 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Ego-Centric modeling of Human-Object interactions
Aug 29, 2025



Modeling human-object interactions (HOI) from an egocentric perspective is a largely unexplored yet important problem due to the increasing adoption of wearable devices, such as smart glasses and watches. We investigate how much information about interaction can be recovered from only head and wrists tracking. Our answer is ECHO (Ego-Centric modeling of Human-Object interactions), which, for the first time, proposes a unified framework to recover three modalities: human pose, object motion, and contact from such minimal observation. ECHO employs a Diffusion Transformer architecture and a unique three-variate diffusion process, which jointly models human motion, object trajectory, and contact sequence, allowing for flexible input configurations. Our method operates in a head-centric canonical space, enhancing robustness to global orientation. We propose a conveyor-based inference, which progressively increases the diffusion timestamp with the frame position, allowing us to process sequences of any length. Through extensive evaluation, we demonstrate that ECHO outperforms existing methods that do not offer the same flexibility, setting a state-of-the-art in egocentric HOI reconstruction.
SCENIC: Scene-aware Semantic Navigation with Instruction-guided Control
Dec 20, 2024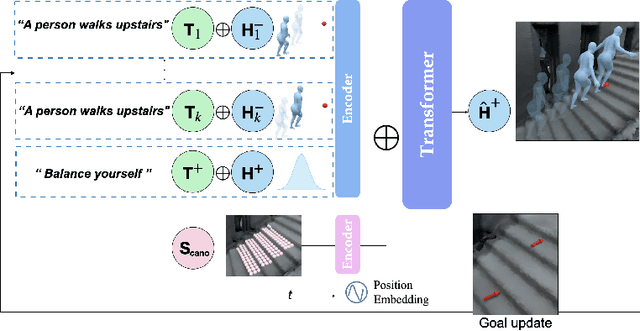
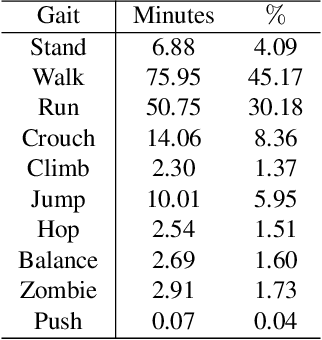
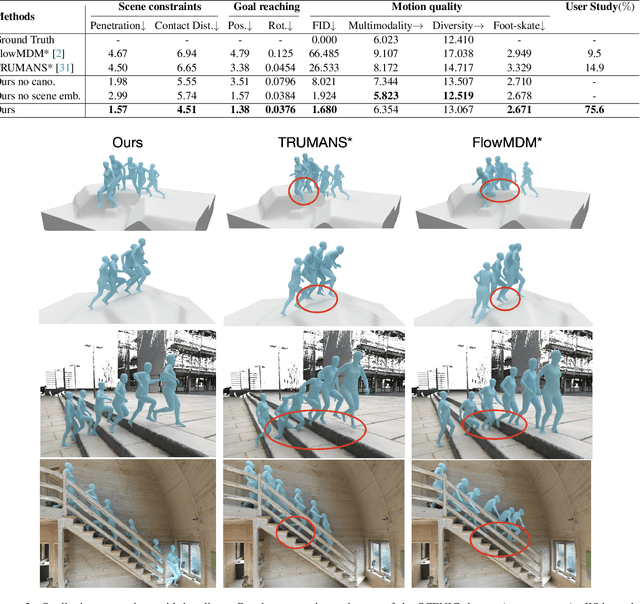

Synthesizing natural human motion that adapts to complex environments while allowing creative control remains a fundamental challenge in motion synthesis. Existing models often fall short, either by assuming flat terrain or lacking the ability to control motion semantics through text. To address these limitations, we introduce SCENIC, a diffusion model designed to generate human motion that adapts to dynamic terrains within virtual scenes while enabling semantic control through natural language. The key technical challenge lies in simultaneously reasoning about complex scene geometry while maintaining text control. This requires understanding both high-level navigation goals and fine-grained environmental constraints. The model must ensure physical plausibility and precise navigation across varied terrain, while also preserving user-specified text control, such as ``carefully stepping over obstacles" or ``walking upstairs like a zombie." Our solution introduces a hierarchical scene reasoning approach. At its core is a novel scene-dependent, goal-centric canonicalization that handles high-level goal constraint, and is complemented by an ego-centric distance field that captures local geometric details. This dual representation enables our model to generate physically plausible motion across diverse 3D scenes. By implementing frame-wise text alignment, our system achieves seamless transitions between different motion styles while maintaining scene constraints. Experiments demonstrate our novel diffusion model generates arbitrarily long human motions that both adapt to complex scenes with varying terrain surfaces and respond to textual prompts. Additionally, we show SCENIC can generalize to four real-scene datasets. Our code, dataset, and models will be released at \url{https://virtualhumans.mpi-inf.mpg.de/scenic/}.
Blendify -- Python rendering framework for Blender
Oct 23, 2024

With the rapid growth of the volume of research fields like computer vision and computer graphics, researchers require effective and user-friendly rendering tools to visualize results. While advanced tools like Blender offer powerful capabilities, they also require a significant effort to master. This technical report introduces Blendify, a lightweight Python-based framework that seamlessly integrates with Blender, providing a high-level API for scene creation and rendering. Blendify reduces the complexity of working with Blender's native API by automating object creation, handling the colors and material linking, and implementing features such as shadow-catcher objects while maintaining support for high-quality ray-tracing rendering output. With a focus on usability Blendify enables efficient and flexible rendering workflow for rendering in common computer vision and computer graphics use cases. The code is available at https://github.com/ptrvilya/blendify
EgoLM: Multi-Modal Language Model of Egocentric Motions
Sep 26, 2024



As the prevalence of wearable devices, learning egocentric motions becomes essential to develop contextual AI. In this work, we present EgoLM, a versatile framework that tracks and understands egocentric motions from multi-modal inputs, e.g., egocentric videos and motion sensors. EgoLM exploits rich contexts for the disambiguation of egomotion tracking and understanding, which are ill-posed under single modality conditions. To facilitate the versatile and multi-modal framework, our key insight is to model the joint distribution of egocentric motions and natural languages using large language models (LLM). Multi-modal sensor inputs are encoded and projected to the joint latent space of language models, and used to prompt motion generation or text generation for egomotion tracking or understanding, respectively. Extensive experiments on large-scale multi-modal human motion dataset validate the effectiveness of EgoLM as a generalist model for universal egocentric learning.
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
Jun 14, 2024We introduce Nymeria - a large-scale, diverse, richly annotated human motion dataset collected in the wild with multiple multimodal egocentric devices. The dataset comes with a) full-body 3D motion ground truth; b) egocentric multimodal recordings from Project Aria devices with RGB, grayscale, eye-tracking cameras, IMUs, magnetometer, barometer, and microphones; and c) an additional "observer" device providing a third-person viewpoint. We compute world-aligned 6DoF transformations for all sensors, across devices and capture sessions. The dataset also provides 3D scene point clouds and calibrated gaze estimation. We derive a protocol to annotate hierarchical language descriptions of in-context human motion, from fine-grain pose narrations, to atomic actions and activity summarization. To the best of our knowledge, the Nymeria dataset is the world largest in-the-wild collection of human motion with natural and diverse activities; first of its kind to provide synchronized and localized multi-device multimodal egocentric data; and the world largest dataset with motion-language descriptions. It contains 1200 recordings of 300 hours of daily activities from 264 participants across 50 locations, travelling a total of 399Km. The motion-language descriptions provide 310.5K sentences in 8.64M words from a vocabulary size of 6545. To demonstrate the potential of the dataset we define key research tasks for egocentric body tracking, motion synthesis, and action recognition and evaluate several state-of-the-art baseline algorithms. Data and code will be open-sourced.
FORCE: Dataset and Method for Intuitive Physics Guided Human-object Interaction
Mar 17, 2024



Interactions between human and objects are influenced not only by the object's pose and shape, but also by physical attributes such as object mass and surface friction. They introduce important motion nuances that are essential for diversity and realism. Despite advancements in recent kinematics-based methods, this aspect has been overlooked. Generating nuanced human motion presents two challenges. First, it is non-trivial to learn from multi-modal human and object information derived from both the physical and non-physical attributes. Second, there exists no dataset capturing nuanced human interactions with objects of varying physical properties, hampering model development. This work addresses the gap by introducing the FORCE model, a kinematic approach for synthesizing diverse, nuanced human-object interactions by modeling physical attributes. Our key insight is that human motion is dictated by the interrelation between the force exerted by the human and the perceived resistance. Guided by a novel intuitive physics encoding, the model captures the interplay between human force and resistance. Experiments also demonstrate incorporating human force facilitates learning multi-class motion. Accompanying our model, we contribute the FORCE dataset. It features diverse, different-styled motion through interactions with varying resistances.
Visually plausible human-object interaction capture from wearable sensors
May 05, 2022

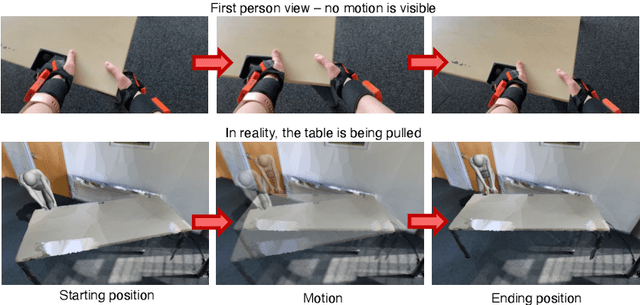
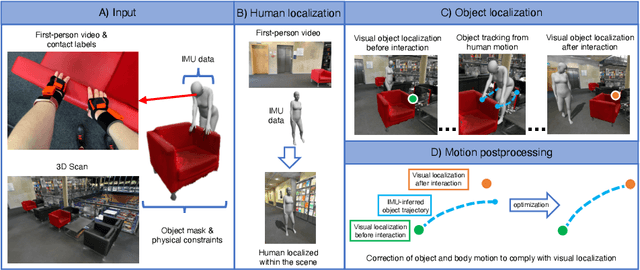
In everyday lives, humans naturally modify the surrounding environment through interactions, e.g., moving a chair to sit on it. To reproduce such interactions in virtual spaces (e.g., metaverse), we need to be able to capture and model them, including changes in the scene geometry, ideally from ego-centric input alone (head camera and body-worn inertial sensors). This is an extremely hard problem, especially since the object/scene might not be visible from the head camera (e.g., a human not looking at a chair while sitting down, or not looking at the door handle while opening a door). In this paper, we present HOPS, the first method to capture interactions such as dragging objects and opening doors from ego-centric data alone. Central to our method is reasoning about human-object interactions, allowing to track objects even when they are not visible from the head camera. HOPS localizes and registers both the human and the dynamic object in a pre-scanned static scene. HOPS is an important first step towards advanced AR/VR applications based on immersive virtual universes, and can provide human-centric training data to teach machines to interact with their surroundings. The supplementary video, data, and code will be available on our project page at http://virtualhumans.mpi-inf.mpg.de/hops/
COUCH: Towards Controllable Human-Chair Interactions
May 01, 2022


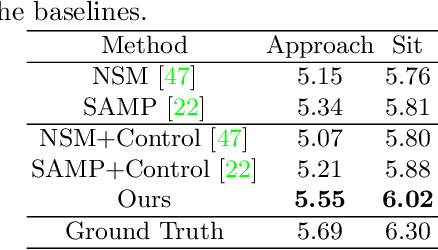
Humans interact with an object in many different ways by making contact at different locations, creating a highly complex motion space that can be difficult to learn, particularly when synthesizing such human interactions in a controllable manner. Existing works on synthesizing human scene interaction focus on the high-level control of action but do not consider the fine-grained control of motion. In this work, we study the problem of synthesizing scene interactions conditioned on different contact positions on the object. As a testbed to investigate this new problem, we focus on human-chair interaction as one of the most common actions which exhibit large variability in terms of contacts. We propose a novel synthesis framework COUCH that plans ahead the motion by predicting contact-aware control signals of the hands, which are then used to synthesize contact-conditioned interactions. Furthermore, we contribute a large human-chair interaction dataset with clean annotations, the COUCH Dataset. Our method shows significant quantitative and qualitative improvements over existing methods for human-object interactions. More importantly, our method enables control of the motion through user-specified or automatically predicted contacts.
Control-NeRF: Editable Feature Volumes for Scene Rendering and Manipulation
Apr 22, 2022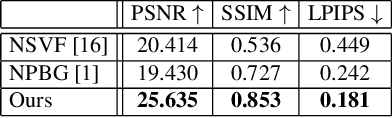
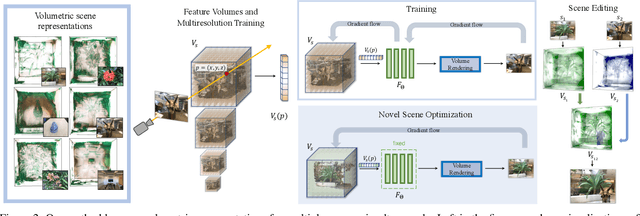
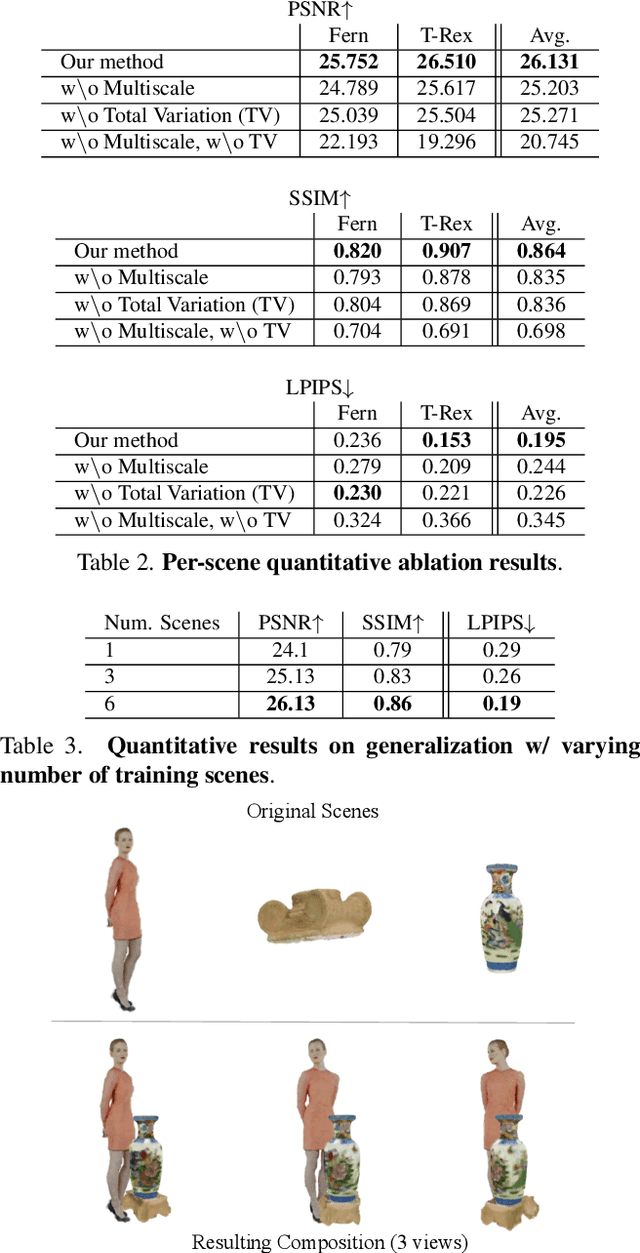

We present a novel method for performing flexible, 3D-aware image content manipulation while enabling high-quality novel view synthesis. While NeRF-based approaches are effective for novel view synthesis, such models memorize the radiance for every point in a scene within a neural network. Since these models are scene-specific and lack a 3D scene representation, classical editing such as shape manipulation, or combining scenes is not possible. Hence, editing and combining NeRF-based scenes has not been demonstrated. With the aim of obtaining interpretable and controllable scene representations, our model couples learnt scene-specific feature volumes with a scene agnostic neural rendering network. With this hybrid representation, we decouple neural rendering from scene-specific geometry and appearance. We can generalize to novel scenes by optimizing only the scene-specific 3D feature representation, while keeping the parameters of the rendering network fixed. The rendering function learnt during the initial training stage can thus be easily applied to new scenes, making our approach more flexible. More importantly, since the feature volumes are independent of the rendering model, we can manipulate and combine scenes by editing their corresponding feature volumes. The edited volume can then be plugged into the rendering model to synthesize high-quality novel views. We demonstrate various scene manipulations, including mixing scenes, deforming objects and inserting objects into scenes, while still producing photo-realistic results.
Human POSEitioning System (HPS): 3D Human Pose Estimation and Self-localization in Large Scenes from Body-Mounted Sensors
Mar 31, 2021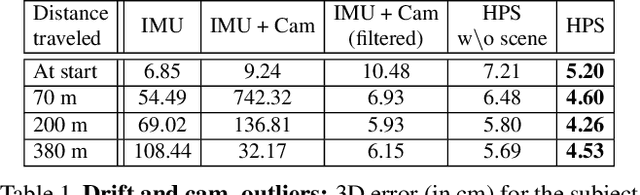
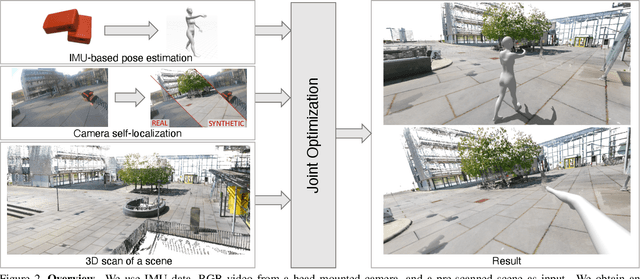
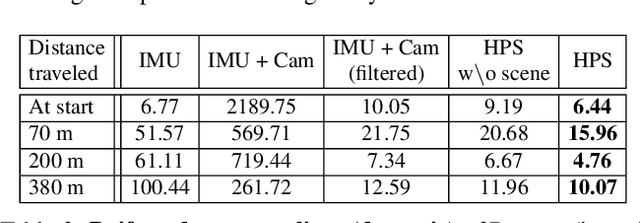
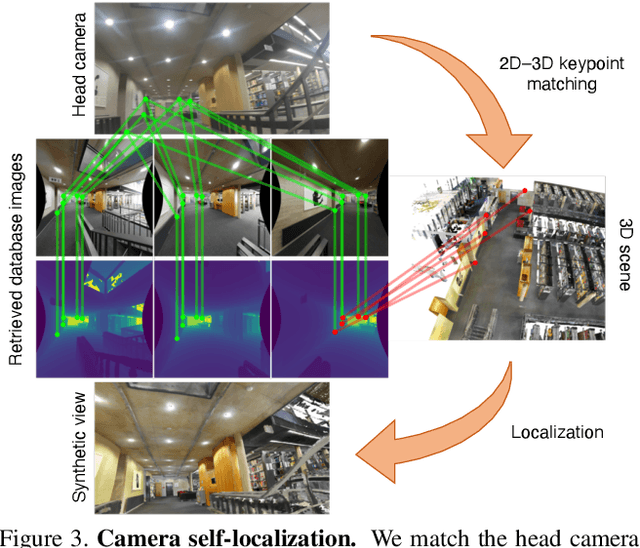
We introduce (HPS) Human POSEitioning System, a method to recover the full 3D pose of a human registered with a 3D scan of the surrounding environment using wearable sensors. Using IMUs attached at the body limbs and a head mounted camera looking outwards, HPS fuses camera based self-localization with IMU-based human body tracking. The former provides drift-free but noisy position and orientation estimates while the latter is accurate in the short-term but subject to drift over longer periods of time. We show that our optimization-based integration exploits the benefits of the two, resulting in pose accuracy free of drift. Furthermore, we integrate 3D scene constraints into our optimization, such as foot contact with the ground, resulting in physically plausible motion. HPS complements more common third-person-based 3D pose estimation methods. It allows capturing larger recording volumes and longer periods of motion, and could be used for VR/AR applications where humans interact with the scene without requiring direct line of sight with an external camera, or to train agents that navigate and interact with the environment based on first-person visual input, like real humans. With HPS, we recorded a dataset of humans interacting with large 3D scenes (300-1000 sq.m) consisting of 7 subjects and more than 3 hours of diverse motion. The dataset, code and video will be available on the project page: http://virtualhumans.mpi-inf.mpg.de/hps/ .