation for Tightly Coupled RTK-Aided Inertial Navigation Systems in Urban Environments
Jul 18, 2024



Global Navigation Satellite Systems (GNSS) aided Inertial Navigation System (INS) is a fundamental approach for attaining continuously available absolute vehicle position and full state estimates at high bandwidth. For transportation applications, stated accuracy specifications must be achieved, unless the navigation system can detect when it is violated. In urban environments, GNSS measurements are susceptible to outliers, which motivates the important problem of accommodating outliers while either achieving a performance specification or communicating that it is not feasible. Risk-Averse Performance-Specified (RAPS) is designed to optimally select measurements to address this problem. Existing RAPS approaches lack a method applicable to carrier phase measurements, which have the benefit of measurement errors at the centimeter level along with the challenge of being biased by integer ambiguities. This paper proposes a RAPS framework that combines Real-time Kinematic (RTK) GNSS in a tightly coupled INS for urban navigation applications. Experimental results demonstrate the effectiveness of this RAPS-INS-RTK framework, achieving 84.05% and 89.84% of horizontal and vertical errors less than 1.5 meters and 3 meters, respectively, using a deep-urban dataset. This performance not only surpasses the Society of Automotive Engineers (SAE) requirements, but also shows a 10% improvement compared to traditional methods.
On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence
Apr 13, 2023



Large pre-trained models, also known as foundation models (FMs), are trained in a task-agnostic manner on large-scale data and can be adapted to a wide range of downstream tasks by fine-tuning, few-shot, or even zero-shot learning. Despite their successes in language and vision tasks, we have yet seen an attempt to develop foundation models for geospatial artificial intelligence (GeoAI). In this work, we explore the promises and challenges of developing multimodal foundation models for GeoAI. We first investigate the potential of many existing FMs by testing their performances on seven tasks across multiple geospatial subdomains including Geospatial Semantics, Health Geography, Urban Geography, and Remote Sensing. Our results indicate that on several geospatial tasks that only involve text modality such as toponym recognition, location description recognition, and US state-level/county-level dementia time series forecasting, these task-agnostic LLMs can outperform task-specific fully-supervised models in a zero-shot or few-shot learning setting. However, on other geospatial tasks, especially tasks that involve multiple data modalities (e.g., POI-based urban function classification, street view image-based urban noise intensity classification, and remote sensing image scene classification), existing foundation models still underperform task-specific models. Based on these observations, we propose that one of the major challenges of developing a FM for GeoAI is to address the multimodality nature of geospatial tasks. After discussing the distinct challenges of each geospatial data modality, we suggest the possibility of a multimodal foundation model which can reason over various types of geospatial data through geospatial alignments. We conclude this paper by discussing the unique risks and challenges to develop such a model for GeoAI.
TopoBERT: Plug and Play Toponym Recognition Module Harnessing Fine-tuned BERT
Feb 03, 2023Extracting precise geographical information from textual contents is crucial in a plethora of applications. For example, during hazardous events, a robust and unbiased toponym extraction framework can provide an avenue to tie the location concerned to the topic discussed by news media posts and pinpoint humanitarian help requests or damage reports from social media. Early studies have leveraged rule-based, gazetteer-based, deep learning, and hybrid approaches to address this problem. However, the performance of existing tools is deficient in supporting operations like emergency rescue, which relies on fine-grained, accurate geographic information. The emerging pretrained language models can better capture the underlying characteristics of text information, including place names, offering a promising pathway to optimize toponym recognition to underpin practical applications. In this paper, TopoBERT, a toponym recognition module based on a one dimensional Convolutional Neural Network (CNN1D) and Bidirectional Encoder Representation from Transformers (BERT), is proposed and fine-tuned. Three datasets (CoNLL2003-Train, Wikipedia3000, WNUT2017) are leveraged to tune the hyperparameters, discover the best training strategy, and train the model. Another two datasets (CoNLL2003-Test and Harvey2017) are used to evaluate the performance. Three distinguished classifiers, linear, multi-layer perceptron, and CNN1D, are benchmarked to determine the optimal model architecture. TopoBERT achieves state-of-the-art performance (f1-score=0.865) compared to the other five baseline models and can be applied to diverse toponym recognition tasks without additional training.
Location reference recognition from texts: A survey and comparison
Jul 04, 2022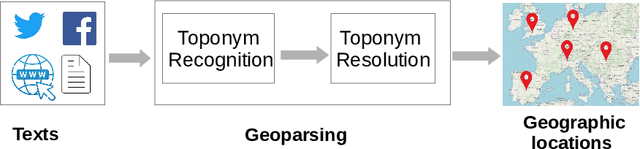
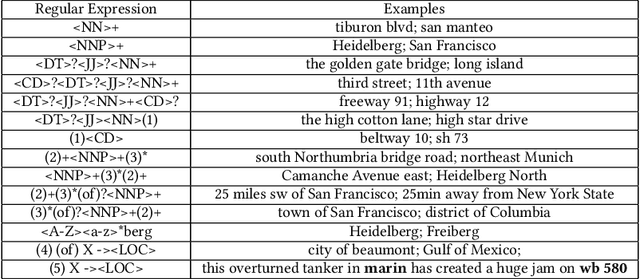
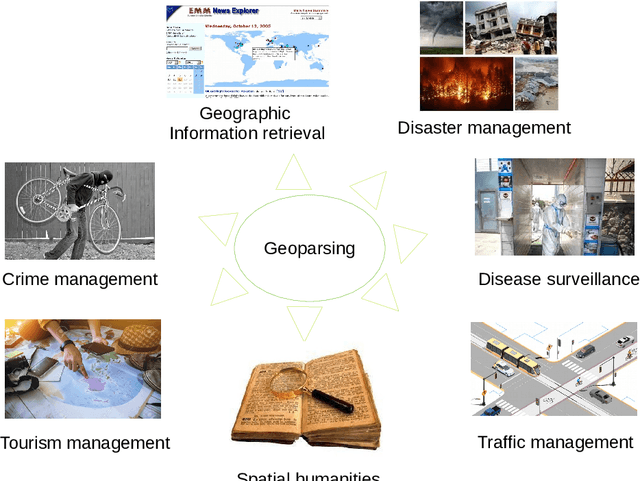
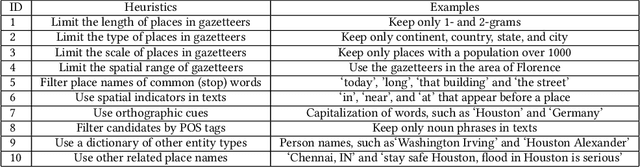
A vast amount of location information exists in unstructured texts, such as social media posts, news stories, scientific articles, web pages, travel blogs, and historical archives. Geoparsing refers to the process of recognizing location references from texts and identifying their geospatial representations. While geoparsing can benefit many domains, a summary of the specific applications is still missing. Further, there lacks a comprehensive review and comparison of existing approaches for location reference recognition, which is the first and a core step of geoparsing. To fill these research gaps, this review first summarizes seven typical application domains of geoparsing: geographic information retrieval, disaster management, disease surveillance, traffic management, spatial humanities, tourism management, and crime management. We then review existing approaches for location reference recognition by categorizing these approaches into four groups based on their underlying functional principle: rule-based, gazetteer matching-based, statistical learning-based, and hybrid approaches. Next, we thoroughly evaluate the correctness and computational efficiency of the 27 most widely used approaches for location reference recognition based on 26 public datasets with different types of texts (e.g., social media posts and news stories) containing 39,736 location references across the world. Results from this thorough evaluation can help inform future methodological developments for location reference recognition, and can help guide the selection of proper approaches based on application needs.
The role of alcohol outlet visits derived from mobile phone location data in enhancing domestic violence prediction at the neighborhood level
Feb 26, 2022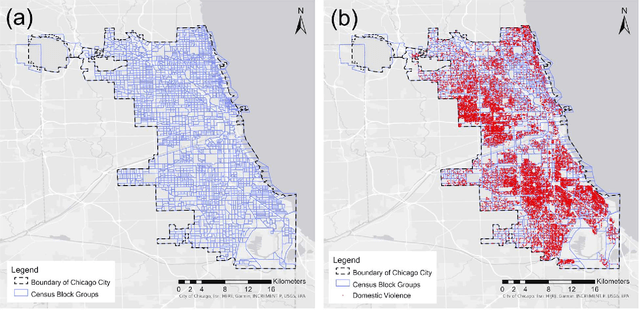

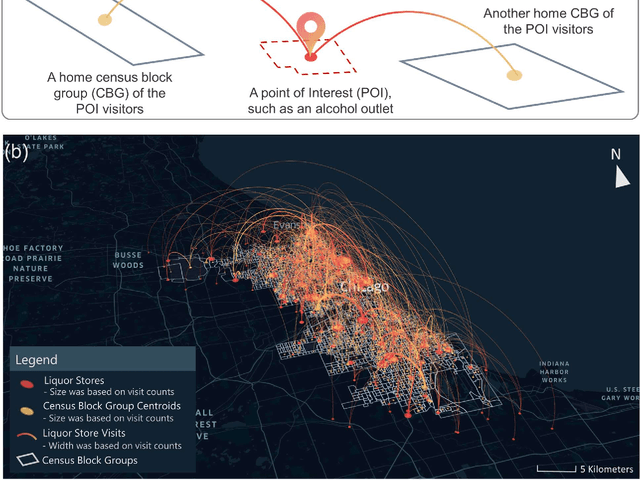
Domestic violence (DV) is a serious public health issue, with 1 in 3 women and 1 in 4 men experiencing some form of partner-related violence every year. Existing research has shown a strong association between alcohol use and DV at the individual level. Accordingly, alcohol use could also be a predictor for DV at the neighborhood level, helping identify the neighborhoods where DV is more likely to happen. However, it is difficult and costly to collect data that can represent neighborhood-level alcohol use especially for a large geographic area. In this study, we propose to derive information about the alcohol outlet visits of the residents of different neighborhoods from anonymized mobile phone location data, and investigate whether the derived visits can help better predict DV at the neighborhood level. We use mobile phone data from the company SafeGraph, which is freely available to researchers and which contains information about how people visit various points-of-interest including alcohol outlets. In such data, a visit to an alcohol outlet is identified based on the GPS point location of the mobile phone and the building footprint (a polygon) of the alcohol outlet. We present our method for deriving neighborhood-level alcohol outlet visits, and experiment with four different statistical and machine learning models to investigate the role of the derived visits in enhancing DV prediction based on an empirical dataset about DV in Chicago. Our results reveal the effectiveness of the derived alcohol outlets visits in helping identify neighborhoods that are more likely to suffer from DV, and can inform policies related to DV intervention and alcohol outlet licensing.
* 35 pages
A Review of Location Encoding for GeoAI: Methods and Applications
Nov 07, 2021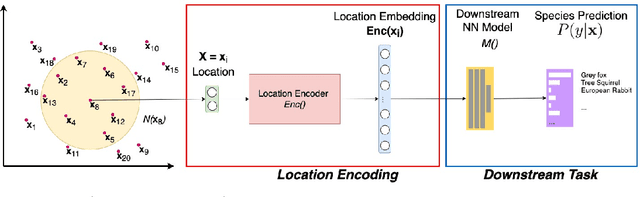
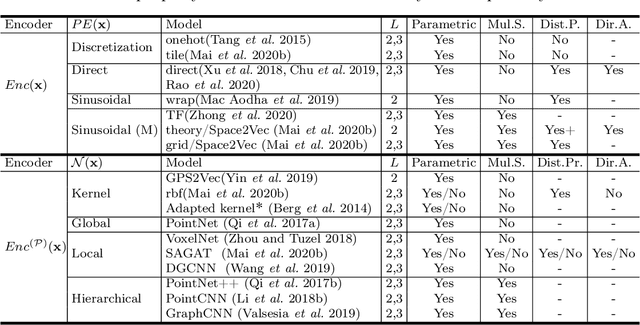
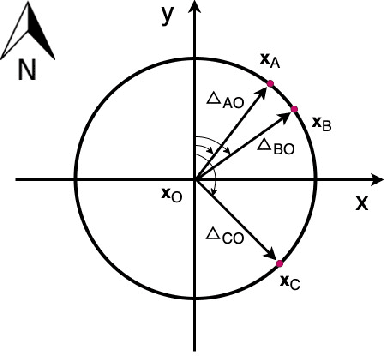
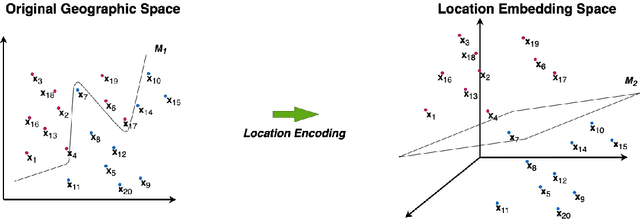
A common need for artificial intelligence models in the broader geoscience is to represent and encode various types of spatial data, such as points (e.g., points of interest), polylines (e.g., trajectories), polygons (e.g., administrative regions), graphs (e.g., transportation networks), or rasters (e.g., remote sensing images), in a hidden embedding space so that they can be readily incorporated into deep learning models. One fundamental step is to encode a single point location into an embedding space, such that this embedding is learning-friendly for downstream machine learning models such as support vector machines and neural networks. We call this process location encoding. However, there lacks a systematic review on the concept of location encoding, its potential applications, and key challenges that need to be addressed. This paper aims to fill this gap. We first provide a formal definition of location encoding, and discuss the necessity of location encoding for GeoAI research from a machine learning perspective. Next, we provide a comprehensive survey and discussion about the current landscape of location encoding research. We classify location encoding models into different categories based on their inputs and encoding methods, and compare them based on whether they are parametric, multi-scale, distance preserving, and direction aware. We demonstrate that existing location encoding models can be unified under a shared formulation framework. We also discuss the application of location encoding for different types of spatial data. Finally, we point out several challenges in location encoding research that need to be solved in the future.
* 32 Pages, 5 Figures, Accepted to International Journal of Geographical Information Science, 2021