 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph2Counsel: Clinically Grounded Synthetic Counseling Dialogue Generation from Client Psychological Graphs
Apr 22, 2026Rising demand for mental health support has increased interest in using Large Language Models (LLMs) for counseling. However, adapting LLMs to this high-risk safety-critical domain is hindered by the scarcity of real-world counseling data due to privacy constraints. Synthetic datasets provide a promising alternative, but existing approaches often rely on unstructured or semi-structured text inputs and overlook structural dependencies between a client's cognitive, emotional, and behavioral states, often producing psychologically inconsistent interactions and reducing data realism and quality. We introduce Graph2Counsel, a framework for generating synthetic counseling sessions grounded in Client Psychological Graphs (CPGs) that encode relationships among clients' thoughts, emotions, and behaviors. Graph2Counsel employs a structured prompting pipeline guided by counselor strategies and CPG, and explores prompting strategies including CoT (Wei et al., 2022) and Multi-Agent Feedback (Li et al., 2025a). Graph2Counsel produces 760 sessions from 76 CPGs across diverse client profiles. In expert evaluation, our dataset outperforms prior datasets on specificity, counselor competence, authenticity, conversational flow, and safety, with substantial inter-annotator agreement (Krippendorff's $α$ = 0.70). Fine-tuning an open-source model on this dataset improves performance on CounselingBench (Nguyen et al., 2025) and CounselBench (Li et al., 2025b), showing downstream utility. We also make our code and data public.
MAGneT: Coordinated Multi-Agent Generation of Synthetic Multi-Turn Mental Health Counseling Sessions
Sep 04, 2025The growing demand for scalable psychological counseling highlights the need for fine-tuning open-source Large Language Models (LLMs) with high-quality, privacy-compliant data, yet such data remains scarce. Here we introduce MAGneT, a novel multi-agent framework for synthetic psychological counseling session generation that decomposes counselor response generation into coordinated sub-tasks handled by specialized LLM agents, each modeling a key psychological technique. Unlike prior single-agent approaches, MAGneT better captures the structure and nuance of real counseling. In addition, we address inconsistencies in prior evaluation protocols by proposing a unified evaluation framework integrating diverse automatic and expert metrics. Furthermore, we expand the expert evaluations from four aspects of counseling in previous works to nine aspects, enabling a more thorough and robust assessment of data quality. Empirical results show that MAGneT significantly outperforms existing methods in quality, diversity, and therapeutic alignment of the generated counseling sessions, improving general counseling skills by 3.2% and CBT-specific skills by 4.3% on average on cognitive therapy rating scale (CTRS). Crucially, experts prefer MAGneT-generated sessions in 77.2% of cases on average across all aspects. Moreover, fine-tuning an open-source model on MAGneT-generated sessions shows better performance, with improvements of 6.3% on general counseling skills and 7.3% on CBT-specific skills on average on CTRS over those fine-tuned with sessions generated by baseline methods. We also make our code and data public.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
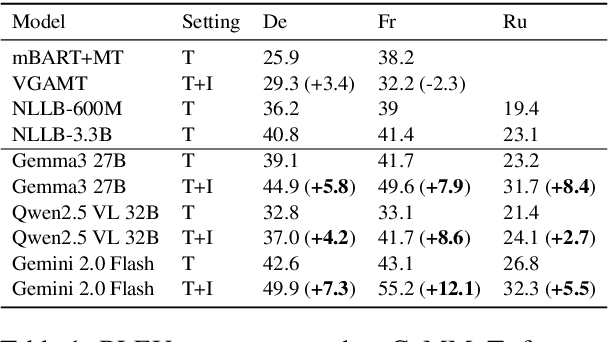

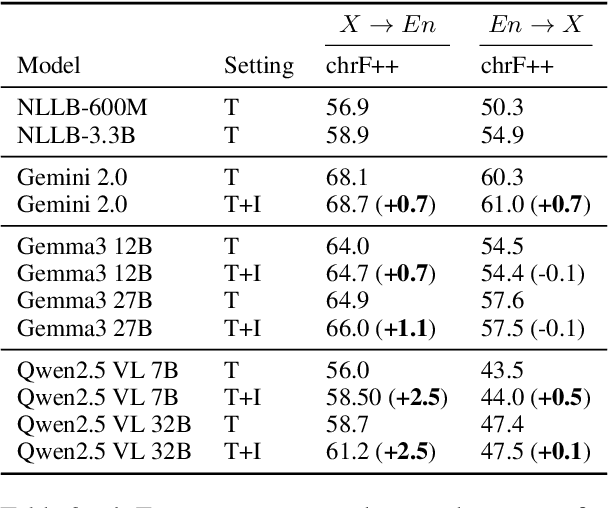
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
Enhancing Depression Detection via Question-wise Modality Fusion
Mar 26, 2025



Depression is a highly prevalent and disabling condition that incurs substantial personal and societal costs. Current depression diagnosis involves determining the depression severity of a person through self-reported questionnaires or interviews conducted by clinicians. This often leads to delayed treatment and involves substantial human resources. Thus, several works try to automate the process using multimodal data. However, they usually overlook the following: i) The variable contribution of each modality for each question in the questionnaire and ii) Using ordinal classification for the task. This results in sub-optimal fusion and training methods. In this work, we propose a novel Question-wise Modality Fusion (QuestMF) framework trained with a novel Imbalanced Ordinal Log-Loss (ImbOLL) function to tackle these issues. The performance of our framework is comparable to the current state-of-the-art models on the E-DAIC dataset and enhances interpretability by predicting scores for each question. This will help clinicians identify an individual's symptoms, allowing them to customise their interventions accordingly. We also make the code for the QuestMF framework publicly available.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
A Revenue Function for Comparison-Based Hierarchical Clustering
Nov 29, 2022



Comparison-based learning addresses the problem of learning when, instead of explicit features or pairwise similarities, one only has access to comparisons of the form: \emph{Object $A$ is more similar to $B$ than to $C$.} Recently, it has been shown that, in Hierarchical Clustering, single and complete linkage can be directly implemented using only such comparisons while several algorithms have been proposed to emulate the behaviour of average linkage. Hence, finding hierarchies (or dendrograms) using only comparisons is a well understood problem. However, evaluating their meaningfulness when no ground-truth nor explicit similarities are available remains an open question. In this paper, we bridge this gap by proposing a new revenue function that allows one to measure the goodness of dendrograms using only comparisons. We show that this function is closely related to Dasgupta's cost for hierarchical clustering that uses pairwise similarities. On the theoretical side, we use the proposed revenue function to resolve the open problem of whether one can approximately recover a latent hierarchy using few triplet comparisons. On the practical side, we present principled algorithms for comparison-based hierarchical clustering based on the maximisation of the revenue and we empirically compare them with existing methods.
Representation Learning for Conversational Data using Discourse Mutual Information Maximization
Dec 04, 2021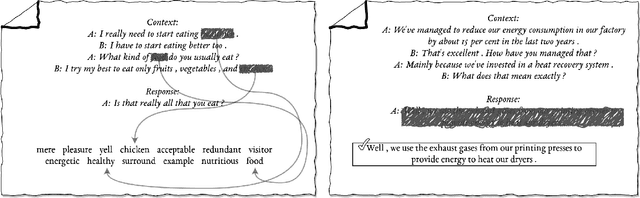
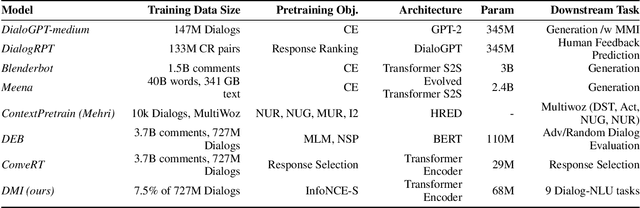
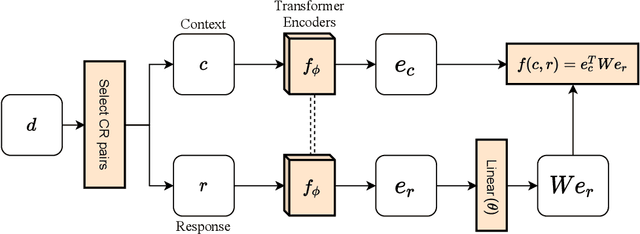

Although many pretrained models exist for text or images, there have been relatively fewer attempts to train representations specifically for dialog understanding. Prior works usually relied on finetuned representations based on generic text representation models like BERT or GPT-2. But, existing pretraining objectives do not take the structural information of text into consideration. Although generative dialog models can learn structural features too, we argue that the structure-unaware word-by-word generation is not suitable for effective conversation modeling. We empirically demonstrate that such representations do not perform consistently across various dialog understanding tasks. Hence, we propose a structure-aware Mutual Information based loss-function DMI (Discourse Mutual Information) for training dialog-representation models, that additionally captures the inherent uncertainty in response prediction. Extensive evaluation on nine diverse dialog modeling tasks shows that our proposed DMI-based models outperform strong baselines by significant margins, even with small-scale pretraining. Our models show the most promising performance on the dialog evaluation task DailyDialog++, in both random and adversarial negative scenarios.
Knowledge-Aware Neural Networks for Medical Forum Question Classification
Sep 27, 2021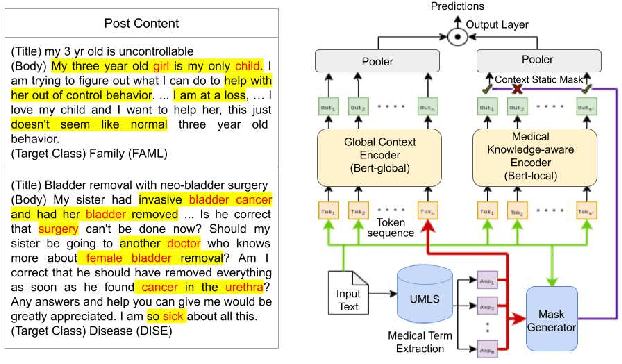
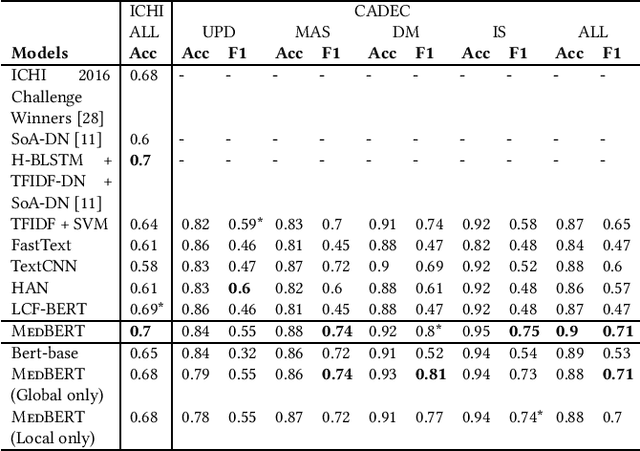
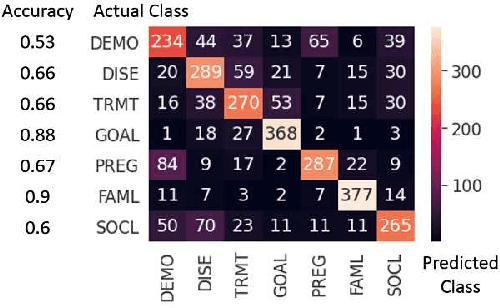
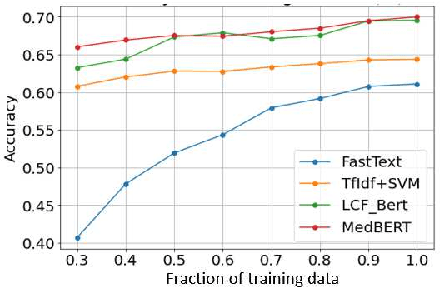
Online medical forums have become a predominant platform for answering health-related information needs of consumers. However, with a significant rise in the number of queries and the limited availability of experts, it is necessary to automatically classify medical queries based on a consumer's intention, so that these questions may be directed to the right set of medical experts. Here, we develop a novel medical knowledge-aware BERT-based model (MedBERT) that explicitly gives more weightage to medical concept-bearing words, and utilize domain-specific side information obtained from a popular medical knowledge base. We also contribute a multi-label dataset for the Medical Forum Question Classification (MFQC) task. MedBERT achieves state-of-the-art performance on two benchmark datasets and performs very well in low resource settings.