 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Sentiment Aware Text Summarization A Reinforcement Learning Approach for Consistency Maintenance
Jun 08, 2026Reinforcement Learning from Human Feedback (RLHF) has significantly improved the quality and fluency of large language models in text summarization. However, its impact on affective properties remains insufficiently understood. In this work, we study sentiment drift, a systematic shift toward neutral sentiment in RLHF-based summarization outputs compared to source texts. We conduct extensive experiments across multiple datasets, model architectures, and eight languages to analyze how alignment objectives influence sentiment preservation. Our results show that sentiment drift is a consistent phenomenon that becomes stronger with increased KL regularization strength, indicating a trade-off between alignment stability and affective fidelity. To explain this behavior, we introduce a Policy Attribution framework that decomposes the RLHF objective and quantifies the contribution of its components. Our analysis reveals that KL regularization is the primary driver of sentiment suppression across all settings. Based on these findings, we propose a sentiment-aware modification of the KL regularization term, which selectively reduces constraints on sentiment-bearing tokens. Empirical results demonstrate that this approach mitigates sentiment drift while maintaining summarization quality. Overall, our findings highlight a fundamental limitation of current alignment methods: while they improve factual consistency and safety, they may unintentionally suppress emotional expressiveness. This motivates the development of alignment strategies that explicitly account for affective preservation.
Beyond Majority Voting: Agreement-Based Clustering to Model Annotator Perspectives in Subjective NLP Tasks
May 11, 2026Disagreement in annotation is a common phenomenon in the development of NLP datasets and serves as a valuable source of insight. While majority voting remains the dominant strategy for aggregating labels, recent work has explored modeling individual annotators to preserve their perspectives. However, modeling each annotator is resource-intensive and remains underexplored across various NLP tasks. We propose an agreement-based clustering technique to model the disagreement between the annotators. We conduct comprehensive experiments in 40 datasets in 18 typologically diverse languages, covering three subjective NLP tasks: sentiment analysis, emotion classification, and hate speech detection. We evaluate four aggregation approaches: majority vote, ensemble, multi-label, and multitask. The results demonstrate that agreement-based clustering can leverage the full spectrum of annotator perspectives and significantly enhance classification performance in subjective NLP tasks compared to majority voting and individual annotator modeling. Regarding the aggregation approach, the multi-label and multitask approaches are better for modeling clustered annotators than an ensemble and model majority vote.
Decoding Market Emotions in Cryptocurrency Tweets via Predictive Statement Classification with Machine Learning and Transformers
Mar 26, 2026The growing prominence of cryptocurrencies has triggered widespread public engagement and increased speculative activity, particularly on social media platforms. This study introduces a novel classification framework for identifying predictive statements in cryptocurrency-related tweets, focusing on five popular cryptocurrencies: Cardano, Matic, Binance, Ripple, and Fantom. The classification process is divided into two stages: Task 1 involves binary classification to distinguish between Predictive and Non-Predictive statements. Tweets identified as Predictive proceed to Task 2, where they are further categorized as Incremental, Decremental, or Neutral. To build a robust dataset, we combined manual and GPT-based annotation methods and utilized SenticNet to extract emotion features corresponding to each prediction category. To address class imbalance, GPT-generated paraphrasing was employed for data augmentation. We evaluated a wide range of machine learning, deep learning, and transformer-based models across both tasks. The results show that GPT-based balancing significantly enhanced model performance, with transformer models achieving the highest F1-score in Task 1, while traditional machine learning models performed best in Task 2. Furthermore, our emotion analysis revealed distinct emotional patterns associated with each prediction category across the different cryptocurrencies.
Hybrid Extractive Abstractive Summarization for Multilingual Sentiment Analysis
Jun 07, 2025We propose a hybrid approach for multilingual sentiment analysis that combines extractive and abstractive summarization to address the limitations of standalone methods. The model integrates TF-IDF-based extraction with a fine-tuned XLM-R abstractive module, enhanced by dynamic thresholding and cultural adaptation. Experiments across 10 languages show significant improvements over baselines, achieving 0.90 accuracy for English and 0.84 for low-resource languages. The approach also demonstrates 22% greater computational efficiency than traditional methods. Practical applications include real-time brand monitoring and cross-cultural discourse analysis. Future work will focus on optimization for low-resource languages via 8-bit quantization.
Multilingual Sentiment Analysis of Summarized Texts: A Cross-Language Study of Text Shortening Effects
Mar 31, 2025Summarization significantly impacts sentiment analysis across languages with diverse morphologies. This study examines extractive and abstractive summarization effects on sentiment classification in English, German, French, Spanish, Italian, Finnish, Hungarian, and Arabic. We assess sentiment shifts post-summarization using multilingual transformers (mBERT, XLM-RoBERTa, T5, and BART) and language-specific models (FinBERT, AraBERT). Results show extractive summarization better preserves sentiment, especially in morphologically complex languages, while abstractive summarization improves readability but introduces sentiment distortion, affecting sentiment accuracy. Languages with rich inflectional morphology, such as Finnish, Hungarian, and Arabic, experience greater accuracy drops than English or German. Findings emphasize the need for language-specific adaptations in sentiment analysis and propose a hybrid summarization approach balancing readability and sentiment preservation. These insights benefit multilingual sentiment applications, including social media monitoring, market analysis, and cross-lingual opinion mining.
Advancing Sentiment Analysis in Tamil-English Code-Mixed Texts: Challenges and Transformer-Based Solutions
Mar 30, 2025



The sentiment analysis task in Tamil-English code-mixed texts has been explored using advanced transformer-based models. Challenges from grammatical inconsistencies, orthographic variations, and phonetic ambiguities have been addressed. The limitations of existing datasets and annotation gaps have been examined, emphasizing the need for larger and more diverse corpora. Transformer architectures, including XLM-RoBERTa, mT5, IndicBERT, and RemBERT, have been evaluated in low-resource, code-mixed environments. Performance metrics have been analyzed, highlighting the effectiveness of specific models in handling multilingual sentiment classification. The findings suggest that further advancements in data augmentation, phonetic normalization, and hybrid modeling approaches are required to enhance accuracy. Future research directions for improving sentiment analysis in code-mixed texts have been proposed.
Advanced Machine Learning Techniques for Social Support Detection on Social Media
Jan 06, 2025



The widespread use of social media highlights the need to understand its impact, particularly the role of online social support. This study uses a dataset focused on online social support, which includes binary and multiclass classifications of social support content on social media. The classification of social support is divided into three tasks. The first task focuses on distinguishing between supportive and non-supportive. The second task aims to identify whether the support is directed toward an individual or a group. The third task categorizes the specific type of social support, grouping it into categories such as Nation, LGBTQ, Black people, Women, Religion, and Other (if it does not fit into the previously mentioned categories). To address data imbalances in these tasks, we employed K-means clustering for balancing the dataset and compared the results with the original unbalanced data. Using advanced machine learning techniques, including transformers and zero-shot learning approaches with GPT3, GPT4, and GPT4-o, we predict social support levels in various contexts. The effectiveness of the dataset is evaluated using baseline models across different learning approaches, with transformer-based methods demonstrating superior performance. Additionally, we achieved a 0.4\% increase in the macro F1 score for the second task and a 0.7\% increase for the third task, compared to previous work utilizing traditional machine learning with psycholinguistic and unigram-based TF-IDF values.
Evaluating the Capabilities of Large Language Models for Multi-label Emotion Understanding
Dec 17, 2024Large Language Models (LLMs) show promising learning and reasoning abilities. Compared to other NLP tasks, multilingual and multi-label emotion evaluation tasks are under-explored in LLMs. In this paper, we present EthioEmo, a multi-label emotion classification dataset for four Ethiopian languages, namely, Amharic (amh), Afan Oromo (orm), Somali (som), and Tigrinya (tir). We perform extensive experiments with an additional English multi-label emotion dataset from SemEval 2018 Task 1. Our evaluation includes encoder-only, encoder-decoder, and decoder-only language models. We compare zero and few-shot approaches of LLMs to fine-tuning smaller language models. The results show that accurate multi-label emotion classification is still insufficient even for high-resource languages such as English, and there is a large gap between the performance of high-resource and low-resource languages. The results also show varying performance levels depending on the language and model type. EthioEmo is available publicly to further improve the understanding of emotions in language models and how people convey emotions through various languages.
Ethio-Fake: Cutting-Edge Approaches to Combat Fake News in Under-Resourced Languages Using Explainable AI
Oct 03, 2024
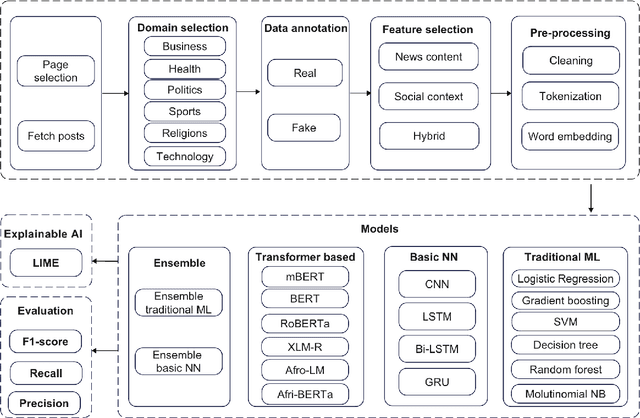
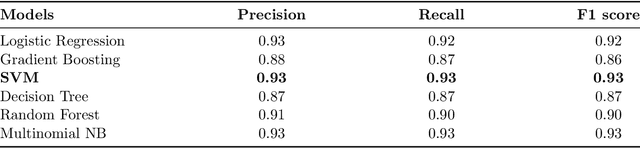

The proliferation of fake news has emerged as a significant threat to the integrity of information dissemination, particularly on social media platforms. Misinformation can spread quickly due to the ease of creating and disseminating content, affecting public opinion and sociopolitical events. Identifying false information is therefore essential to reducing its negative consequences and maintaining the reliability of online news sources. Traditional approaches to fake news detection often rely solely on content-based features, overlooking the crucial role of social context in shaping the perception and propagation of news articles. In this paper, we propose a comprehensive approach that integrates social context-based features with news content features to enhance the accuracy of fake news detection in under-resourced languages. We perform several experiments utilizing a variety of methodologies, including traditional machine learning, neural networks, ensemble learning, and transfer learning. Assessment of the outcomes of the experiments shows that the ensemble learning approach has the highest accuracy, achieving a 0.99 F1 score. Additionally, when compared with monolingual models, the fine-tuned model with the target language outperformed others, achieving a 0.94 F1 score. We analyze the functioning of the models, considering the important features that contribute to model performance, using explainable AI techniques.
Exploring Sentiment Dynamics and Predictive Behaviors in Cryptocurrency Discussions by Few-Shot Learning with Large Language Models
Sep 04, 2024



This study performs analysis of Predictive statements, Hope speech, and Regret Detection behaviors within cryptocurrency-related discussions, leveraging advanced natural language processing techniques. We introduce a novel classification scheme named "Prediction statements," categorizing comments into Predictive Incremental, Predictive Decremental, Predictive Neutral, or Non-Predictive categories. Employing GPT-4o, a cutting-edge large language model, we explore sentiment dynamics across five prominent cryptocurrencies: Cardano, Binance, Matic, Fantom, and Ripple. Our analysis reveals distinct patterns in predictive sentiments, with Matic demonstrating a notably higher propensity for optimistic predictions. Additionally, we investigate hope and regret sentiments, uncovering nuanced interplay between these emotions and predictive behaviors. Despite encountering limitations related to data volume and resource availability, our study reports valuable discoveries concerning investor behavior and sentiment trends within the cryptocurrency market, informing strategic decision-making and future research endeavors.