 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFKI-MLT at SemEval-2026 TASK 7: Steering Multilingual Models Towards Cultural Knowledge
May 21, 2026Large language models (LLMs) are increasingly used across diverse linguistic and cultural contexts, yet their cultural knowledge remains uneven across regions and languages. We present the DFKI-MLT system for SemEval-2026 Task 7 on cultural awareness, where we apply activation steering to multilingual LLMs using language vectors extracted from parallel FLORES data. Our method performs inference-time adaptation by adding language-specific steering vectors to the residual stream at a selected transformer layer, without any parameter updates. We participated in both the short-answer (SAQ) and multiple-choice (MCQ) tracks; however, only our MCQ submission received an official score. In the official MCQ track, we achieved 86.96% accuracy, ranking 7th out of 17 teams. To better understand system behavior, we conduct post-hoc analyses on the shared-task MCQ and SAQ settings. These analyses show that activation steering yields modest and heterogeneous improvements on cultural reasoning: gains are strongly layer-sensitive, vary substantially across language-region pairs, with some configurations even degrading performance, and interact with prompt formulation, comparing generic and culturally conditioned prompts. Our findings suggest that prompt design and activation steering should be jointly optimized for culturally aware multilingual inference.
Zero-Shot TTS With Enhanced Audio Prompts: Bsc Submission For The 2026 Wildspoof Challenge TTS Track
Feb 05, 2026We evaluate two non-autoregressive architectures, StyleTTS2 and F5-TTS, to address the spontaneous nature of in-the-wild speech. Our models utilize flexible duration modeling to improve prosodic naturalness. To handle acoustic noise, we implement a multi-stage enhancement pipeline using the Sidon model, which significantly outperforms standard Demucs in signal quality. Experimental results show that finetuning enhanced audios yields superior robustness, achieving up to 4.21 UTMOS and 3.47 DNSMOS. Furthermore, we analyze the impact of reference prompt quality and length on zero-shot synthesis performance, demonstrating the effectiveness of our approach for realistic speech generation.
AFRIDOC-MT: Document-level MT Corpus for African Languages
Jan 10, 2025



This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yor\`ub\'a, and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating neural machine translation (NMT) models and large language models (LLMs) for translations between English and these languages, at both the sentence and pseudo-document levels. These outputs are realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieved the best average performance among the standard NMT models, while GPT-4o outperformed general-purpose LLMs. Fine-tuning selected models led to substantial performance gains, but models trained on sentences struggled to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, repetition of words or phrases, and off-target translations, especially for African languages.
Translating away Translationese without Parallel Data
Oct 28, 2023



Translated texts exhibit systematic linguistic differences compared to original texts in the same language, and these differences are referred to as translationese. Translationese has effects on various cross-lingual natural language processing tasks, potentially leading to biased results. In this paper, we explore a novel approach to reduce translationese in translated texts: translation-based style transfer. As there are no parallel human-translated and original data in the same language, we use a self-supervised approach that can learn from comparable (rather than parallel) mono-lingual original and translated data. However, even this self-supervised approach requires some parallel data for validation. We show how we can eliminate the need for parallel validation data by combining the self-supervised loss with an unsupervised loss. This unsupervised loss leverages the original language model loss over the style-transferred output and a semantic similarity loss between the input and style-transferred output. We evaluate our approach in terms of original vs. translationese binary classification in addition to measuring content preservation and target-style fluency. The results show that our approach is able to reduce translationese classifier accuracy to a level of a random classifier after style transfer while adequately preserving the content and fluency in the target original style.
Multilingual Coarse Political Stance Classification of Media. The Editorial Line of a ChatGPT and Bard Newspaper
Oct 25, 2023



Neutrality is difficult to achieve and, in politics, subjective. Traditional media typically adopt an editorial line that can be used by their potential readers as an indicator of the media bias. Several platforms currently rate news outlets according to their political bias. The editorial line and the ratings help readers in gathering a balanced view of news. But in the advent of instruction-following language models, tasks such as writing a newspaper article can be delegated to computers. Without imposing a biased persona, where would an AI-based news outlet lie within the bias ratings? In this work, we use the ratings of authentic news outlets to create a multilingual corpus of news with coarse stance annotations (Left and Right) along with automatically extracted topic annotations. We show that classifiers trained on this data are able to identify the editorial line of most unseen newspapers in English, German, Spanish and Catalan. We then apply the classifiers to 101 newspaper-like articles written by ChatGPT and Bard in the 4 languages at different time periods. We observe that, similarly to traditional newspapers, ChatGPT editorial line evolves with time and, being a data-driven system, the stance of the generated articles differs among languages.
A Simple Method for Unsupervised Bilingual Lexicon Induction for Data-Imbalanced, Closely Related Language Pairs
May 23, 2023



Existing approaches for unsupervised bilingual lexicon induction (BLI) often depend on good quality static or contextual embeddings trained on large monolingual corpora for both languages. In reality, however, unsupervised BLI is most likely to be useful for dialects and languages that do not have abundant amounts of monolingual data. We introduce a simple and fast method for unsupervised BLI for low-resource languages with a related mid-to-high resource language, only requiring inference on the higher-resource language monolingual BERT. We work with two low-resource languages ($<5M$ monolingual tokens), Bhojpuri and Magahi, of the severely under-researched Indic dialect continuum, showing that state-of-the-art methods in the literature show near-zero performance in these settings, and that our simpler method gives much better results. We repeat our experiments on Marathi and Nepali, two higher-resource Indic languages, to compare approach performances by resource range. We release automatically created bilingual lexicons for the first time for five languages of the Indic dialect continuum.
Explaining Translationese: why are Neural Classifiers Better and what do they Learn?
Oct 24, 2022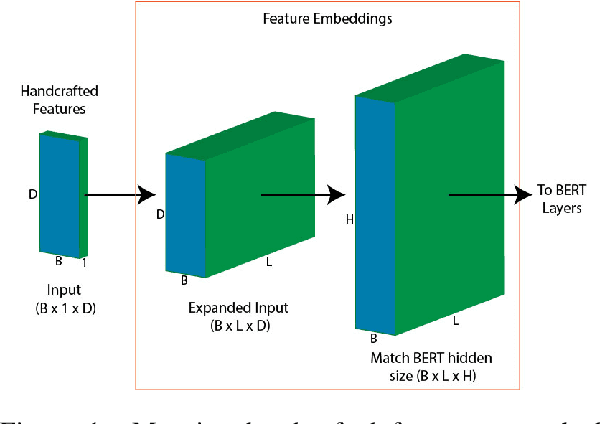


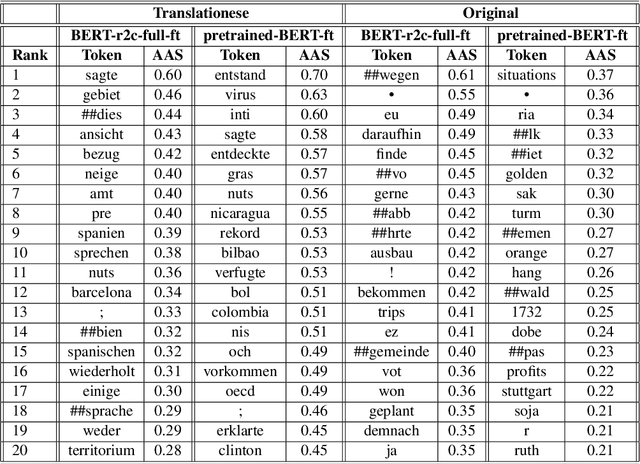
Recent work has shown that neural feature- and representation-learning, e.g. BERT, achieves superior performance over traditional manual feature engineering based approaches, with e.g. SVMs, in translationese classification tasks. Previous research did not show $(i)$ whether the difference is because of the features, the classifiers or both, and $(ii)$ what the neural classifiers actually learn. To address $(i)$, we carefully design experiments that swap features between BERT- and SVM-based classifiers. We show that an SVM fed with BERT representations performs at the level of the best BERT classifiers, while BERT learning and using handcrafted features performs at the level of an SVM using handcrafted features. This shows that the performance differences are due to the features. To address $(ii)$ we use integrated gradients and find that $(a)$ there is indication that information captured by hand-crafted features is only a subset of what BERT learns, and $(b)$ part of BERT's top performance results are due to BERT learning topic differences and spurious correlations with translationese.
Exploiting Social Media Content for Self-Supervised Style Transfer
May 18, 2022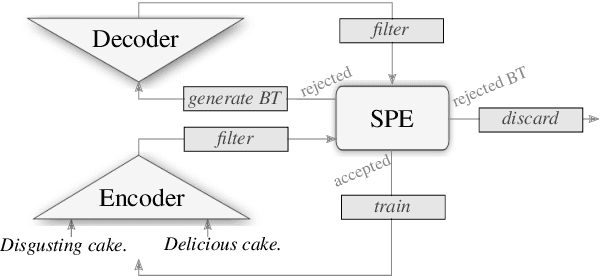
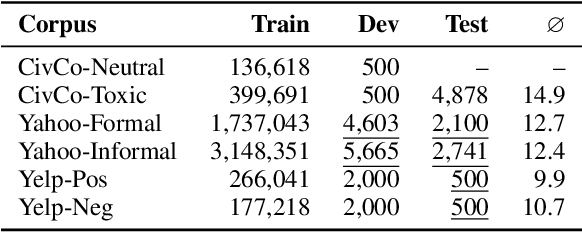
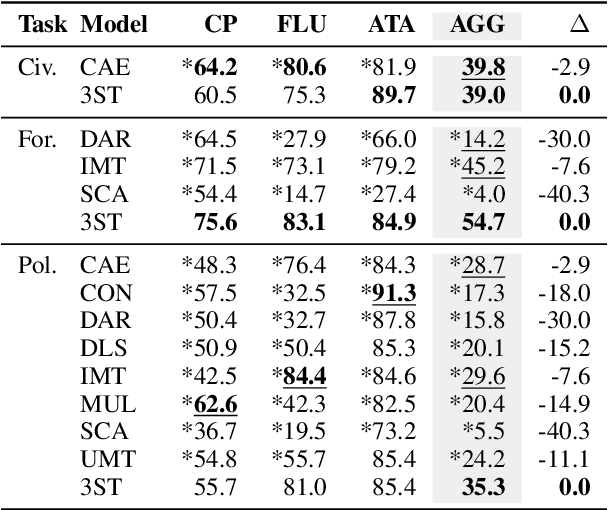
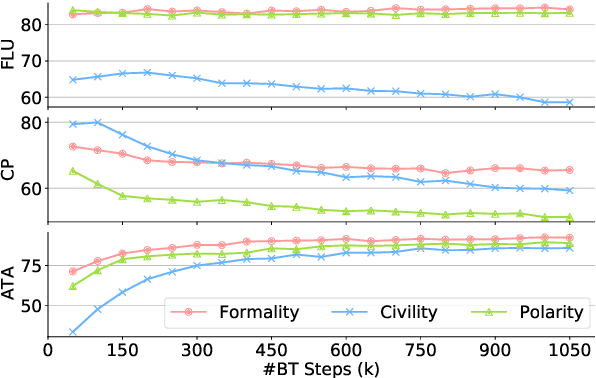
Recent research on style transfer takes inspiration from unsupervised neural machine translation (UNMT), learning from large amounts of non-parallel data by exploiting cycle consistency loss, back-translation, and denoising autoencoders. By contrast, the use of self-supervised NMT (SSNMT), which leverages (near) parallel instances hidden in non-parallel data more efficiently than UNMT, has not yet been explored for style transfer. In this paper we present a novel Self-Supervised Style Transfer (3ST) model, which augments SSNMT with UNMT methods in order to identify and efficiently exploit supervisory signals in non-parallel social media posts. We compare 3ST with state-of-the-art (SOTA) style transfer models across civil rephrasing, formality and polarity tasks. We show that 3ST is able to balance the three major objectives (fluency, content preservation, attribute transfer accuracy) the best, outperforming SOTA models on averaged performance across their tested tasks in automatic and human evaluation.
Towards Debiasing Translation Artifacts
May 16, 2022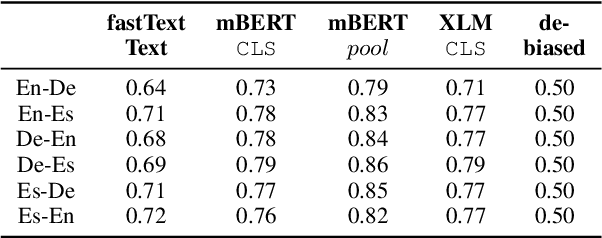
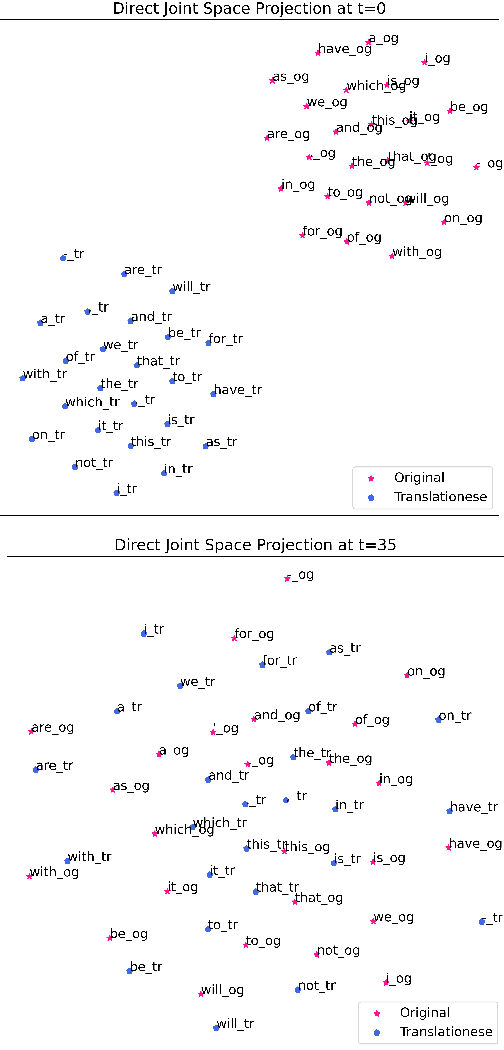
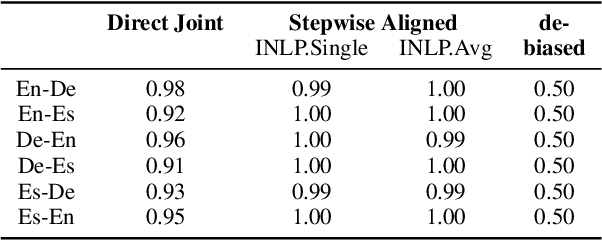
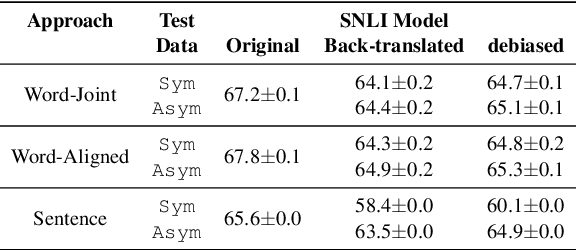
Cross-lingual natural language processing relies on translation, either by humans or machines, at different levels, from translating training data to translating test sets. However, compared to original texts in the same language, translations possess distinct qualities referred to as translationese. Previous research has shown that these translation artifacts influence the performance of a variety of cross-lingual tasks. In this work, we propose a novel approach to reducing translationese by extending an established bias-removal technique. We use the Iterative Null-space Projection (INLP) algorithm, and show by measuring classification accuracy before and after debiasing, that translationese is reduced at both sentence and word level. We evaluate the utility of debiasing translationese on a natural language inference (NLI) task, and show that by reducing this bias, NLI accuracy improves. To the best of our knowledge, this is the first study to debias translationese as represented in latent embedding space.
Comparing Feature-Engineering and Feature-Learning Approaches for Multilingual Translationese Classification
Sep 15, 2021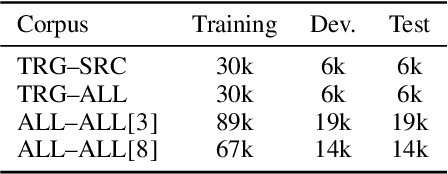
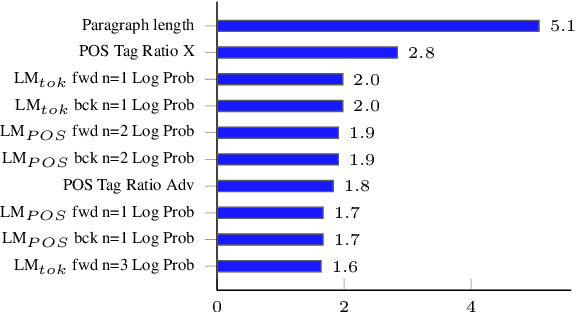
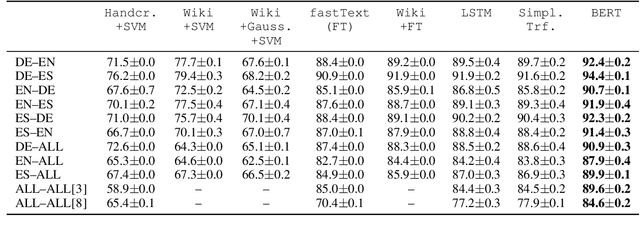
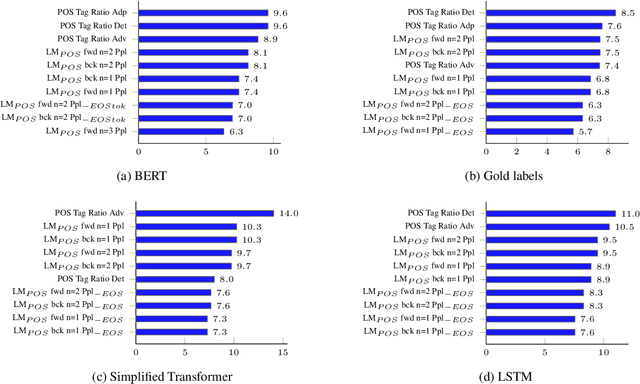
Traditional hand-crafted linguistically-informed features have often been used for distinguishing between translated and original non-translated texts. By contrast, to date, neural architectures without manual feature engineering have been less explored for this task. In this work, we (i) compare the traditional feature-engineering-based approach to the feature-learning-based one and (ii) analyse the neural architectures in order to investigate how well the hand-crafted features explain the variance in the neural models' predictions. We use pre-trained neural word embeddings, as well as several end-to-end neural architectures in both monolingual and multilingual settings and compare them to feature-engineering-based SVM classifiers. We show that (i) neural architectures outperform other approaches by more than 20 accuracy points, with the BERT-based model performing the best in both the monolingual and multilingual settings; (ii) while many individual hand-crafted translationese features correlate with neural model predictions, feature importance analysis shows that the most important features for neural and classical architectures differ; and (iii) our multilingual experiments provide empirical evidence for translationese universals across languages.