 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
Dec 23, 2021
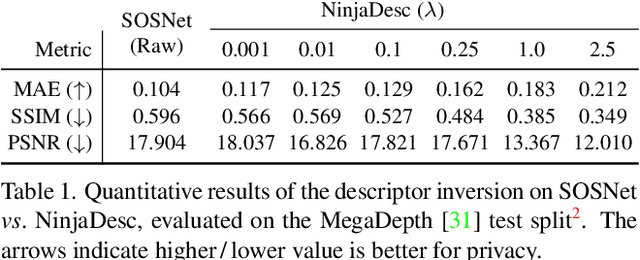
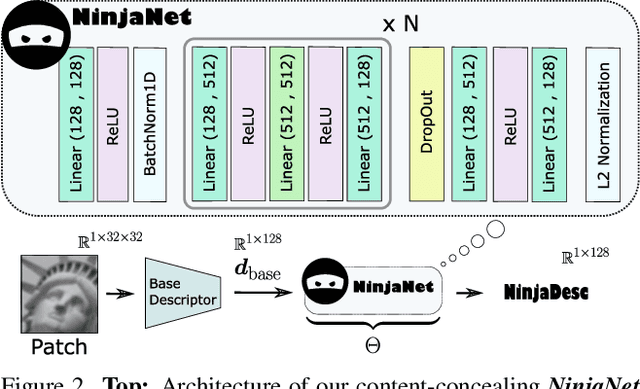
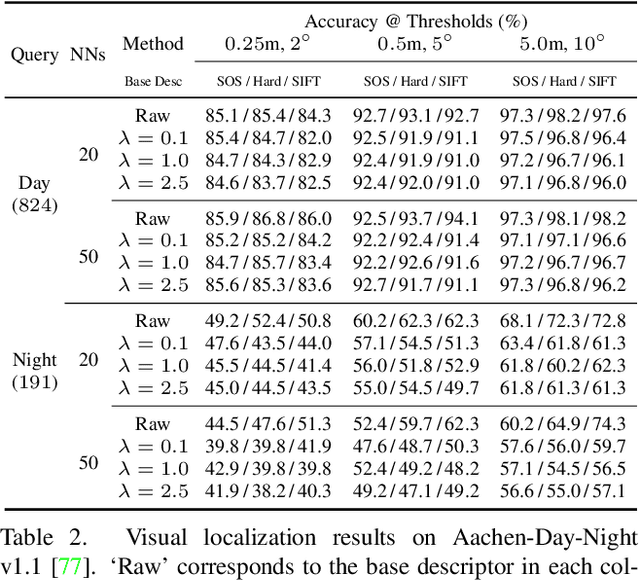
In the light of recent analyses on privacy-concerning scene revelation from visual descriptors, we develop descriptors that conceal the input image content. In particular, we propose an adversarial learning framework for training visual descriptors that prevent image reconstruction, while maintaining the matching accuracy. We let a feature encoding network and image reconstruction network compete with each other, such that the feature encoder tries to impede the image reconstruction with its generated descriptors, while the reconstructor tries to recover the input image from the descriptors. The experimental results demonstrate that the visual descriptors obtained with our method significantly deteriorate the image reconstruction quality with minimal impact on correspondence matching and camera localization performance.
Reassessing the Limitations of CNN Methods for Camera Pose Regression
Aug 16, 2021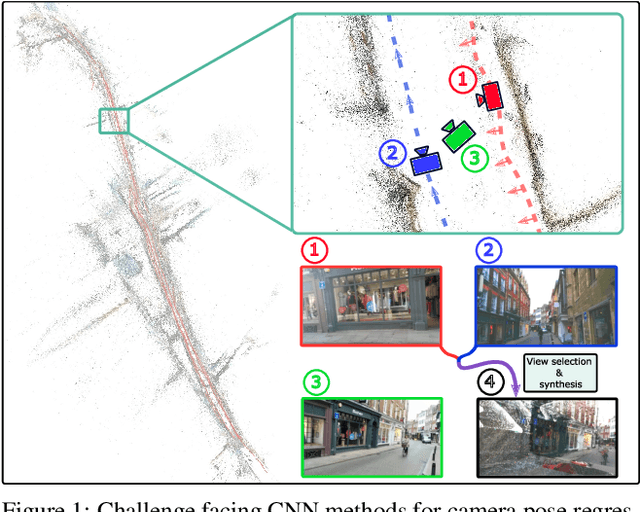

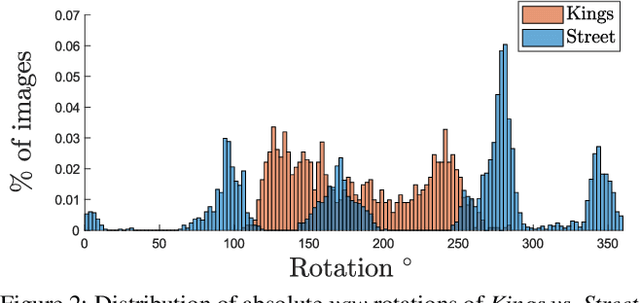
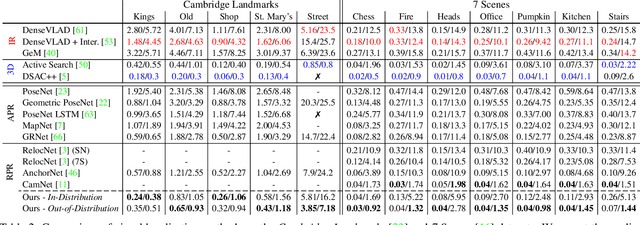
In this paper, we address the problem of camera pose estimation in outdoor and indoor scenarios. In comparison to the currently top-performing methods that rely on 2D to 3D matching, we propose a model that can directly regress the camera pose from images with significantly higher accuracy than existing methods of the same class. We first analyse why regression methods are still behind the state-of-the-art, and we bridge the performance gap with our new approach. Specifically, we propose a way to overcome the biased training data by a novel training technique, which generates poses guided by a probability distribution from the training set for synthesising new training views. Lastly, we evaluate our approach on two widely used benchmarks and show that it achieves significantly improved performance compared to prior regression-based methods, retrieval techniques as well as 3D pipelines with local feature matching.
HyNet: Local Descriptor with Hybrid Similarity Measure and Triplet Loss
Jun 17, 2020
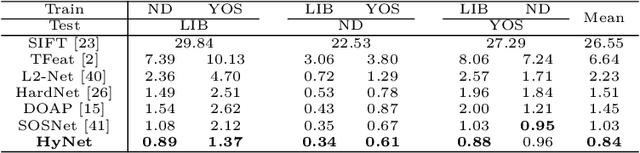
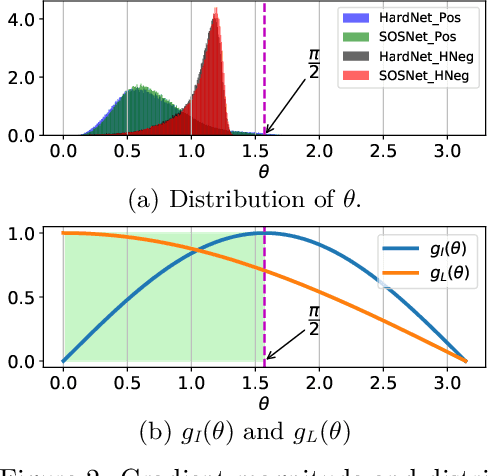
Recent works show that local descriptor learning benefits from the use of L2 normalisation, however, an in-depth analysis of this effect lacks in the literature. In this paper, we investigate how L2 normalisation affects the back-propagated descriptor gradients during training. Based on our observations, we propose HyNet, a new local descriptor that leads to state-of-the-art results in matching. HyNet introduces a hybrid similarity measure for triplet margin loss, a regularisation term constraining the descriptor norm, and a new network architecture that performs L2 normalisation of all intermediate feature maps and the output descriptors. HyNet surpasses previous methods by a significant margin on standard benchmarks that include patch matching, verification, and retrieval, as well as outperforming full end-to-end methods on 3D reconstruction tasks.
D2D: Keypoint Extraction with Describe to Detect Approach
May 27, 2020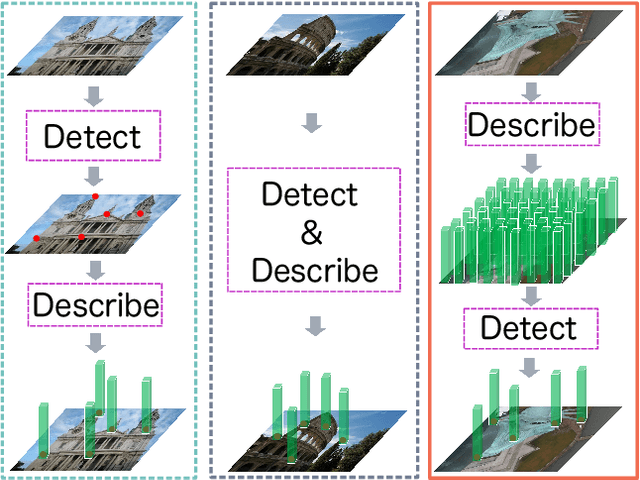
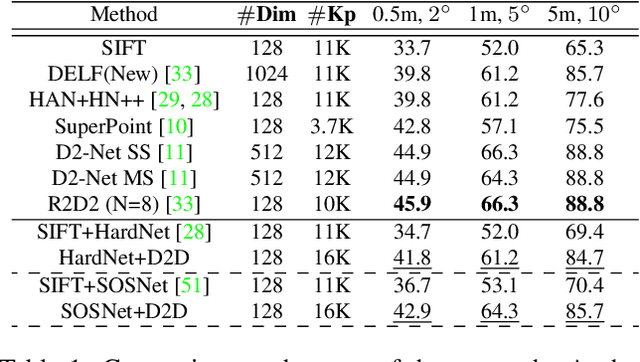
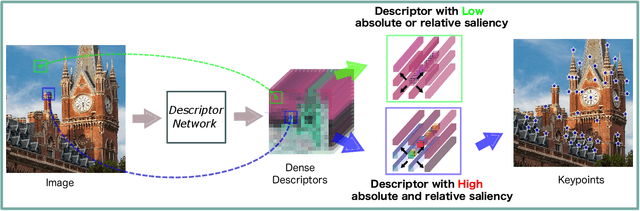
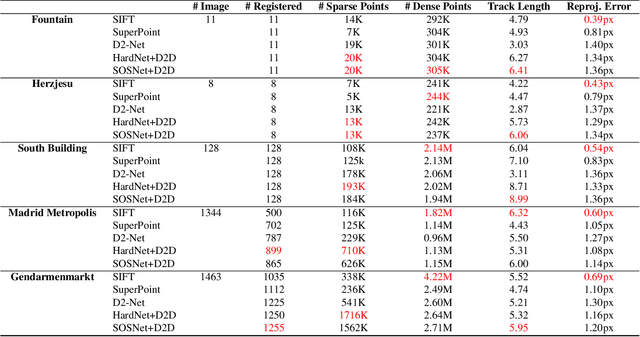
In this paper, we present a novel approach that exploits the information within the descriptor space to propose keypoint locations. Detect then describe, or detect and describe jointly are two typical strategies for extracting local descriptors. In contrast, we propose an approach that inverts this process by first describing and then detecting the keypoint locations. % Describe-to-Detect (D2D) leverages successful descriptor models without the need for any additional training. Our method selects keypoints as salient locations with high information content which is defined by the descriptors rather than some independent operators. We perform experiments on multiple benchmarks including image matching, camera localisation, and 3D reconstruction. The results indicate that our method improves the matching performance of various descriptors and that it generalises across methods and tasks.
SOLAR: Second-Order Loss and Attention for Image Retrieval
Feb 09, 2020
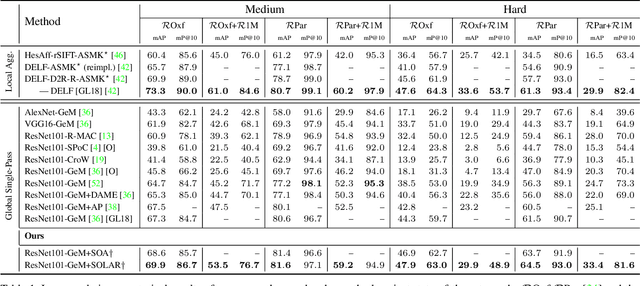
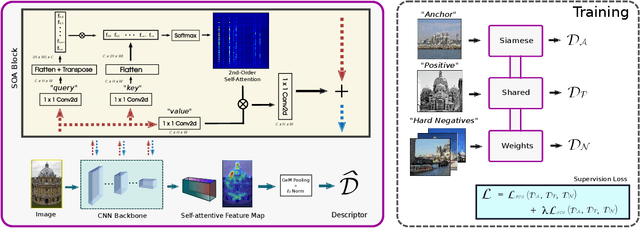
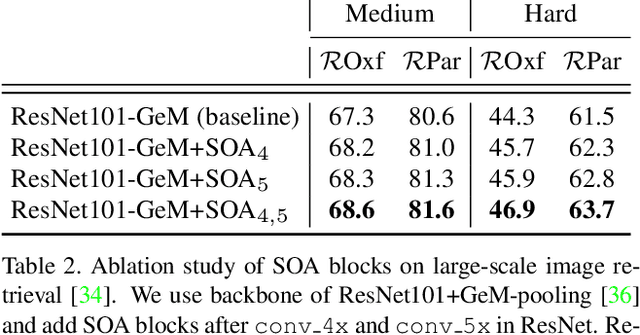
Recent works in deep-learning have shown that utilising second-order information is beneficial in many computer-vision related tasks. Second-order information can be enforced both in the spatial context and the abstract feature dimensions. In this work we explore two second order components. One is focused on second-order spatial information to increase the performance of image descriptors, both local and global. More specifically, it is used to re-weight feature maps, and thus emphasise salient image locations that are subsequently used for description. The second component is concerned with a second-order similarity (SOS) loss, that we extend to global descriptors for image retrieval, and is used to enhance the triplet loss with hard negative mining. We validate our approach on two different tasks and three datasets for image retrieval and patch matching. The results show that our second order components bring significant performance improvements in both tasks and lead to state of the art results across the benchmarks.
UR2KiD: Unifying Retrieval, Keypoint Detection, and Keypoint Description without Local Correspondence Supervision
Jan 20, 2020
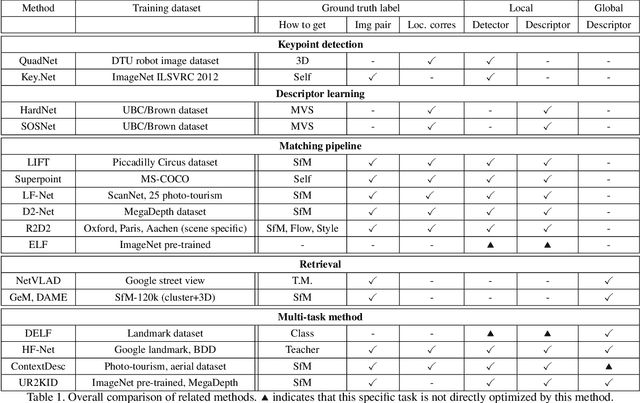
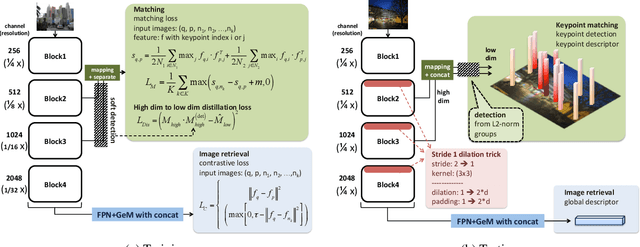
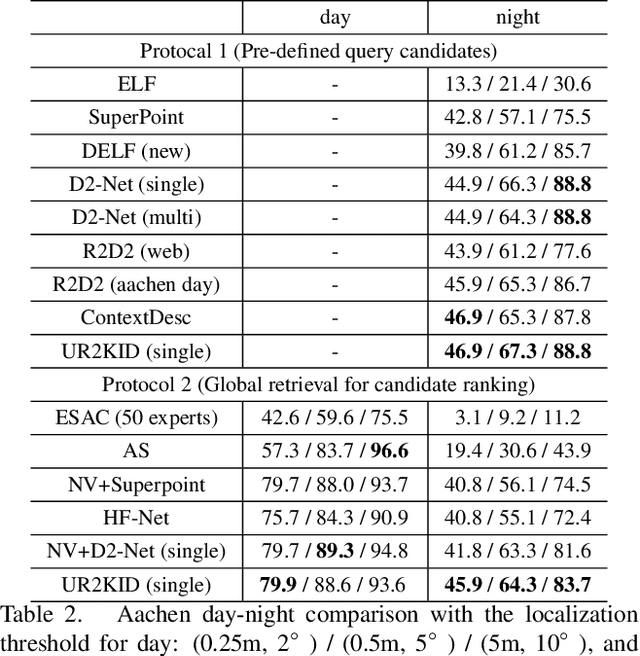
In this paper, we explore how three related tasks, namely keypoint detection, description, and image retrieval can be jointly tackled using a single unified framework, which is trained without the need of training data with point to point correspondences. By leveraging diverse information from sequential layers of a standard ResNet-based architecture, we are able to extract keypoints and descriptors that encode local information using generic techniques such as local activation norms, channel grouping and dropping, and self-distillation. Subsequently, global information for image retrieval is encoded in an end-to-end pipeline, based on pooling of the aforementioned local responses. In contrast to previous methods in local matching, our method does not depend on pointwise/pixelwise correspondences, and requires no such supervision at all i.e. no depth-maps from an SfM model nor manually created synthetic affine transformations. We illustrate that this simple and direct paradigm, is able to achieve very competitive results against the state-of-the-art methods in various challenging benchmark conditions such as viewpoint changes, scale changes, and day-night shifting localization.
SOSNet: Second Order Similarity Regularization for Local Descriptor Learning
Apr 10, 2019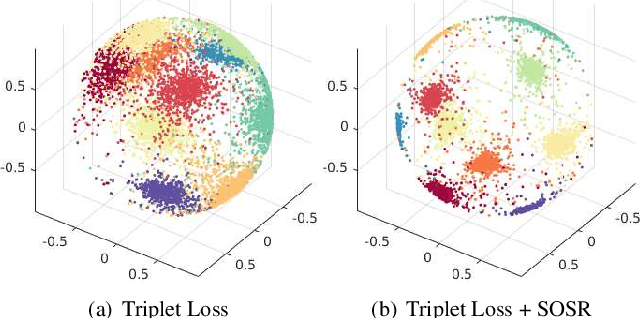
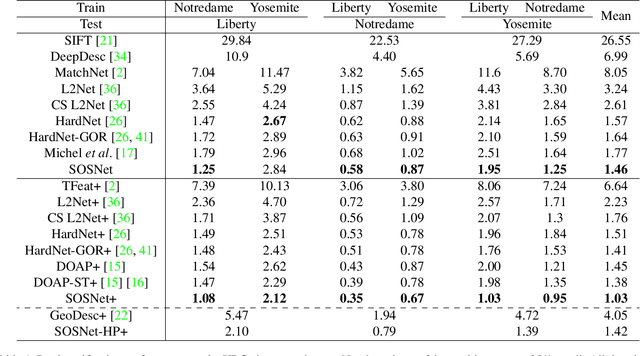
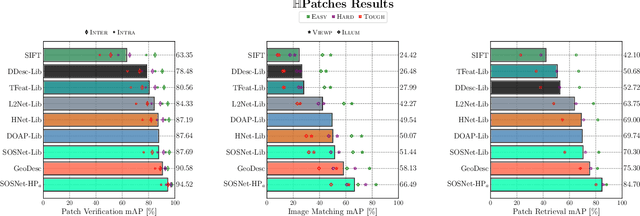
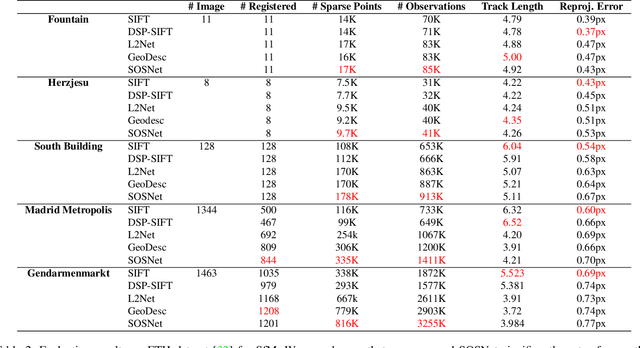
Despite the fact that Second Order Similarity (SOS) has been used with significant success in tasks such as graph matching and clustering, it has not been exploited for learning local descriptors. In this work, we explore the potential of SOS in the field of descriptor learning by building upon the intuition that a positive pair of matching points should exhibit similar distances with respect to other points in the embedding space. Thus, we propose a novel regularization term, named Second Order Similarity Regularization (SOSR), that follows this principle. By incorporating SOSR into training, our learned descriptor achieves state-of-the-art performance on several challenging benchmarks containing distinct tasks ranging from local patch retrieval to structure from motion. Furthermore, by designing a von Mises-Fischer distribution based evaluation method, we link the utilization of the descriptor space to the matching performance, thus demonstrating the effectiveness of our proposed SOSR. Extensive experimental results, empirical evidence, and in-depth analysis are provided, indicating that SOSR can significantly boost the matching performance of the learned descriptor.
Learning Deep Convolutional Embeddings for Face Representation Using Joint Sample- and Set-based Supervision
Jan 12, 2018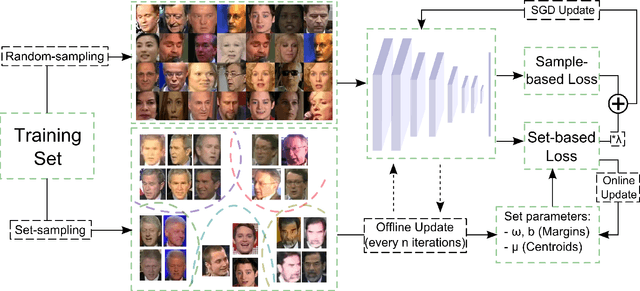
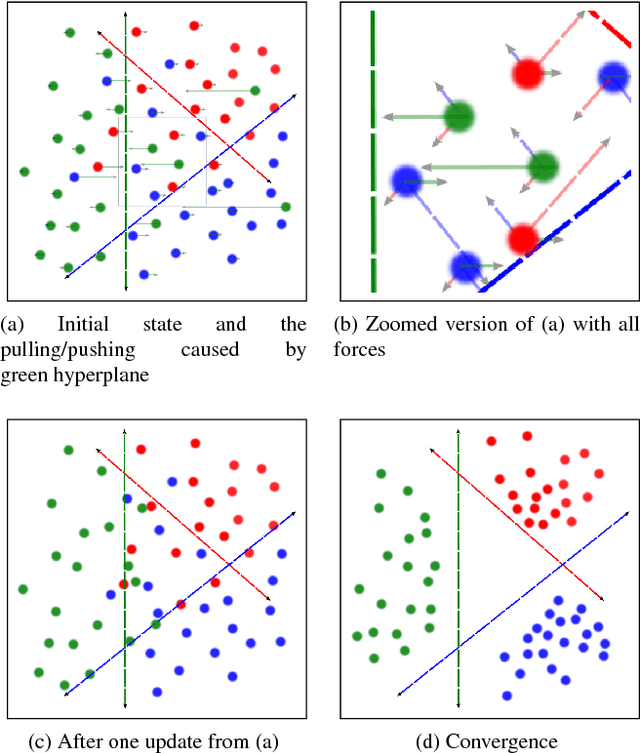

In this work, we investigate several methods and strategies to learn deep embeddings for face recognition, using joint sample- and set-based optimization. We explain our framework that expands traditional learning with set-based supervision together with the strategies used to maintain set characteristics. We, then, briefly review the related set-based loss functions, and subsequently propose a novel Max-Margin Loss which maximizes maximum possible inter-class margin with assistance of Support Vector Machines (SVMs). It implicitly pushes all the samples towards correct side of the margin with a vector perpendicular to the hyperplane and a strength exponentially growing towards to negative side of the hyperplane. We show that the introduced loss outperform the previous sample-based and set-based ones in terms verification of faces on two commonly used benchmarks.
* 8 pages, 5 figures, 2 tables, workshop paper
HPatches: A benchmark and evaluation of handcrafted and learned local descriptors
Apr 19, 2017


In this paper, we propose a novel benchmark for evaluating local image descriptors. We demonstrate that the existing datasets and evaluation protocols do not specify unambiguously all aspects of evaluation, leading to ambiguities and inconsistencies in results reported in the literature. Furthermore, these datasets are nearly saturated due to the recent improvements in local descriptors obtained by learning them from large annotated datasets. Therefore, we introduce a new large dataset suitable for training and testing modern descriptors, together with strictly defined evaluation protocols in several tasks such as matching, retrieval and classification. This allows for more realistic, and thus more reliable comparisons in different application scenarios. We evaluate the performance of several state-of-the-art descriptors and analyse their properties. We show that a simple normalisation of traditional hand-crafted descriptors can boost their performance to the level of deep learning based descriptors within a realistic benchmarks evaluation.
Siamese Regression Networks with Efficient mid-level Feature Extraction for 3D Object Pose Estimation
Jul 08, 2016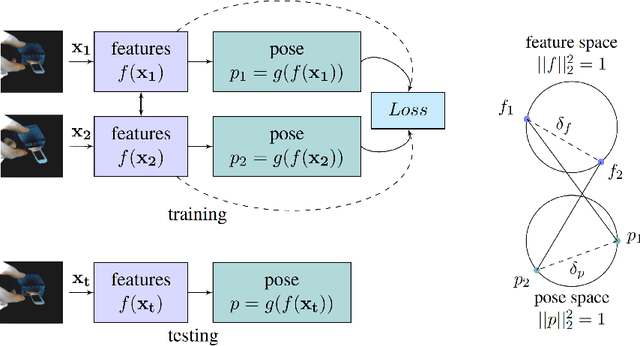

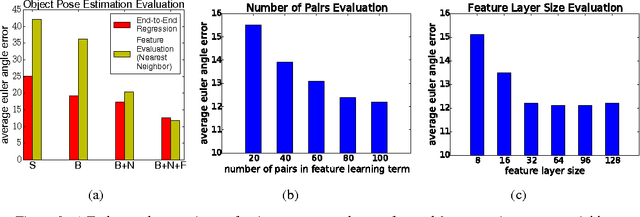
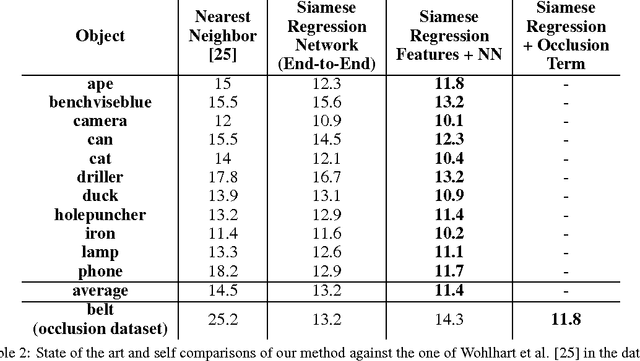
In this paper we tackle the problem of estimating the 3D pose of object instances, using convolutional neural networks. State of the art methods usually solve the challenging problem of regression in angle space indirectly, focusing on learning discriminative features that are later fed into a separate architecture for 3D pose estimation. In contrast, we propose an end-to-end learning framework for directly regressing object poses by exploiting Siamese Networks. For a given image pair, we enforce a similarity measure between the representation of the sample images in the feature and pose space respectively, that is shown to boost regression performance. Furthermore, we argue that our pose-guided feature learning using our Siamese Regression Network generates more discriminative features that outperform the state of the art. Last, our feature learning formulation provides the ability of learning features that can perform under severe occlusions, demonstrating high performance on our novel hand-object dataset.