 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Object Interactions with Physics-Guided Video Diffusion
Oct 02, 2025Recent models for video generation have achieved remarkable progress and are now deployed in film, social media production, and advertising. Beyond their creative potential, such models also hold promise as world simulators for robotics and embodied decision making. Despite strong advances, however, current approaches still struggle to generate physically plausible object interactions and lack physics-grounded control mechanisms. To address this limitation, we introduce KineMask, an approach for physics-guided video generation that enables realistic rigid body control, interactions, and effects. Given a single image and a specified object velocity, our method generates videos with inferred motions and future object interactions. We propose a two-stage training strategy that gradually removes future motion supervision via object masks. Using this strategy we train video diffusion models (VDMs) on synthetic scenes of simple interactions and demonstrate significant improvements of object interactions in real scenes. Furthermore, KineMask integrates low-level motion control with high-level textual conditioning via predictive scene descriptions, leading to effective support for synthesis of complex dynamical phenomena. Extensive experiments show that KineMask achieves strong improvements over recent models of comparable size. Ablation studies further highlight the complementary roles of low- and high-level conditioning in VDMs. Our code, model, and data will be made publicly available.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Question-Instructed Visual Descriptions for Zero-Shot Video Question Answering
Feb 16, 2024We present Q-ViD, a simple approach for video question answering (video QA), that unlike prior methods, which are based on complex architectures, computationally expensive pipelines or use closed models like GPTs, Q-ViD relies on a single instruction-aware open vision-language model (InstructBLIP) to tackle videoQA using frame descriptions. Specifically, we create captioning instruction prompts that rely on the target questions about the videos and leverage InstructBLIP to obtain video frame captions that are useful to the task at hand. Subsequently, we form descriptions of the whole video using the question-dependent frame captions, and feed that information, along with a question-answering prompt, to a large language model (LLM). The LLM is our reasoning module, and performs the final step of multiple-choice QA. Our simple Q-ViD framework achieves competitive or even higher performances than current state of the art models on a diverse range of videoQA benchmarks, including NExT-QA, STAR, How2QA, TVQA and IntentQA.
Reinforcement Learning with Budget-Constrained Nonparametric Function Approximation for Opportunistic Spectrum Access
Jun 20, 2018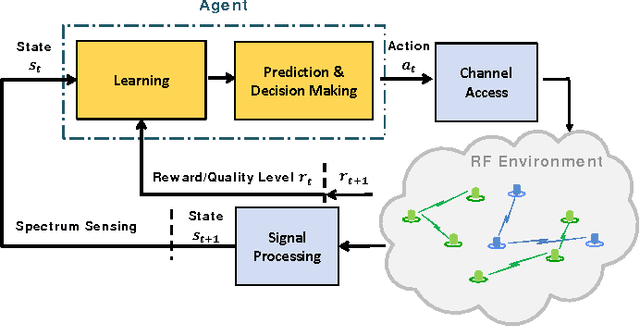
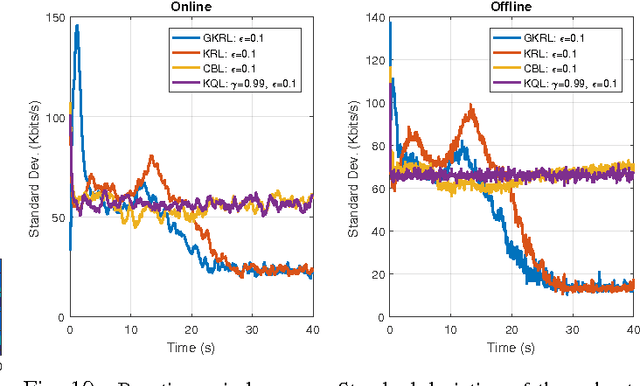
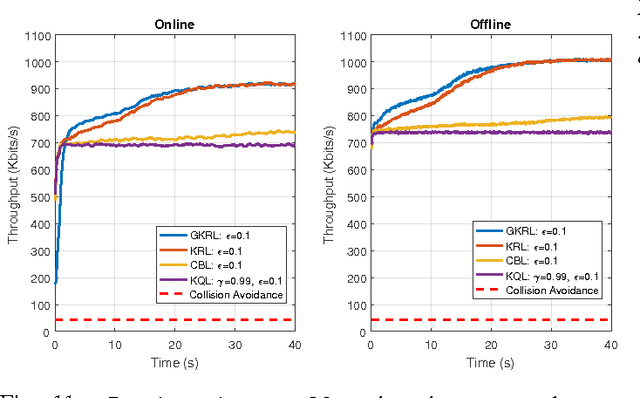
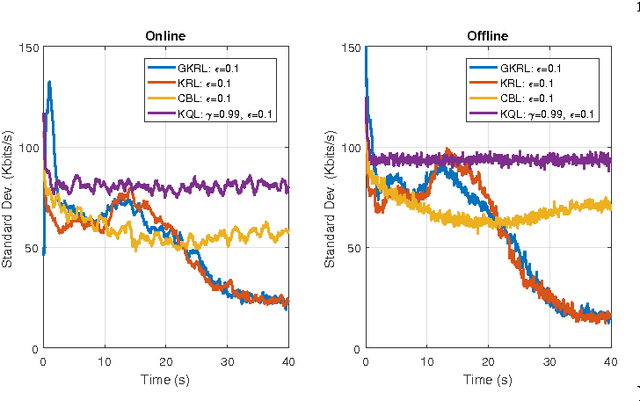
Opportunistic spectrum access is one of the emerging techniques for maximizing throughput in congested bands and is enabled by predicting idle slots in spectrum. We propose a kernel-based reinforcement learning approach coupled with a novel budget-constrained sparsification technique that efficiently captures the environment to find the best channel access actions. This approach allows learning and planning over the intrinsic state-action space and extends well to large state spaces. We apply our methods to evaluate coexistence of a reinforcement learning-based radio with a multi-channel adversarial radio and a single-channel CSMA-CA radio. Numerical experiments show the performance gains over carrier-sense systems.