 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRCNet: Seminal Representation Collaborative Network for Marine Oil Spill Segmentation
Apr 17, 2023



Effective oil spill segmentation in Synthetic Aperture Radar (SAR) images is critical for marine oil pollution cleanup, and proper image representation is helpful for accurate image segmentation. In this paper, we propose an effective oil spill image segmentation network named SRCNet by leveraging SAR image representation and the training for oil spill segmentation simultaneously. Specifically, our proposed segmentation network is constructed with a pair of deep neural nets with the collaboration of the seminal representation that describes SAR images, where one deep neural net is the generative net which strives to produce oil spill segmentation maps, and the other is the discriminative net which trys its best to distinguish between the produced and the true segmentations, and they thus built a two-player game. Particularly, the seminal representation exploited in our proposed SRCNet originates from SAR imagery, modelling with the internal characteristics of SAR images. Thus, in the training process, the collaborated seminal representation empowers the mapped generative net to produce accurate oil spill segmentation maps efficiently with small amount of training data, promoting the discriminative net reaching its optimal solution at a fast speed. Therefore, our proposed SRCNet operates effective oil spill segmentation in an economical and efficient manner. Additionally, to increase the segmentation capability of the proposed segmentation network in terms of accurately delineating oil spill details in SAR images, a regularisation term that penalises the segmentation loss is devised. This encourages our proposed SRCNet for accurately segmenting oil spill areas from SAR images. Empirical experimental evaluations from different metrics validate the effectiveness of our proposed SRCNet for oil spill image segmentation.
VTAE: Variational Transformer Autoencoder with Manifolds Learning
Apr 03, 2023Deep generative models have demonstrated successful applications in learning non-linear data distributions through a number of latent variables and these models use a nonlinear function (generator) to map latent samples into the data space. On the other hand, the nonlinearity of the generator implies that the latent space shows an unsatisfactory projection of the data space, which results in poor representation learning. This weak projection, however, can be addressed by a Riemannian metric, and we show that geodesics computation and accurate interpolations between data samples on the Riemannian manifold can substantially improve the performance of deep generative models. In this paper, a Variational spatial-Transformer AutoEncoder (VTAE) is proposed to minimize geodesics on a Riemannian manifold and improve representation learning. In particular, we carefully design the variational autoencoder with an encoded spatial-Transformer to explicitly expand the latent variable model to data on a Riemannian manifold, and obtain global context modelling. Moreover, to have smooth and plausible interpolations while traversing between two different objects' latent representations, we propose a geodesic interpolation network different from the existing models that use linear interpolation with inferior performance. Experiments on benchmarks show that our proposed model can improve predictive accuracy and versatility over a range of computer vision tasks, including image interpolations, and reconstructions.
LSDM: Long-Short Diffeomorphic Motion for Weakly-Supervised Ultrasound Landmark Tracking
Jan 11, 2023Accurate tracking of an anatomical landmark over time has been of high interests for disease assessment such as minimally invasive surgery and tumor radiation therapy. Ultrasound imaging is a promising modality benefiting from low-cost and real-time acquisition. However, generating a precise landmark tracklet is very challenging, as attempts can be easily distorted by different interference such as landmark deformation, visual ambiguity and partial observation. In this paper, we propose a long-short diffeomorphic motion network, which is a multi-task framework with a learnable deformation prior to search for the plausible deformation of landmark. Specifically, we design a novel diffeomorphism representation in both long and short temporal domains for delineating motion margins and reducing long-term cumulative tracking errors. To further mitigate local anatomical ambiguity, we propose an expectation maximisation motion alignment module to iteratively optimize both long and short deformation, aligning to the same directional and spatial representation. The proposed multi-task system can be trained in a weakly-supervised manner, which only requires few landmark annotations for tracking and zero annotation for long-short deformation learning. We conduct extensive experiments on two ultrasound landmark tracking datasets. Experimental results show that our proposed method can achieve better or competitive landmark tracking performance compared with other state-of-the-art tracking methods, with a strong generalization capability across different scanner types and different ultrasound modalities.
DGNet: Distribution Guided Efficient Learning for Oil Spill Image Segmentation
Dec 19, 2022



Successful implementation of oil spill segmentation in Synthetic Aperture Radar (SAR) images is vital for marine environmental protection. In this paper, we develop an effective segmentation framework named DGNet, which performs oil spill segmentation by incorporating the intrinsic distribution of backscatter values in SAR images. Specifically, our proposed segmentation network is constructed with two deep neural modules running in an interactive manner, where one is the inference module to achieve latent feature variable inference from SAR images, and the other is the generative module to produce oil spill segmentation maps by drawing the latent feature variables as inputs. Thus, to yield accurate segmentation, we take into account the intrinsic distribution of backscatter values in SAR images and embed it in our segmentation model. The intrinsic distribution originates from SAR imagery, describing the physical characteristics of oil spills. In the training process, the formulated intrinsic distribution guides efficient learning of optimal latent feature variable inference for oil spill segmentation. The efficient learning enables the training of our proposed DGNet with a small amount of image data. This is economically beneficial to oil spill segmentation where the availability of oil spill SAR image data is limited in practice. Additionally, benefiting from optimal latent feature variable inference, our proposed DGNet performs accurate oil spill segmentation. We evaluate the segmentation performance of our proposed DGNet with different metrics, and experimental evaluations demonstrate its effective segmentations.
Deep Learning Methods for Calibrated Photometric Stereo and Beyond: A Survey
Dec 16, 2022



Photometric stereo recovers the surface normals of an object from multiple images with varying shading cues, i.e., modeling the relationship between surface orientation and intensity at each pixel. Photometric stereo prevails in superior per-pixel resolution and fine reconstruction details. However, it is a complicated problem because of the non-linear relationship caused by non-Lambertian surface reflectance. Recently, various deep learning methods have shown a powerful ability in the context of photometric stereo against non-Lambertian surfaces. This paper provides a comprehensive review of existing deep learning-based calibrated photometric stereo methods. We first analyze these methods from different perspectives, including input processing, supervision, and network architecture. We summarize the performance of deep learning photometric stereo models on the most widely-used benchmark data set. This demonstrates the advanced performance of deep learning-based photometric stereo methods. Finally, we give suggestions and propose future research trends based on the limitations of existing models.
Dynamic Event-Triggered Discrete-Time Linear Time-Varying System with Privacy-Preservation
Oct 28, 2022This paper focuses on discrete-time wireless sensor networks with privacy-preservation. In practical applications, information exchange between sensors is subject to attacks. For the information leakage caused by the attack during the information transmission process, privacy-preservation is introduced for system states. To make communication resources more effectively utilized, a dynamic event-triggered set-membership estimator is designed. Moreover, the privacy of the system is analyzed to ensure the security of the real data. As a result, the set-membership estimator with differential privacy is analyzed using recursive convex optimization. Then the steady-state performance of the system is studied. Finally, one example is presented to demonstrate the feasibility of the proposed distributed filter containing privacy-preserving analysis.
Polycentric Clustering and Structural Regularization for Source-free Unsupervised Domain Adaptation
Oct 14, 2022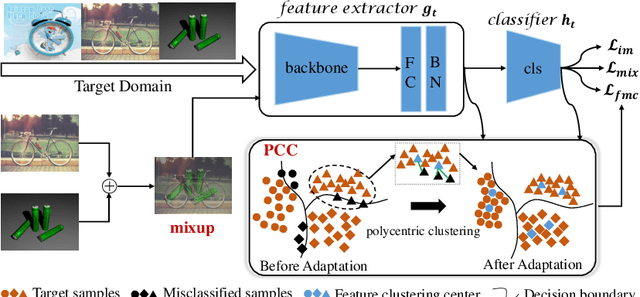
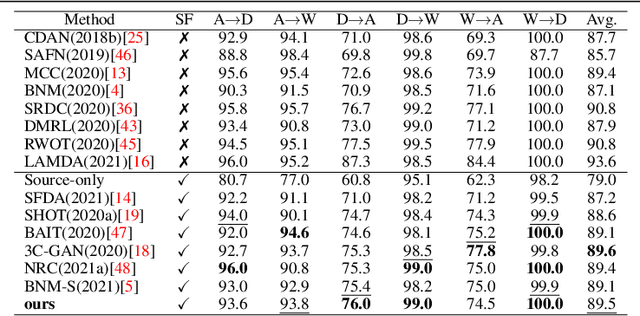
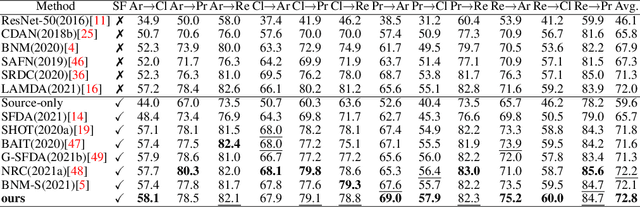
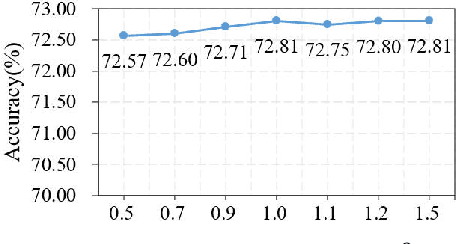
Source-Free Domain Adaptation (SFDA) aims to solve the domain adaptation problem by transferring the knowledge learned from a pre-trained source model to an unseen target domain. Most existing methods assign pseudo-labels to the target data by generating feature prototypes. However, due to the discrepancy in the data distribution between the source domain and the target domain and category imbalance in the target domain, there are severe class biases in the generated feature prototypes and noisy pseudo-labels. Besides, the data structure of the target domain is often ignored, which is crucial for clustering. In this paper, a novel framework named PCSR is proposed to tackle SFDA via a novel intra-class Polycentric Clustering and Structural Regularization strategy. Firstly, an inter-class balanced sampling strategy is proposed to generate representative feature prototypes for each class. Furthermore, k-means clustering is introduced to generate multiple clustering centers for each class in the target domain to obtain robust pseudo-labels. Finally, to enhance the model's generalization, structural regularization is introduced for the target domain. Extensive experiments on three UDA benchmark datasets show that our method performs better or similarly against the other state of the art methods, demonstrating our approach's superiority for visual domain adaptation problems.
Representing Camera Response Function by a Single Latent Variable and Fully Connected Neural Network
Sep 08, 2022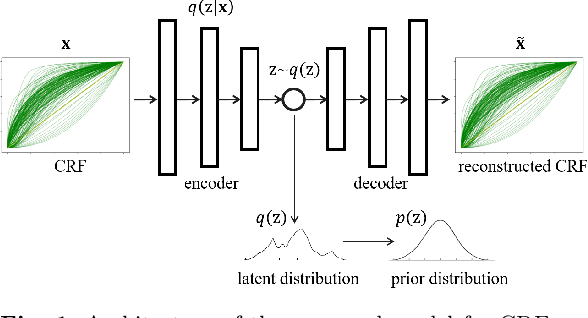
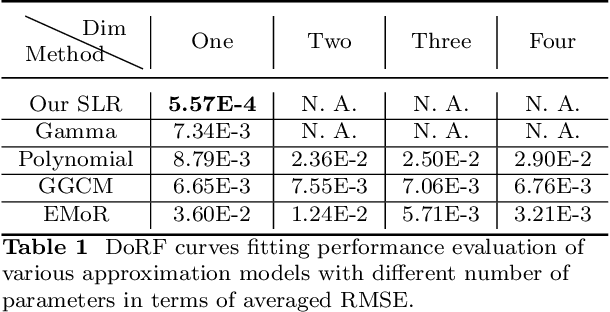
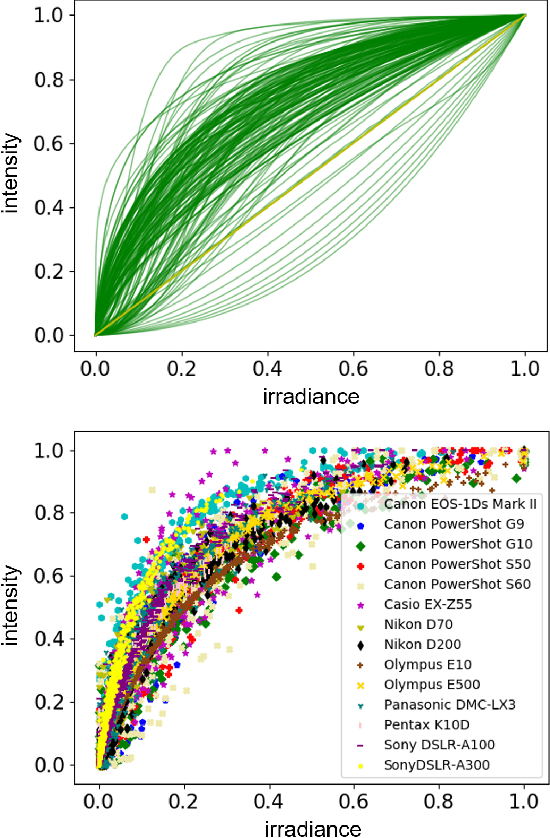
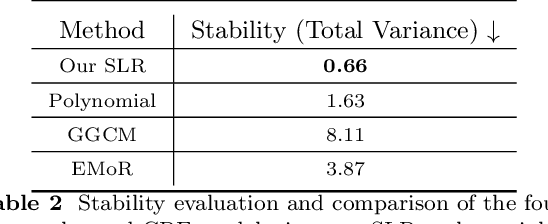
Modelling the mapping from scene irradiance to image intensity is essential for many computer vision tasks. Such mapping is known as the camera response. Most digital cameras use a nonlinear function to map irradiance, as measured by the sensor to an image intensity used to record the photograph. Modelling of the response is necessary for the nonlinear calibration. In this paper, a new high-performance camera response model that uses a single latent variable and fully connected neural network is proposed. The model is produced using unsupervised learning with an autoencoder on real-world (example) camera responses. Neural architecture searching is then used to find the optimal neural network architecture. A latent distribution learning approach was introduced to constrain the latent distribution. The proposed model achieved state-of-the-art CRF representation accuracy in a number of benchmark tests, but is almost twice as fast as the best current models when performing the maximum likelihood estimation during camera response calibration due to the simple yet efficient model representation.
Binary Representation via Jointly Personalized Sparse Hashing
Aug 31, 2022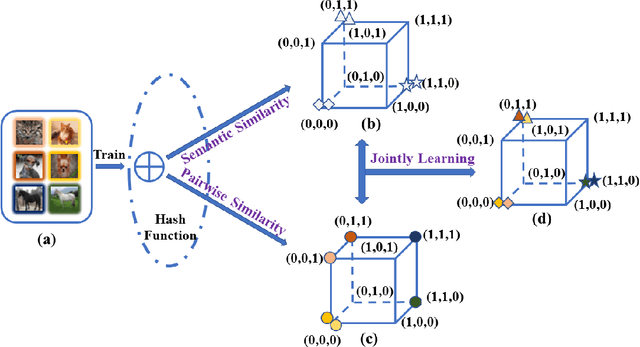
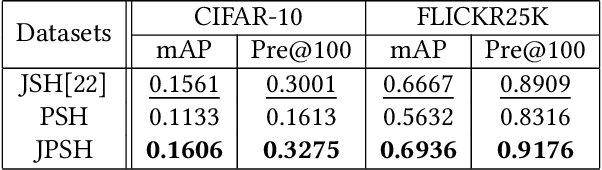
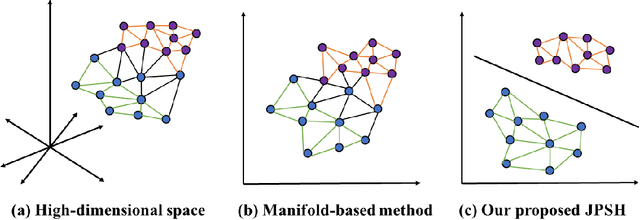
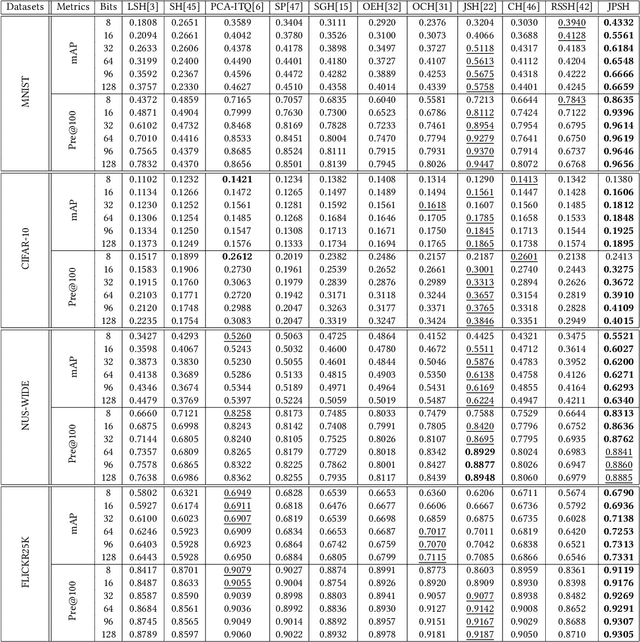
Unsupervised hashing has attracted much attention for binary representation learning due to the requirement of economical storage and efficiency of binary codes. It aims to encode high-dimensional features in the Hamming space with similarity preservation between instances. However, most existing methods learn hash functions in manifold-based approaches. Those methods capture the local geometric structures (i.e., pairwise relationships) of data, and lack satisfactory performance in dealing with real-world scenarios that produce similar features (e.g. color and shape) with different semantic information. To address this challenge, in this work, we propose an effective unsupervised method, namely Jointly Personalized Sparse Hashing (JPSH), for binary representation learning. To be specific, firstly, we propose a novel personalized hashing module, i.e., Personalized Sparse Hashing (PSH). Different personalized subspaces are constructed to reflect category-specific attributes for different clusters, adaptively mapping instances within the same cluster to the same Hamming space. In addition, we deploy sparse constraints for different personalized subspaces to select important features. We also collect the strengths of the other clusters to build the PSH module with avoiding over-fitting. Then, to simultaneously preserve semantic and pairwise similarities in our JPSH, we incorporate the PSH and manifold-based hash learning into the seamless formulation. As such, JPSH not only distinguishes the instances from different clusters, but also preserves local neighborhood structures within the cluster. Finally, an alternating optimization algorithm is adopted to iteratively capture analytical solutions of the JPSH model. Extensive experiments on four benchmark datasets verify that the JPSH outperforms several hashing algorithms on the similarity search task.
Video-based Cross-modal Auxiliary Network for Multimodal Sentiment Analysis
Aug 30, 2022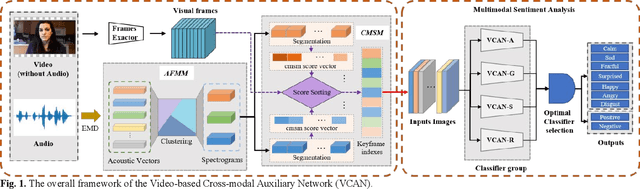
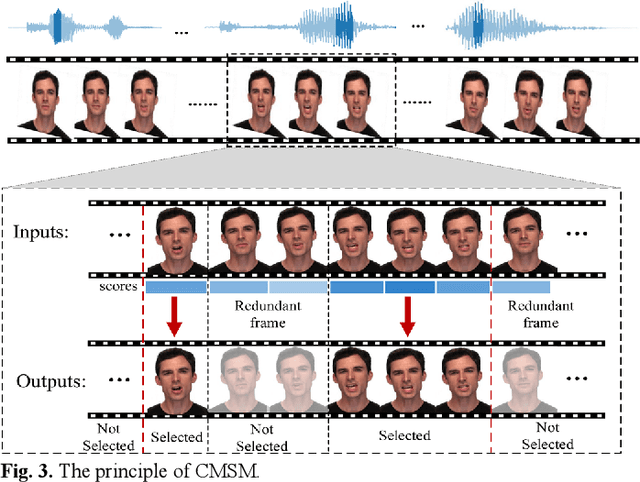
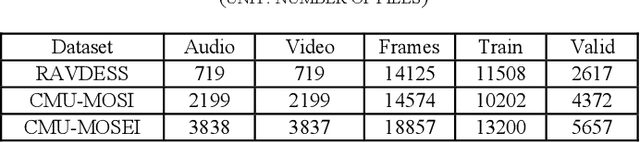
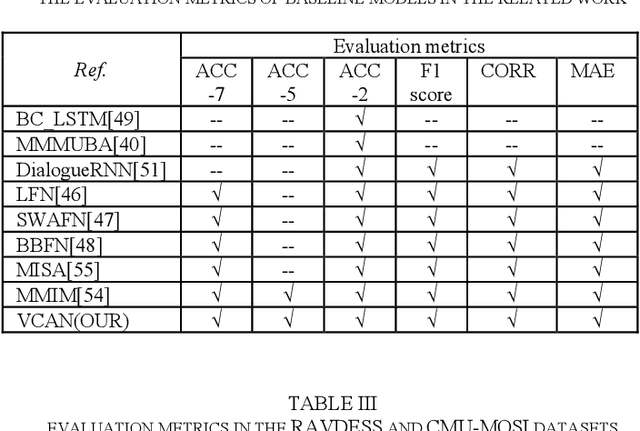
Multimodal sentiment analysis has a wide range of applications due to its information complementarity in multimodal interactions. Previous works focus more on investigating efficient joint representations, but they rarely consider the insufficient unimodal features extraction and data redundancy of multimodal fusion. In this paper, a Video-based Cross-modal Auxiliary Network (VCAN) is proposed, which is comprised of an audio features map module and a cross-modal selection module. The first module is designed to substantially increase feature diversity in audio feature extraction, aiming to improve classification accuracy by providing more comprehensive acoustic representations. To empower the model to handle redundant visual features, the second module is addressed to efficiently filter the redundant visual frames during integrating audiovisual data. Moreover, a classifier group consisting of several image classification networks is introduced to predict sentiment polarities and emotion categories. Extensive experimental results on RAVDESS, CMU-MOSI, and CMU-MOSEI benchmarks indicate that VCAN is significantly superior to the state-of-the-art methods for improving the classification accuracy of multimodal sentiment analysis.