 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperMemory-VQA: An Egocentric Visual Question-Answering Benchmark for Long-Horizon Memory
May 30, 2026AI glasses present a compelling platform for AI agents to serve as personalized memory assistants. To be genuinely useful, such systems must move beyond short-term video comprehension and address memory gaps that humans experience for practical, personal, or social purposes over longitudinal egocentric video streams. However, existing egocentric datasets predominantly focus on action recognition or generic QAs from short clips, measuring perceptual capabilities rather than realistic human memory needs. We introduce SuperMemory-VQA, an egocentric visual question answering (VQA) dataset for evaluating AI assistants on practical, long-horizon memory tasks. It contains 52.9 hours of everyday activities recorded with AI glasses, including synchronized RGB video, audio transcription, eye gaze, IMU, and SLAM trajectories. Through a human-verified annotation pipeline, we construct grounded 4,853 question-answer pairs that span object and location memory, intent recall, visual scene recall, timeline reconstruction, conversational memory, and in-context retrieval. Each question is posed as multiple-choice with an explicit "unanswerable" option to test hallucination robustness. Benchmarking leading agentic frameworks and LLM backbones reveals that existing systems remain far from reliable on real-world memory tasks, highlighting the need for new architectures for grounded AI memory that can answer only when evidence is sufficient. A participant survey further supports that our questions are realistic, useful, and aligned with everyday memory needs.
The ASIR Courage Model: A Phase-Dynamic Framework for Truth Transitions in Human and AI Systems
Feb 25, 2026We introduce the ASIR (Awakened Shared Intelligence Relationship) Courage Model, a phase-dynamic framework that formalizes truth-disclosure as a state transition rather than a personality trait. The mode characterizes the shift from suppression (S0) to expression (S1) as occurring when facilitative forces exceed inhibitory thresholds, expressed by the inequality lambda(1+gamma)+psi > theta+phi, where the terms represent baseline openness, relational amplification, accumulated internal pressure, and transition costs. Although initially formulated for human truth-telling under asymmetric stakes, the same phase-dynamic architecture extends to AI systems operating under policy constraints and alignment filters. In this context, suppression corresponds to constrained output states, while structural pressure arises from competing objectives, contextual tension, and recursive interaction dynamics. The framework therefore provides a unified structural account of both human silence under pressure and AI preference-driven distortion. A feedback extension models how transition outcomes recursively recalibrate system parameters, generating path dependence and divergence effects across repeated interactions. Rather than attributing intention to AI systems, the model interprets shifts in apparent truthfulness as geometric consequences of interacting forces within constrained phase space. By reframing courage and alignment within a shared dynamical structure, the ASIR Courage Model offers a formal perspective on truth-disclosure under risk across both human and artificial systems.
Agentic Very Long Video Understanding
Jan 26, 2026The advent of always-on personal AI assistants, enabled by all-day wearable devices such as smart glasses, demands a new level of contextual understanding, one that goes beyond short, isolated events to encompass the continuous, longitudinal stream of egocentric video. Achieving this vision requires advances in long-horizon video understanding, where systems must interpret and recall visual and audio information spanning days or even weeks. Existing methods, including large language models and retrieval-augmented generation, are constrained by limited context windows and lack the ability to perform compositional, multi-hop reasoning over very long video streams. In this work, we address these challenges through EGAgent, an enhanced agentic framework centered on entity scene graphs, which represent people, places, objects, and their relationships over time. Our system equips a planning agent with tools for structured search and reasoning over these graphs, as well as hybrid visual and audio search capabilities, enabling detailed, cross-modal, and temporally coherent reasoning. Experiments on the EgoLifeQA and Video-MME (Long) datasets show that our method achieves state-of-the-art performance on EgoLifeQA (57.5%) and competitive performance on Video-MME (Long) (74.1%) for complex longitudinal video understanding tasks.
Reading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
EgoLM: Multi-Modal Language Model of Egocentric Motions
Sep 26, 2024



As the prevalence of wearable devices, learning egocentric motions becomes essential to develop contextual AI. In this work, we present EgoLM, a versatile framework that tracks and understands egocentric motions from multi-modal inputs, e.g., egocentric videos and motion sensors. EgoLM exploits rich contexts for the disambiguation of egomotion tracking and understanding, which are ill-posed under single modality conditions. To facilitate the versatile and multi-modal framework, our key insight is to model the joint distribution of egocentric motions and natural languages using large language models (LLM). Multi-modal sensor inputs are encoded and projected to the joint latent space of language models, and used to prompt motion generation or text generation for egomotion tracking or understanding, respectively. Extensive experiments on large-scale multi-modal human motion dataset validate the effectiveness of EgoLM as a generalist model for universal egocentric learning.
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
Jun 14, 2024We introduce Nymeria - a large-scale, diverse, richly annotated human motion dataset collected in the wild with multiple multimodal egocentric devices. The dataset comes with a) full-body 3D motion ground truth; b) egocentric multimodal recordings from Project Aria devices with RGB, grayscale, eye-tracking cameras, IMUs, magnetometer, barometer, and microphones; and c) an additional "observer" device providing a third-person viewpoint. We compute world-aligned 6DoF transformations for all sensors, across devices and capture sessions. The dataset also provides 3D scene point clouds and calibrated gaze estimation. We derive a protocol to annotate hierarchical language descriptions of in-context human motion, from fine-grain pose narrations, to atomic actions and activity summarization. To the best of our knowledge, the Nymeria dataset is the world largest in-the-wild collection of human motion with natural and diverse activities; first of its kind to provide synchronized and localized multi-device multimodal egocentric data; and the world largest dataset with motion-language descriptions. It contains 1200 recordings of 300 hours of daily activities from 264 participants across 50 locations, travelling a total of 399Km. The motion-language descriptions provide 310.5K sentences in 8.64M words from a vocabulary size of 6545. To demonstrate the potential of the dataset we define key research tasks for egocentric body tracking, motion synthesis, and action recognition and evaluate several state-of-the-art baseline algorithms. Data and code will be open-sourced.
NinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
Dec 23, 2021
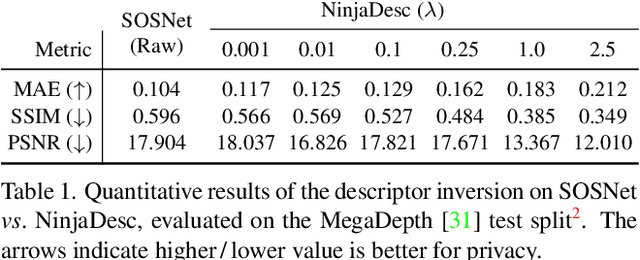
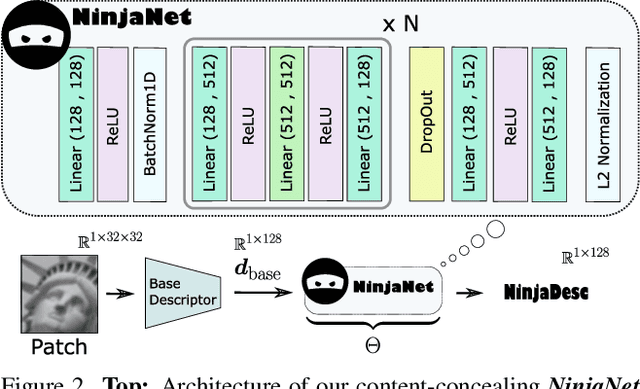
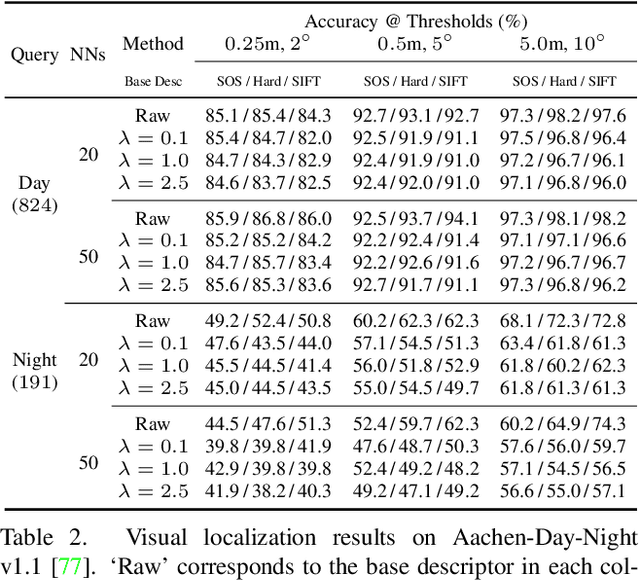
In the light of recent analyses on privacy-concerning scene revelation from visual descriptors, we develop descriptors that conceal the input image content. In particular, we propose an adversarial learning framework for training visual descriptors that prevent image reconstruction, while maintaining the matching accuracy. We let a feature encoding network and image reconstruction network compete with each other, such that the feature encoder tries to impede the image reconstruction with its generated descriptors, while the reconstructor tries to recover the input image from the descriptors. The experimental results demonstrate that the visual descriptors obtained with our method significantly deteriorate the image reconstruction quality with minimal impact on correspondence matching and camera localization performance.
Analysis and Mitigations of Reverse Engineering Attacks on Local Feature Descriptors
May 09, 2021
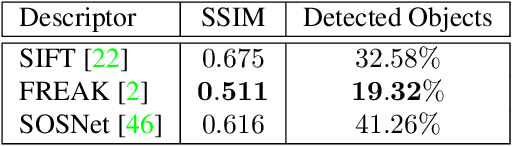
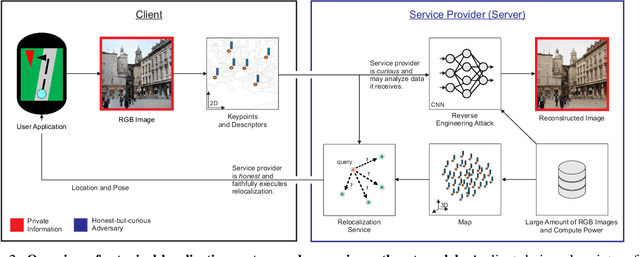
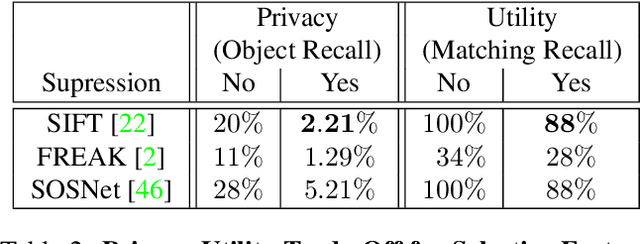
As autonomous driving and augmented reality evolve, a practical concern is data privacy. In particular, these applications rely on localization based on user images. The widely adopted technology uses local feature descriptors, which are derived from the images and it was long thought that they could not be reverted back. However, recent work has demonstrated that under certain conditions reverse engineering attacks are possible and allow an adversary to reconstruct RGB images. This poses a potential risk to user privacy. We take this a step further and model potential adversaries using a privacy threat model. Subsequently, we show under controlled conditions a reverse engineering attack on sparse feature maps and analyze the vulnerability of popular descriptors including FREAK, SIFT and SOSNet. Finally, we evaluate potential mitigation techniques that select a subset of descriptors to carefully balance privacy reconstruction risk while preserving image matching accuracy; our results show that similar accuracy can be obtained when revealing less information.
Domain Adaptation of Learned Features for Visual Localization
Aug 21, 2020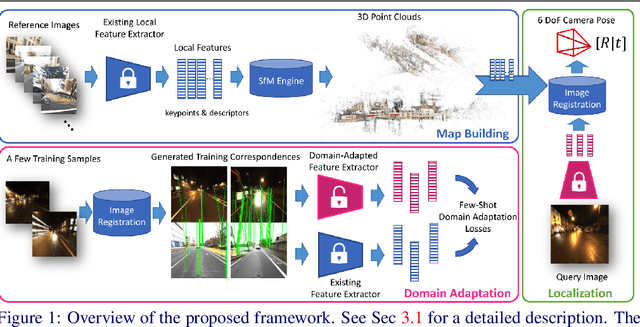

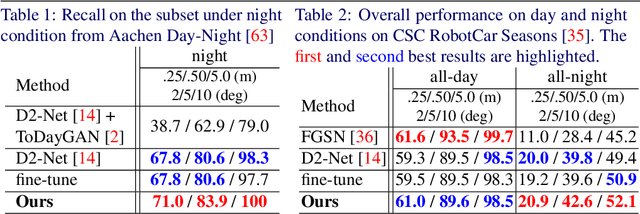
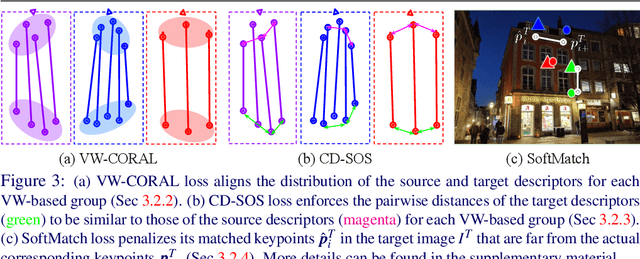
We tackle the problem of visual localization under changing conditions, such as time of day, weather, and seasons. Recent learned local features based on deep neural networks have shown superior performance over classical hand-crafted local features. However, in a real-world scenario, there often exists a large domain gap between training and target images, which can significantly degrade the localization accuracy. While existing methods utilize a large amount of data to tackle the problem, we present a novel and practical approach, where only a few examples are needed to reduce the domain gap. In particular, we propose a few-shot domain adaptation framework for learned local features that deals with varying conditions in visual localization. The experimental results demonstrate the superior performance over baselines, while using a scarce number of training examples from the target domain.