 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-FSM: Scaling Large Language Models for Finite-State Reasoning in RTL Code Generation
Feb 03, 2026Finite-state reasoning, the ability to understand and implement state-dependent behavior, is central to hardware design. In this paper, we present LLM-FSM, a benchmark that evaluates how well large language models (LLMs) can recover finite-state machine (FSM) behavior from natural-language specifications and translate it into correct register transfer-level (RTL) implementations. Unlike prior specification-to-RTL benchmarks that rely on manually constructed examples, LLM-FSM is built through a fully automated pipeline. LLM-FSM first constructs FSM with configurable state counts and constrained transition structures. It then prompts LLMs to express each FSM in a structured YAML format with an application context, and to further convert that YAML into a natural-language (NL) specification. From the same YAML, our pipeline synthesizes the reference RTL and testbench in a correct-by-construction manner. All 1,000 problems are verified using LLM-based and SAT-solver-based checks, with human review on a subset. Our experiments show that even the strongest LLMs exhibit sharply declining accuracy as FSM complexity increases. We further demonstrate that training-time scaling via supervised fine-tuning (SFT) generalizes effectively to out-of-distribution (OOD) tasks, while increasing test-time compute improves reasoning reliability. Finally, LLM-FSM remains extensible by allowing its FSM complexity to scale with future model capabilities.
VeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation
Apr 22, 2025



Recent advances in Large Language Models (LLMs) have sparked growing interest in applying them to Electronic Design Automation (EDA) tasks, particularly Register Transfer Level (RTL) code generation. While several RTL datasets have been introduced, most focus on syntactic validity rather than functional validation with tests, leading to training examples that compile but may not implement the intended behavior. We present VERICODER, a model for RTL code generation fine-tuned on a dataset validated for functional correctness. This fine-tuning dataset is constructed using a novel methodology that combines unit test generation with feedback-directed refinement. Given a natural language specification and an initial RTL design, we prompt a teacher model (GPT-4o-mini) to generate unit tests and iteratively revise the RTL design based on its simulation results using the generated tests. If necessary, the teacher model also updates the tests to ensure they comply with the natural language specification. As a result of this process, every example in our dataset is functionally validated, consisting of a natural language description, an RTL implementation, and passing tests. Fine-tuned on this dataset of over 125,000 examples, VERICODER achieves state-of-the-art metrics in functional correctness on VerilogEval and RTLLM, with relative gains of up to 71.7% and 27.4% respectively. An ablation study further shows that models trained on our functionally validated dataset outperform those trained on functionally non-validated datasets, underscoring the importance of high-quality datasets in RTL code generation.
nl2spec: Interactively Translating Unstructured Natural Language to Temporal Logics with Large Language Models
Mar 08, 2023



A rigorous formalization of desired system requirements is indispensable when performing any verification task. This often limits the application of verification techniques, as writing formal specifications is an error-prone and time-consuming manual task. To facilitate this, we present nl2spec, a framework for applying Large Language Models (LLMs) to derive formal specifications (in temporal logics) from unstructured natural language. In particular, we introduce a new methodology to detect and resolve the inherent ambiguity of system requirements in natural language: we utilize LLMs to map subformulas of the formalization back to the corresponding natural language fragments of the input. Users iteratively add, delete, and edit these sub-translations to amend erroneous formalizations, which is easier than manually redrafting the entire formalization. The framework is agnostic to specific application domains and can be extended to similar specification languages and new neural models. We perform a user study to obtain a challenging dataset, which we use to run experiments on the quality of translations. We provide an open-source implementation, including a web-based frontend.
Dynamic Network Adaptation at Inference
Apr 18, 2022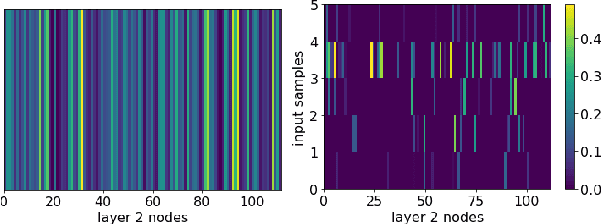
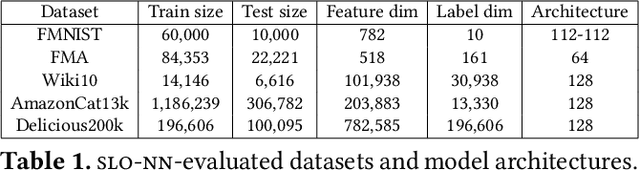
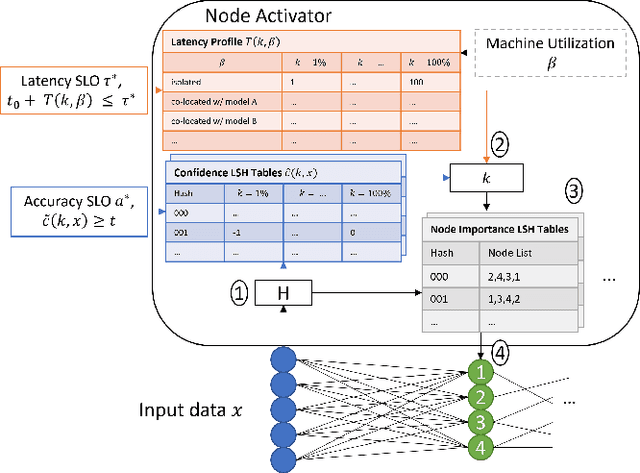

Machine learning (ML) inference is a real-time workload that must comply with strict Service Level Objectives (SLOs), including latency and accuracy targets. Unfortunately, ensuring that SLOs are not violated in inference-serving systems is challenging due to inherent model accuracy-latency tradeoffs, SLO diversity across and within application domains, evolution of SLOs over time, unpredictable query patterns, and co-location interference. In this paper, we observe that neural networks exhibit high degrees of per-input activation sparsity during inference. . Thus, we propose SLO-Aware Neural Networks which dynamically drop out nodes per-inference query, thereby tuning the amount of computation performed, according to specified SLO optimization targets and machine utilization. SLO-Aware Neural Networks achieve average speedups of $1.3-56.7\times$ with little to no accuracy loss (less than 0.3%). When accuracy constrained, SLO-Aware Neural Networks are able to serve a range of accuracy targets at low latency with the same trained model. When latency constrained, SLO-Aware Neural Networks can proactively alleviate latency degradation from co-location interference while maintaining high accuracy to meet latency constraints.
RecShard: Statistical Feature-Based Memory Optimization for Industry-Scale Neural Recommendation
Jan 25, 2022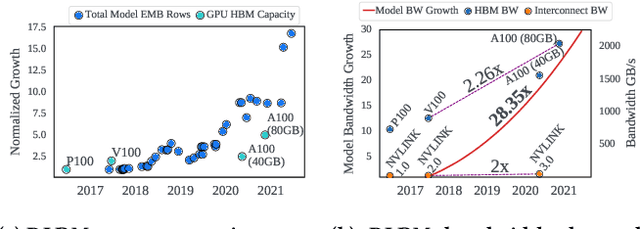
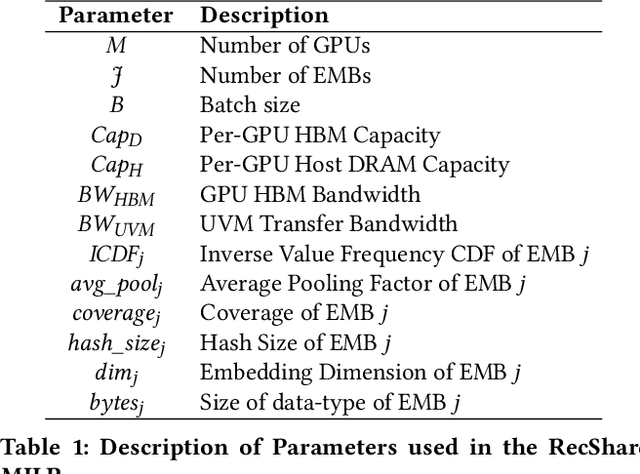
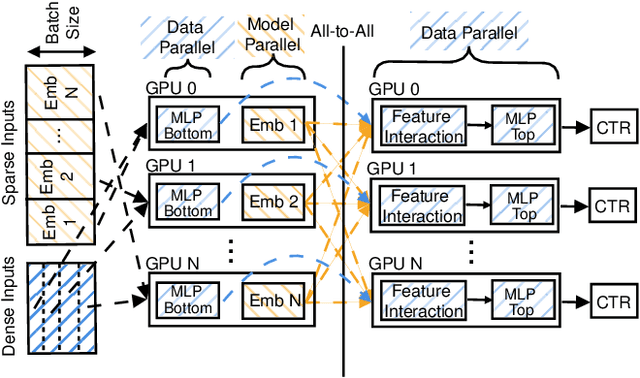
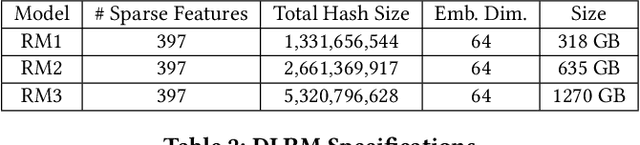
We propose RecShard, a fine-grained embedding table (EMB) partitioning and placement technique for deep learning recommendation models (DLRMs). RecShard is designed based on two key observations. First, not all EMBs are equal, nor all rows within an EMB are equal in terms of access patterns. EMBs exhibit distinct memory characteristics, providing performance optimization opportunities for intelligent EMB partitioning and placement across a tiered memory hierarchy. Second, in modern DLRMs, EMBs function as hash tables. As a result, EMBs display interesting phenomena, such as the birthday paradox, leaving EMBs severely under-utilized. RecShard determines an optimal EMB sharding strategy for a set of EMBs based on training data distributions and model characteristics, along with the bandwidth characteristics of the underlying tiered memory hierarchy. In doing so, RecShard achieves over 6 times higher EMB training throughput on average for capacity constrained DLRMs. The throughput increase comes from improved EMB load balance by over 12 times and from the reduced access to the slower memory by over 87 times.
Analysis and Mitigations of Reverse Engineering Attacks on Local Feature Descriptors
May 09, 2021
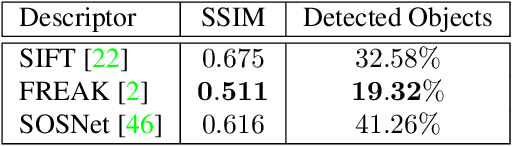
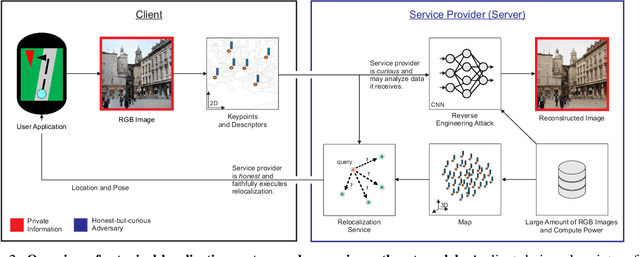
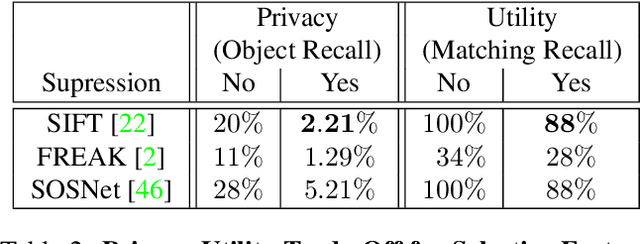
As autonomous driving and augmented reality evolve, a practical concern is data privacy. In particular, these applications rely on localization based on user images. The widely adopted technology uses local feature descriptors, which are derived from the images and it was long thought that they could not be reverted back. However, recent work has demonstrated that under certain conditions reverse engineering attacks are possible and allow an adversary to reconstruct RGB images. This poses a potential risk to user privacy. We take this a step further and model potential adversaries using a privacy threat model. Subsequently, we show under controlled conditions a reverse engineering attack on sparse feature maps and analyze the vulnerability of popular descriptors including FREAK, SIFT and SOSNet. Finally, we evaluate potential mitigation techniques that select a subset of descriptors to carefully balance privacy reconstruction risk while preserving image matching accuracy; our results show that similar accuracy can be obtained when revealing less information.
RecSSD: Near Data Processing for Solid State Drive Based Recommendation Inference
Jan 29, 2021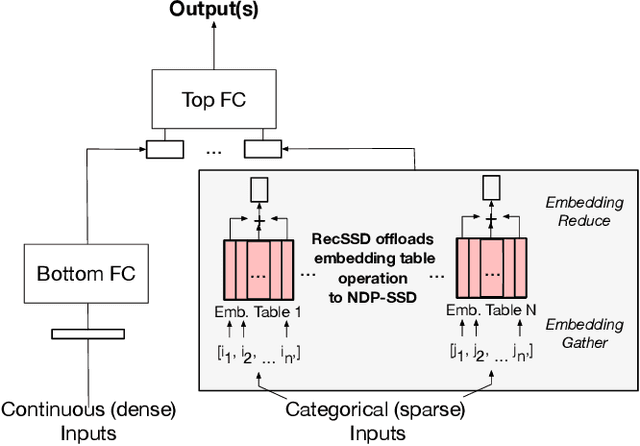
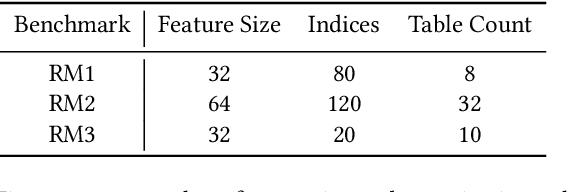
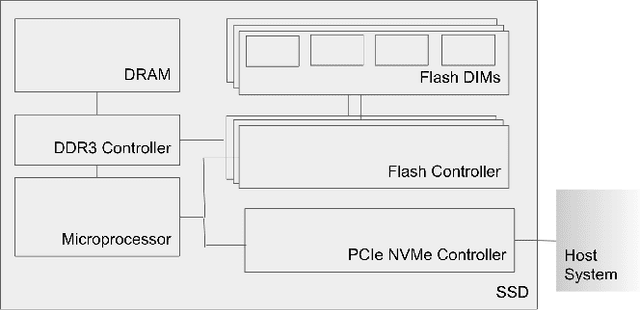
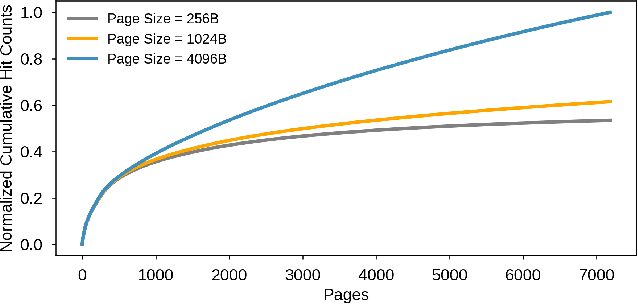
Neural personalized recommendation models are used across a wide variety of datacenter applications including search, social media, and entertainment. State-of-the-art models comprise large embedding tables that have billions of parameters requiring large memory capacities. Unfortunately, large and fast DRAM-based memories levy high infrastructure costs. Conventional SSD-based storage solutions offer an order of magnitude larger capacity, but have worse read latency and bandwidth, degrading inference performance. RecSSD is a near data processing based SSD memory system customized for neural recommendation inference that reduces end-to-end model inference latency by 2X compared to using COTS SSDs across eight industry-representative models.
CPR: Understanding and Improving Failure Tolerant Training for Deep Learning Recommendation with Partial Recovery
Nov 05, 2020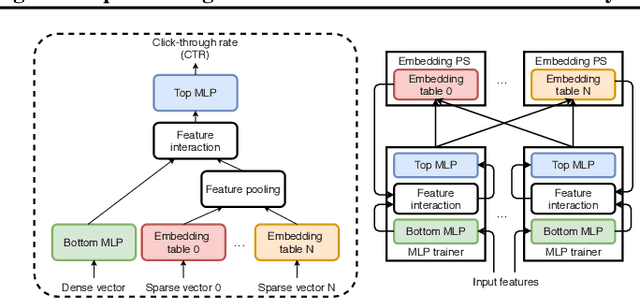
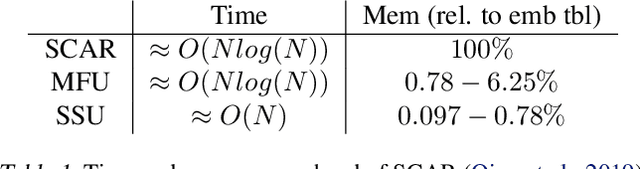
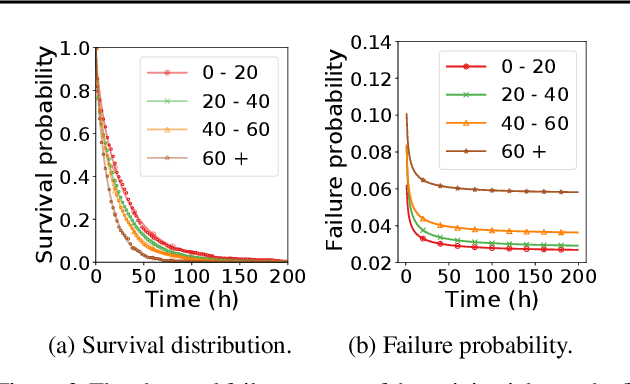
The paper proposes and optimizes a partial recovery training system, CPR, for recommendation models. CPR relaxes the consistency requirement by enabling non-failed nodes to proceed without loading checkpoints when a node fails during training, improving failure-related overheads. The paper is the first to the extent of our knowledge to perform a data-driven, in-depth analysis of applying partial recovery to recommendation models and identified a trade-off between accuracy and performance. Motivated by the analysis, we present CPR, a partial recovery training system that can reduce the training time and maintain the desired level of model accuracy by (1) estimating the benefit of partial recovery, (2) selecting an appropriate checkpoint saving interval, and (3) prioritizing to save updates of more frequently accessed parameters. Two variants of CPR, CPR-MFU and CPR-SSU, reduce the checkpoint-related overhead from 8.2-8.5% to 0.53-0.68% compared to full recovery, on a configuration emulating the failure pattern and overhead of a production-scale cluster. While reducing overhead significantly, CPR achieves model quality on par with the more expensive full recovery scheme, training the state-of-the-art recommendation model using Criteo's Ads CTR dataset. Our preliminary results also suggest that CPR can speed up training on a real production-scale cluster, without notably degrading the accuracy.