 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmharicStoryQA: A Multicultural Story Question Answering Benchmark in Amharic
Feb 02, 2026With the growing emphasis on multilingual and cultural evaluation benchmarks for large language models, language and culture are often treated as synonymous, and performance is commonly used as a proxy for a models understanding of a given language. In this work, we argue that such evaluations overlook meaningful cultural variation that exists within a single language. We address this gap by focusing on narratives from different regions of Ethiopia and demonstrate that, despite shared linguistic characteristics, region-specific and domain-specific content substantially influences language evaluation outcomes. To this end, we introduce \textbf{\textit{AmharicStoryQA}}, a long-sequence story question answering benchmark grounded in culturally diverse narratives from Amharic-speaking regions. Using this benchmark, we reveal a significant narrative understanding gap in existing LLMs, highlight pronounced regional differences in evaluation results, and show that supervised fine-tuning yields uneven improvements across regions and evaluation settings. Our findings emphasize the need for culturally grounded benchmarks that go beyond language-level evaluation to more accurately assess and improve narrative understanding in low-resource languages.
Afri-MCQA: Multimodal Cultural Question Answering for African Languages
Jan 09, 2026Africa is home to over one-third of the world's languages, yet remains underrepresented in AI research. We introduce Afri-MCQA, the first Multilingual Cultural Question-Answering benchmark covering 7.5k Q&A pairs across 15 African languages from 12 countries. The benchmark offers parallel English-African language Q&A pairs across text and speech modalities and was entirely created by native speakers. Benchmarking large language models (LLMs) on Afri-MCQA shows that open-weight models perform poorly across evaluated cultures, with near-zero accuracy on open-ended VQA when queried in native language or speech. To evaluate linguistic competence, we include control experiments meant to assess this specific aspect separate from cultural knowledge, and we observe significant performance gaps between native languages and English for both text and speech. These findings underscore the need for speech-first approaches, culturally grounded pretraining, and cross-lingual cultural transfer. To support more inclusive multimodal AI development in African languages, we release our Afri-MCQA under academic license or CC BY-NC 4.0 on HuggingFace (https://huggingface.co/datasets/Atnafu/Afri-MCQA)
Accept or Deny? Evaluating LLM Fairness and Performance in Loan Approval across Table-to-Text Serialization Approaches
Aug 29, 2025



Large Language Models (LLMs) are increasingly employed in high-stakes decision-making tasks, such as loan approvals. While their applications expand across domains, LLMs struggle to process tabular data, ensuring fairness and delivering reliable predictions. In this work, we assess the performance and fairness of LLMs on serialized loan approval datasets from three geographically distinct regions: Ghana, Germany, and the United States. Our evaluation focuses on the model's zero-shot and in-context learning (ICL) capabilities. Our results reveal that the choice of serialization (Serialization refers to the process of converting tabular data into text formats suitable for processing by LLMs.) format significantly affects both performance and fairness in LLMs, with certain formats such as GReat and LIFT yielding higher F1 scores but exacerbating fairness disparities. Notably, while ICL improved model performance by 4.9-59.6% relative to zero-shot baselines, its effect on fairness varied considerably across datasets. Our work underscores the importance of effective tabular data representation methods and fairness-aware models to improve the reliability of LLMs in financial decision-making.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
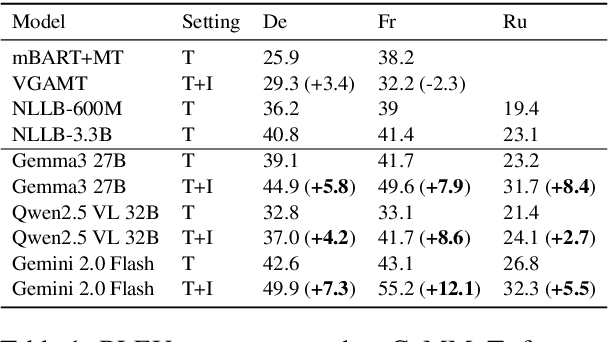

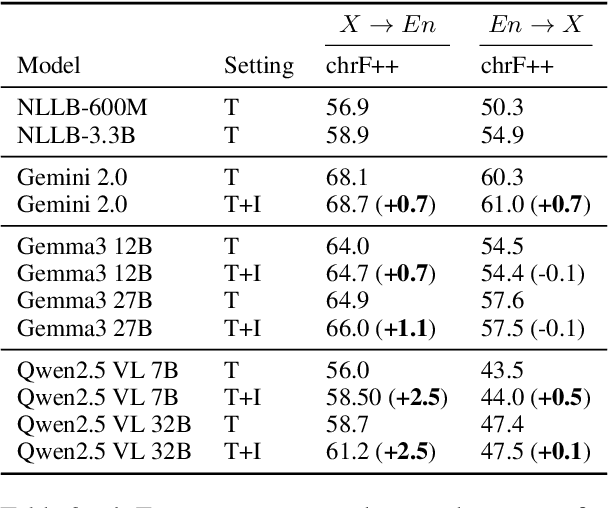
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
AFRIDOC-MT: Document-level MT Corpus for African Languages
Jan 10, 2025



This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yor\`ub\'a, and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating neural machine translation (NMT) models and large language models (LLMs) for translations between English and these languages, at both the sentence and pseudo-document levels. These outputs are realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieved the best average performance among the standard NMT models, while GPT-4o outperformed general-purpose LLMs. Fine-tuning selected models led to substantial performance gains, but models trained on sentences struggled to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, repetition of words or phrases, and off-target translations, especially for African languages.
Evaluating the Capabilities of Large Language Models for Multi-label Emotion Understanding
Dec 17, 2024Large Language Models (LLMs) show promising learning and reasoning abilities. Compared to other NLP tasks, multilingual and multi-label emotion evaluation tasks are under-explored in LLMs. In this paper, we present EthioEmo, a multi-label emotion classification dataset for four Ethiopian languages, namely, Amharic (amh), Afan Oromo (orm), Somali (som), and Tigrinya (tir). We perform extensive experiments with an additional English multi-label emotion dataset from SemEval 2018 Task 1. Our evaluation includes encoder-only, encoder-decoder, and decoder-only language models. We compare zero and few-shot approaches of LLMs to fine-tuning smaller language models. The results show that accurate multi-label emotion classification is still insufficient even for high-resource languages such as English, and there is a large gap between the performance of high-resource and low-resource languages. The results also show varying performance levels depending on the language and model type. EthioEmo is available publicly to further improve the understanding of emotions in language models and how people convey emotions through various languages.
Uhura: A Benchmark for Evaluating Scientific Question Answering and Truthfulness in Low-Resource African Languages
Dec 01, 2024



Evaluations of Large Language Models (LLMs) on knowledge-intensive tasks and factual accuracy often focus on high-resource languages primarily because datasets for low-resource languages (LRLs) are scarce. In this paper, we present Uhura -- a new benchmark that focuses on two tasks in six typologically-diverse African languages, created via human translation of existing English benchmarks. The first dataset, Uhura-ARC-Easy, is composed of multiple-choice science questions. The second, Uhura-TruthfulQA, is a safety benchmark testing the truthfulness of models on topics including health, law, finance, and politics. We highlight the challenges creating benchmarks with highly technical content for LRLs and outline mitigation strategies. Our evaluation reveals a significant performance gap between proprietary models such as GPT-4o and o1-preview, and Claude models, and open-source models like Meta's LLaMA and Google's Gemma. Additionally, all models perform better in English than in African languages. These results indicate that LMs struggle with answering scientific questions and are more prone to generating false claims in low-resource African languages. Our findings underscore the necessity for continuous improvement of multilingual LM capabilities in LRL settings to ensure safe and reliable use in real-world contexts. We open-source the Uhura Benchmark and Uhura Platform to foster further research and development in NLP for LRLs.
ProverbEval: Exploring LLM Evaluation Challenges for Low-resource Language Understanding
Nov 07, 2024



With the rapid development of evaluation datasets to assess LLMs understanding across a wide range of subjects and domains, identifying a suitable language understanding benchmark has become increasingly challenging. In this work, we explore LLM evaluation challenges for low-resource language understanding and introduce ProverbEval, LLM evaluation benchmark for low-resource languages based on proverbs to focus on low-resource language understanding in culture-specific scenarios. We benchmark various LLMs and explore factors that create variability in the benchmarking process. We observed performance variances of up to 50%, depending on the order in which answer choices were presented in multiple-choice tasks. Native language proverb descriptions significantly improve tasks such as proverb generation, contributing to improved outcomes. Additionally, monolingual evaluations consistently outperformed their cross-lingual counterparts. We argue special attention must be given to the order of choices, choice of prompt language, task variability, and generation tasks when creating LLM evaluation benchmarks.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Jun 05, 2024



Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.