 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Stage: Spatial Layouts from Long-form Narratives
Mar 18, 2026In this work, we probe the ability of a language model to demonstrate spatial reasoning from unstructured text, mimicking human capabilities and automating a process that benefits many downstream media applications. Concretely, we study the narrative-to-play task: inferring stage-play layouts (scenes, speaker positions, movements, and room types) from text that lacks explicit spatial, positional, or relational cues. We then introduce a dramaturgy-inspired deterministic evaluation suite and, finally, a training and inference recipe that combines rejection SFT using Best-of-N sampling with RL from verifiable rewards via GRPO. Experiments on a text-only corpus of classical English literature demonstrate improvements over vanilla models across multiple metrics (character attribution, spatial plausibility, and movement economy), as well as alignment with an LLM-as-a-judge and subjective human preferences.
Agentic Very Long Video Understanding
Jan 26, 2026The advent of always-on personal AI assistants, enabled by all-day wearable devices such as smart glasses, demands a new level of contextual understanding, one that goes beyond short, isolated events to encompass the continuous, longitudinal stream of egocentric video. Achieving this vision requires advances in long-horizon video understanding, where systems must interpret and recall visual and audio information spanning days or even weeks. Existing methods, including large language models and retrieval-augmented generation, are constrained by limited context windows and lack the ability to perform compositional, multi-hop reasoning over very long video streams. In this work, we address these challenges through EGAgent, an enhanced agentic framework centered on entity scene graphs, which represent people, places, objects, and their relationships over time. Our system equips a planning agent with tools for structured search and reasoning over these graphs, as well as hybrid visual and audio search capabilities, enabling detailed, cross-modal, and temporally coherent reasoning. Experiments on the EgoLifeQA and Video-MME (Long) datasets show that our method achieves state-of-the-art performance on EgoLifeQA (57.5%) and competitive performance on Video-MME (Long) (74.1%) for complex longitudinal video understanding tasks.
LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing
Feb 15, 2024



Video creation has become increasingly popular, yet the expertise and effort required for editing often pose barriers to beginners. In this paper, we explore the integration of large language models (LLMs) into the video editing workflow to reduce these barriers. Our design vision is embodied in LAVE, a novel system that provides LLM-powered agent assistance and language-augmented editing features. LAVE automatically generates language descriptions for the user's footage, serving as the foundation for enabling the LLM to process videos and assist in editing tasks. When the user provides editing objectives, the agent plans and executes relevant actions to fulfill them. Moreover, LAVE allows users to edit videos through either the agent or direct UI manipulation, providing flexibility and enabling manual refinement of agent actions. Our user study, which included eight participants ranging from novices to proficient editors, demonstrated LAVE's effectiveness. The results also shed light on user perceptions of the proposed LLM-assisted editing paradigm and its impact on users' creativity and sense of co-creation. Based on these findings, we propose design implications to inform the future development of agent-assisted content editing.
Human-Centered Planning
Nov 08, 2023



LLMs have recently made impressive inroads on tasks whose output is structured, such as coding, robotic planning and querying databases. The vision of creating AI-powered personal assistants also involves creating structured outputs, such as a plan for one's day, or for an overseas trip. Here, since the plan is executed by a human, the output doesn't have to satisfy strict syntactic constraints. A useful assistant should also be able to incorporate vague constraints specified by the user in natural language. This makes LLMs an attractive option for planning. We consider the problem of planning one's day. We develop an LLM-based planner (LLMPlan) extended with the ability to self-reflect on its output and a symbolic planner (SymPlan) with the ability to translate text constraints into a symbolic representation. Despite no formal specification of constraints, we find that LLMPlan performs explicit constraint satisfaction akin to the traditional symbolic planners on average (2% performance difference), while retaining the reasoning of implicit requirements. Consequently, LLM-based planners outperform their symbolic counterparts in user satisfaction (70.5% vs. 40.4%) during interactive evaluation with 40 users.
Reimagining Retrieval Augmented Language Models for Answering Queries
Jun 01, 2023



We present a reality check on large language models and inspect the promise of retrieval augmented language models in comparison. Such language models are semi-parametric, where models integrate model parameters and knowledge from external data sources to make their predictions, as opposed to the parametric nature of vanilla large language models. We give initial experimental findings that semi-parametric architectures can be enhanced with views, a query analyzer/planner, and provenance to make a significantly more powerful system for question answering in terms of accuracy and efficiency, and potentially for other NLP tasks
TimelineQA: A Benchmark for Question Answering over Timelines
Jun 01, 2023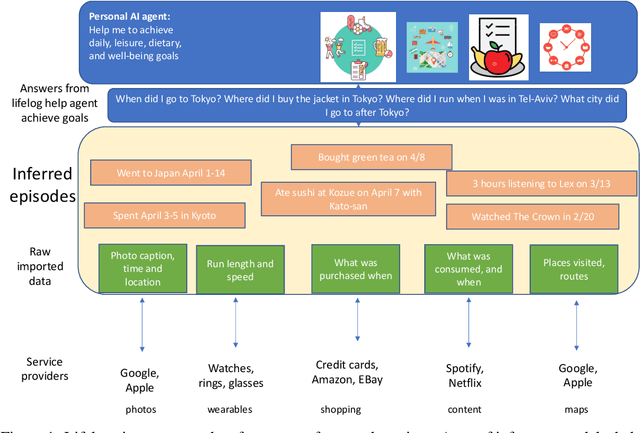

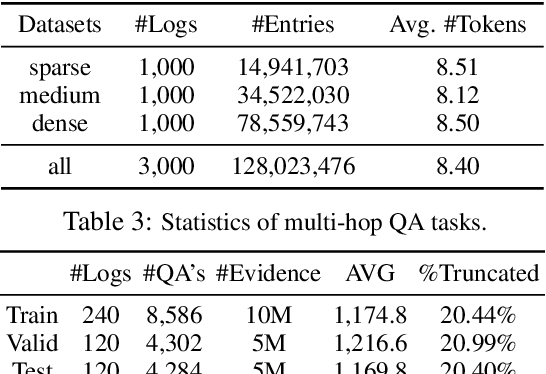
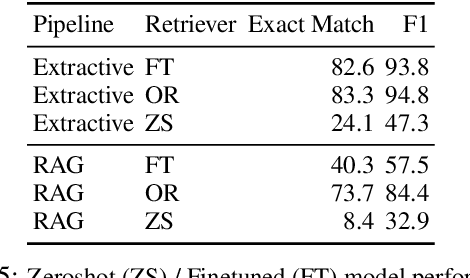
Lifelogs are descriptions of experiences that a person had during their life. Lifelogs are created by fusing data from the multitude of digital services, such as online photos, maps, shopping and content streaming services. Question answering over lifelogs can offer personal assistants a critical resource when they try to provide advice in context. However, obtaining answers to questions over lifelogs is beyond the current state of the art of question answering techniques for a variety of reasons, the most pronounced of which is that lifelogs combine free text with some degree of structure such as temporal and geographical information. We create and publicly release TimelineQA1, a benchmark for accelerating progress on querying lifelogs. TimelineQA generates lifelogs of imaginary people. The episodes in the lifelog range from major life episodes such as high school graduation to those that occur on a daily basis such as going for a run. We describe a set of experiments on TimelineQA with several state-of-the-art QA models. Our experiments reveal that for atomic queries, an extractive QA system significantly out-performs a state-of-the-art retrieval-augmented QA system. For multi-hop queries involving aggregates, we show that the best result is obtained with a state-of-the-art table QA technique, assuming the ground truth set of episodes for deriving the answer is available.
Region-wise matching for image inpainting based on adaptive weighted low-rank decomposition
Mar 22, 2023Digital image inpainting is an interpolation problem, inferring the content in the missing (unknown) region to agree with the known region data such that the interpolated result fulfills some prior knowledge. Low-rank and nonlocal self-similarity are two important priors for image inpainting. Based on the nonlocal self-similarity assumption, an image is divided into overlapped square target patches (submatrices) and the similar patches of any target patch are reshaped as vectors and stacked into a patch matrix. Such a patch matrix usually enjoys a property of low rank or approximately low rank, and its missing entries are recoveried by low-rank matrix approximation (LRMA) algorithms. Traditionally, $n$ nearest neighbor similar patches are searched within a local window centered at a target patch. However, for an image with missing lines, the generated patch matrix is prone to having entirely-missing rows such that the downstream low-rank model fails to reconstruct it well. To address this problem, we propose a region-wise matching (RwM) algorithm by dividing the neighborhood of a target patch into multiple subregions and then search the most similar one within each subregion. A non-convex weighted low-rank decomposition (NC-WLRD) model for LRMA is also proposed to reconstruct all degraded patch matrices grouped by the proposed RwM algorithm. We solve the proposed NC-WLRD model by the alternating direction method of multipliers (ADMM) and analyze the convergence in detail. Numerous experiments on line inpainting (entire-row/column missing) demonstrate the superiority of our method over other competitive inpainting algorithms. Unlike other low-rank-based matrix completion methods and inpainting algorithms, the proposed model NC-WLRD is also effective for removing random-valued impulse noise and structural noise (stripes).
Annotating Columns with Pre-trained Language Models
Apr 05, 2021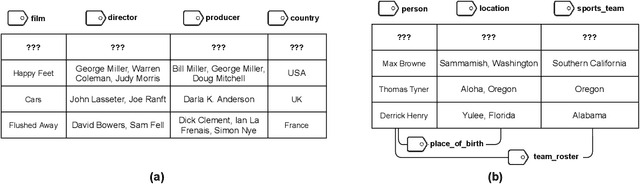
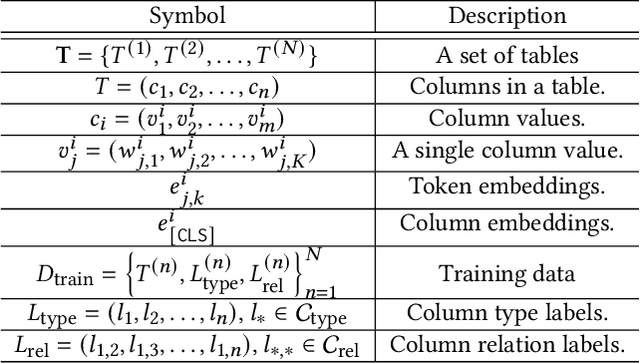
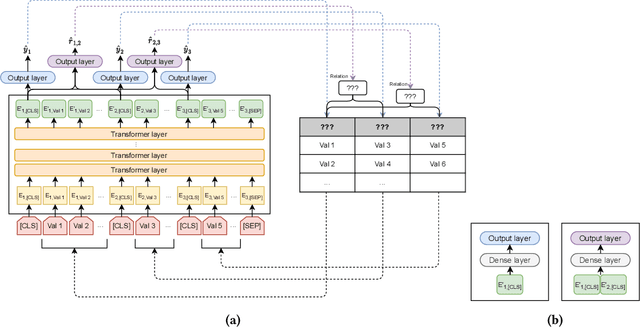
Inferring meta information about tables, such as column headers or relationships between columns, is an active research topic in data management as we find many tables are missing some of this information. In this paper, we study the problem of annotating table columns (i.e., predicting column types and the relationships between columns) using only information from the table itself. We show that a multi-task learning approach (called Doduo), trained using pre-trained language models on both tasks outperforms individual learning approaches. Experimental results show that Doduo establishes new state-of-the-art performance on two benchmarks for the column type prediction and column relation prediction tasks with up to 4.0% and 11.9% improvements, respectively. We also establish that Doduo can already perform the previous state-of-the-art performance with a minimal number of tokens, only 8 tokens per column.
Deep or Simple Models for Semantic Tagging? It Depends on your Data
Jul 11, 2020
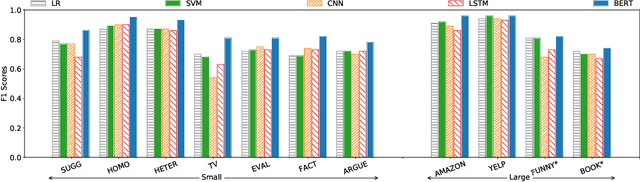
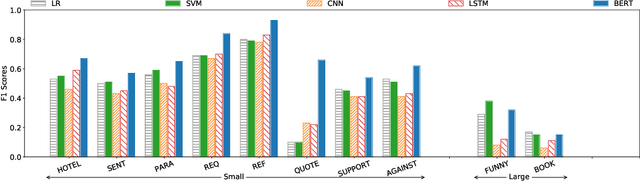
Semantic tagging, which has extensive applications in text mining, predicts whether a given piece of text conveys the meaning of a given semantic tag. The problem of semantic tagging is largely solved with supervised learning and today, deep learning models are widely perceived to be better for semantic tagging. However, there is no comprehensive study supporting the popular belief. Practitioners often have to train different types of models for each semantic tagging task to identify the best model. This process is both expensive and inefficient. We embark on a systematic study to investigate the following question: Are deep models the best performing model for all semantic tagging tasks? To answer this question, we compare deep models against "simple models" over datasets with varying characteristics. Specifically, we select three prevalent deep models (i.e. CNN, LSTM, and BERT) and two simple models (i.e. LR and SVM), and compare their performance on the semantic tagging task over 21 datasets. Results show that the size, the label ratio, and the label cleanliness of a dataset significantly impact the quality of semantic tagging. Simple models achieve similar tagging quality to deep models on large datasets, but the runtime of simple models is much shorter. Moreover, simple models can achieve better tagging quality than deep models when targeting datasets show worse label cleanliness and/or more severe imbalance. Based on these findings, our study can systematically guide practitioners in selecting the right learning model for their semantic tagging task.
ExplainIt: Explainable Review Summarization with Opinion Causality Graphs
May 29, 2020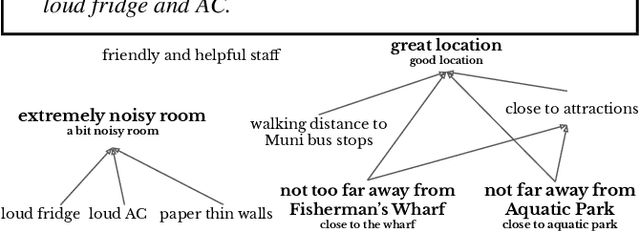


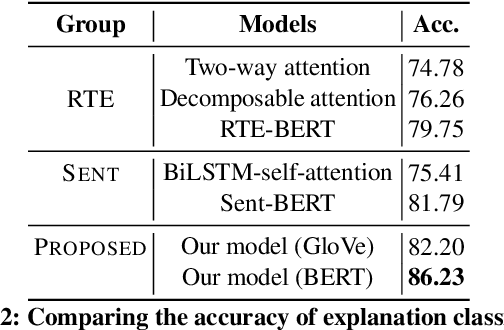
We present ExplainIt, a review summarization system centered around opinion explainability: the simple notion of high-level opinions (e.g. "noisy room") being explainable by lower-level ones (e.g., "loud fridge"). ExplainIt utilizes a combination of supervised and unsupervised components to mine the opinion phrases from reviews and organize them in an Opinion Causality Graph (OCG), a novel semi-structured representation which summarizes causal relations. To construct an OCG, we cluster semantically similar opinions in single nodes, thus canonicalizing opinion paraphrases, and draw directed edges between node pairs that are likely connected by a causal relation. OCGs can be used to generate structured summaries at different levels of granularity and for certain aspects of interest, while simultaneously providing explanations. In this paper, we present the system's individual components and evaluate their effectiveness on their respective sub-tasks, where we report substantial improvements over baselines across two domains. Finally, we validate these results with a user study, showing that ExplainIt produces reasonable opinion explanations according to human judges.